

여러 벤더 사의 클라우드 환경을 구성하는 사례가 많아지면서 자연스럽게 다기종의 DB들 간 이동 사례가 늘고 있습니다.
특히 AWS RDS에 저장된 데이터를 강력한 분석 기능을 가진 GCP bigQuery에서 분석하고자 하는 수요가 많아지는데요.
이번 포스팅에서는 AWS의 RDB Service인 RDS의 데이터를 GCP의 Data analytics service인 bigQuery에서 분석할 수 있는 방법을 알아보겠습니다.
방법 1. bigQuery의 Federated query 기능을 사용하는 방법

첫번째 방법은 RDS의 데이터를 GCP의 CloudSQL로 옮긴 뒤 bigQuery의 "Federated query" 기능을 사용하는 방법입니다.
Federated query는 bigQuery의 스토리지 밖에 존재하는 데이터에서 쿼리를 바로 실행할 수 있는 기능입니다.
bigQuery의 federated query는 현재 Cloud storage와 CloudSQL를 지원하고 있습니다.
본 포스팅에서는 RDS Mysql 데이터 전제로 진행하겠습니다.

1. AWS DMS로 Migration 실행
첫 번째 작업은 RDS를 CloudSQL과 연동시키는 작업입니다.
연동 작업에는 RDS와 CloudSQL 간 CDC(Capture Data Change)를 지원하는 AWS의 DMS(Data Migration Service)를 사용하겠습니다.
본격적으로 작업을 진행하기 전에 RDS의 파라미터 그룹에서 gtid 관련 옵션을 "ON"으로 설정합니다.
MySQL은 gtid 옵션이 활성화되어 있어야 트랜잭션 당 id 를 부여받아 CDC가 가능하기 때문에 해당 옵션을 on해주어 CDC가 가능하게 해줍시다.

옵션을 설정했다면 이제 DMS를 사용한 CDC를 진행할 수 있습니다.
DMS를 AWS 콘솔에서 검색해 Data Migration Service로 접근합니다.

그리고 "복제 인스턴스"를 클릭해 마이그레이션을 수행할 인스턴스를 생성합니다.
이후 DMS 대시보드에서 옮길 데이터가 존재하는 RDS와, 데이터를 받을 CloudSQL를 엔드포인트로 생성합니다.
엔드포인트를 생성하고 나서 복제 인스턴스에서 각 엔드포인트와 통신할 수 있는지 테스트합니다.
테스트는 엔드포인트 -> 작업 -> 테스트 실행으로 시작할 수 있습니다.

테스트를 모두 통과했다면 "데이터베이스 마이그레이션 태스크" 를 클릭해 태스크를 생성합니다.
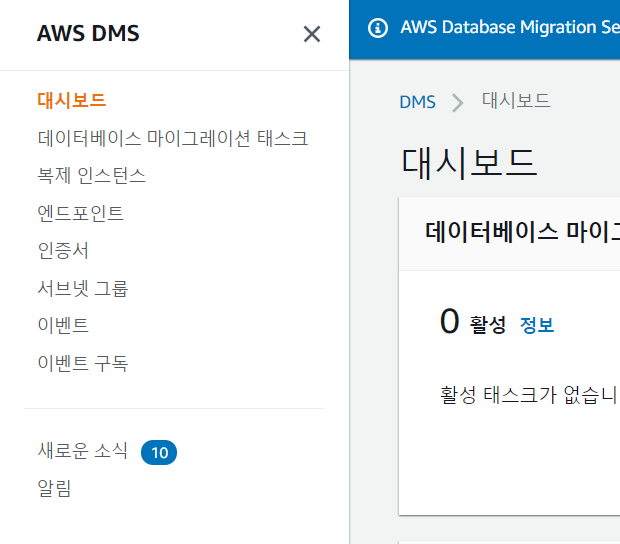
이후 "태스크 생성"을 클릭해 마이그레이션 태스크를 생성합니다.
소스 데이터베이스 엔드포인트 : RDS(생성한 rds instance 엔드포인트)
대상 데이터베이스 엔드포인트 : CloudSQL(생성한 cloudsql 엔드포인트)
마이그레이션 유형 : 기존 데이터 마이그레이션 및 지속적인 변경 사항 복제 -> 지속적인 변경 사항 복제가 CDC입니다.

태스크를 생성했다면 이제 마이그레이션을 시작해 데이터를 옮길 수 있습니다.
DMS의 마이그레이션 작업을 시작하면 데이터가 CloudSQL로 이동한 것을 확인할 수 있습니다.
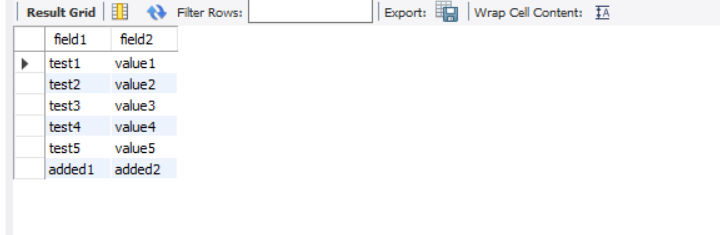
이제 CloudSQL 측에서 데이터가 정상적으로 연동되고 있는지 확인합니다.
CloudSQL에서 RDS의 기본 데이터(test,value)와 마이그레이션 후 추가한 열(added)까지 모두 반영되는지 확인해야 합니다.
2. bigQuery에서 federated query 사용
앞선 작업을 통해 AWS RDS와 GCP CloudSQL를 연동하는데 성공했습니다.
이제 RDS와 연동된 CloudSQL의 데이터를 그대로 bigQuery에서 분석해보겠습니다.
GCP 콘솔에서 bigQuery를 클릭한 뒤 "ADD DATA" -> "External data source" 순으로 클릭합니다.

이후 나타나는 External data source 페이지에서 아래와 같이 커넥션 정보를 입력합니다.
Connection type : CloudSQL - MySQL
Connction ID : ConnectionID (CloudSQL 대시보드에서 확인 가능)
Connection location : Seoul (원하는 region 지정)
Cloud SQL instance ID : project:location:instanceId (instanceId는 생성한 CloudSQL의 이름)
Database name : bigQuery가 분석할 CloudSQL의 데이터베이스 이름
Username : testuser
password : ****

CloudSQL의 Connection name은 아래와 같이 대시보드에서 바로 확인할 수 있습니다.

"Create Connection" 버튼을 클릭하면 CloudSQL을 외부 데이터 소스로 추가합니다.
이후 bigQuery 대시보드의 "External connections"의 하위 목록에 CloudSQL 데이터베이스가 추가된 것을 볼 수 있습니다.

이제 External connection으로 추가된 CloudSQL 데이터를 bigQuery에서 바로 분석할 수 있습니다.
쿼리 구문은 아래와 같이 "EXTERNAL_QUERY" 를 사용해야 하는 점을 제외하고는 기존 bigQuery 문법과 동일하게 사용할 수 있습니다.

"EXTERNAL_QUERY"를 붙이기 번거롭거나, View를 사용해 특정 칼럼만 조회하고 싶다면 쿼리 결과를 바탕으로 View를 생성할 수도 있습니다.

단 Federated query 기능에는 몇 가지 제한사항이 존재합니다.
우선 Federated query를 사용한 쿼리는 "Order by"를 사용한 경우에도 순서를 보장하지 않습니다.

Federated query는 CloudSQL의 쿼리 결과를 bigQuery로 다시 불러오는 구조이기 때문에 쿼리 속도가 느리다는 단점도 존재합니다.
그 외에 지원되지 않는 유형 등의 제한 사항은 아래와 같습니다.

방법 2. Datafusion을 사용한 Migration 방법

두번째 방법은 GCP의 Cloud Data Fusion 서비스를 사용하는 방법입니다.
Cloud Data fusion은 GCP의 Fully-managed 데이터 통합 서비스로 다양한 데이터 파이프라인과 ETL 작업을 하나의 Dashboard에서 작업할 수 있는 편리한 서비스입니다.
이번 시나리오에서는 Data fusion이 제공하는 기능 중 지속적 데이터 복제 기능인 "Replication" 기능을 사용합니다.
1. Data fusion 인스턴스 생성 및 설정
첫 번째로 Data fusion 인스턴스를 생성하도록 하겠습니다.
다른 GCP 서비스와 동일하게 원하는 이름과 Region을 설정합니다.
한 가지 특별한 점은 생성 페이지의 "ADD ACCELERATORS" 버튼을 클릭해 "Replication" feature를 체크해줘야 한다는 것입니다.
이 작업을 누락하면 Data fusion 대쉬보드에서 Replication 관련 기능을 사용할 수 없습니다.

인스턴스를 생성했다면 View Instance를 클릭해 대쉬보드로 진입합니다.
Data fusion은 Plugin을 설치하는 방법으로 다양한 기종의 Data source간 통합을 지원합니다.
대쉬보드의 우측 상단 "HUB"를 클릭해 이번 시나리오에 필요한 MySQL Plugin을 설치하겠습니다.
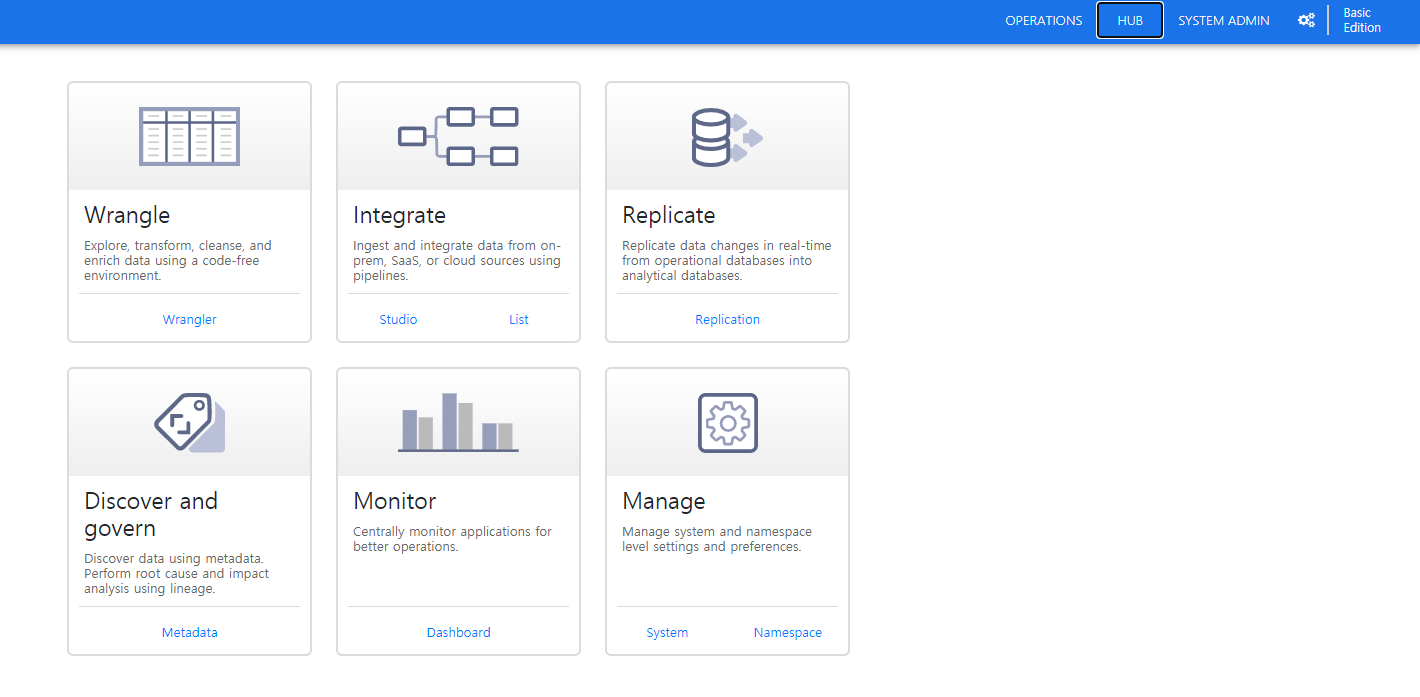
HUB로 진입하면 Data fusion이 지원하는 각종 Plugin을 볼 수 있습니다.
검색창에 Mysql을 검색해 MySQL Plugin을 설치합니다.

plugin 설치는 jar 파일을 내려받은 뒤 Deploy 하는 방법으로 진행됩니다.
Plugin을 정상적으로 설치했다면 좌측 상단의 네비게이션 메뉴를 누른 뒤 "Replication"으로 진입합니다.
Replication 페이지에서 우측 상단의 초록색 플러스 버튼을 누르면 Pipeline을 생성할 수 있습니다.
첫번 째로 Pipeline을 구별할 이름을 지정합니다.

다음으로 Source의 정보를 입력할 수 있습니다.
RDS MySQL을 Source로 사용할 것이므로 MySQL을 선택한 뒤 Host 등 RDS의 정보를 입력합니다.
JDBC Plugin name은 미리 생성한 MySQL plugin을 선택합니다.

Datafusion이 RDS와 통신에 성공했다면 다음과 같이 선택한 DB의 테이블 정보가 나타납니다.
여기서 Replication을 원하는 테이블을 선택할 수 있고 CRUD 중 어떤 작업만을 반영할지 선택할 수도 있습니다.

다음은 Destination이 될 bigQuery에 대한 설정입니다. 모두 기본값으로 하고 Next를 누르겠습니다.

그 외에 Replication에 대한 설정을 입력하고 나면 최종적으로 생성될 Pipeline을 리뷰할 수 있는 페이지로 진입합니다.
여기서 이상이 없다면 DEPLOY REPLICATION PIPELINE을 클릭해 작업을 시작할 수 있습니다.

2. Data fusion Pipeline 작업
Pipeline 대쉬보드로 이동합니다. 우측 상단의 Start 버튼을 눌러 작업을 시작합니다.
옆의 Logs 버튼을 누르면 상세한 작업 진행 상황을 볼 수 있습니다.

Log에서 데이터가 들어오고 bigQuery에 쓰여지는 상황을 확인할 수 있습니다.

bigQuery에서 선택한 Database가 Dataset으로 들어온 것을 확인할 수 있습니다.
Dataset 안에는 Replication 작업 생성 때 지정한 Table이 생성되어 있습니다.
Table을 클릭해 데이터가 정상적으로 들어온 것을 확인합니다.

이번 포스팅에서 RDS의 데이터를 bigQuery에서 분석할 수 있는 2가지 방법을 소개해드렸습니다.
제가 소개해드린 방법 말고도 다양한 방법이 있겠지만, 개인적으로 유용하다고 생각하는 방법을 선정해봤습니다.
이 포스팅을 보시는 분들이 RDS의 데이터를 마이그레이션하는데 도움되는 정보를 가져가셨으면 합니다.
'GCP' 카테고리의 다른 글
| GCP Instance Metadata를 100% 활용하는 방법 (0) | 2021.04.27 |
|---|---|
| AWS와 GCP간 HA (High-Availability) VPN 연결 구성하기 (2) | 2021.03.30 |
| GCP Professional Data Engineer Certificate 취득기 (3) | 2021.02.02 |
| GCP Cloud monitoring으로 편리하게 Network monitoring을 해보자 (0) | 2021.01.23 |
| GCP Dataflow SQL로 쉽게 Streaming Data를 처리하는 Data pipeline 구성하기 (0) | 2021.01.09 |