코딩 한 줄 필요 없는 Machine Learning - GCP AutoML Tables로 쉽게 ML 하기

머신러닝이라는 키워드를 들어보지 않은 개발자는 없을 것이다.
그만큼 현재 머신러닝은 우리의 가까이에 위치한 기술이다.
과거의 데이터를 가지고 미래를 Predict할 수 있다는 점에서 이 매력적인 기술은 많은 이들이 배우고자 하였지만,
Machine Learning을 실전에 사용하기 위해 필요한 방대한 지식은 많은 이들이 이러한 기술의 혜택을 받기가 어려운 요소가 되었다.
하지만 Google Cloud Platform은 머신러닝 기술에 장기간 투자해온 Google의 기술력을 바탕으로 누구나 손쉽게 첨단 머신러닝 기술의 혜택을 받을 수 있게 해주었다.
Auto ML 이라는 GCP의 Machine Learning 제품군은 화면인식, 음성인식, 예측 등 다양한 머신 러닝 기술을 코딩 한 줄 없이 적용할 수 있도록 나온 서비스이다.
본 글에서는 Auto ML의 제품군 중 정형 데이터를 바탕으로 예측 모델을 생성해주는 Auto ML Tables에 대해서 알아보고자 한다.
쉬운 이해를 위해 필자가 직접 모델을 생성하고 예측을 수행하는 과정을 시나리오 베이스로 알아보자.

0. 목표 설정
호텔 업계에서는 날이 갈수록 고객의 호텔 예약 취소로 인한 노쇼 행위로 피해가 커져 골머리를 앓고 있다.
하지만 고객의 취소 여부를 미리 예측할 수 있다면?
취소 확률에 따라 고객 대응 프로세스를 다르게 하는 등 리스크 관리를 용이하게 할 수 있을 것이다.
이를 위해 Hotel booking에 대한 n년치의 데이터를 토대로 고객 정보가 주어지면 booking cancel 확률을 예측할 수 있는 모델을 만들어보자.
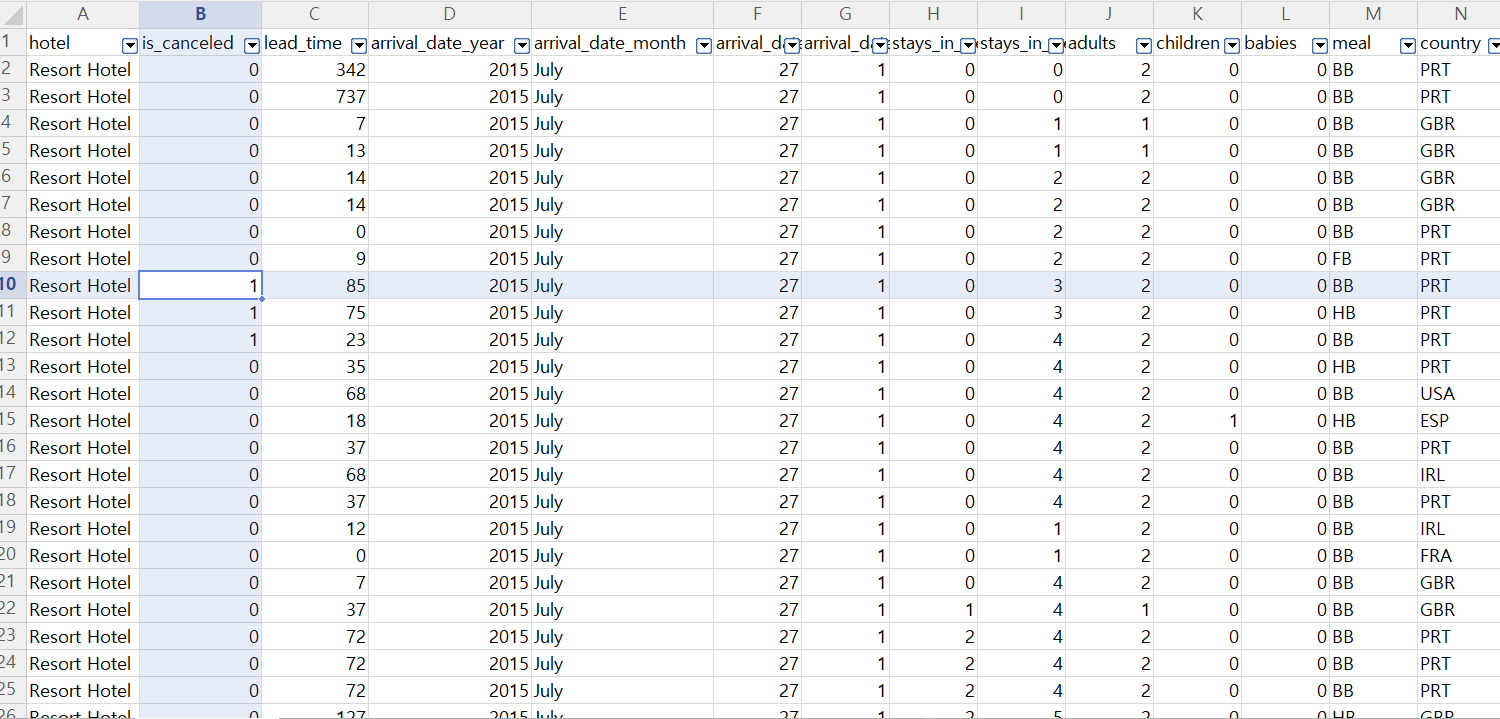
Kaggle에서 고객의 국가,가족 구성원, 특별 요청 여부 등 다양한 컬럼으로 이루어진 약 10만건의 Hotel booking 데이터를 구했다.
이제 이 데이터를 토대로 고객의 호텔 예약 취소 여부를 예측할 수 있는 모델을 만들어 보자.
1. 데이터셋 만들기
Auto ML Tables는 과거의 데이터를 토대로 미래를 예측할 수 있게 해준다.
특히 여기서 사용하는 '데이터'란 제품 이름에서 알 수 있듯이 칼럼 형식으로 스키마가 존재하는 정형 데이터를 말한다.
Auto ML Tables는 bigQuery, Google Cloud Storage, Web console의 3가지 방법으로 위의 정형 데이터를 업로드할 수 있다.
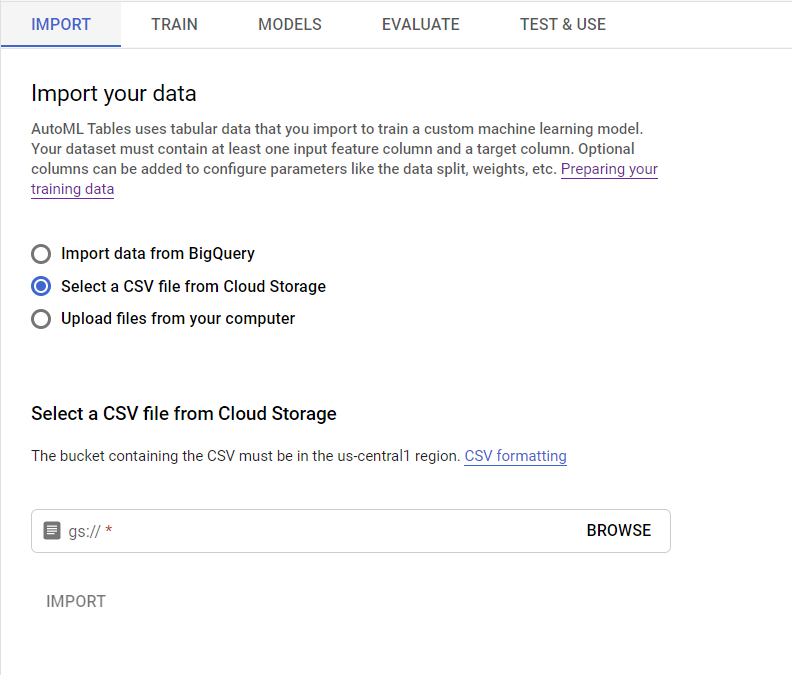
경험상 Machine Learning을 수행하는데 있어 가장 시간이 오래 걸리고 중요한 작업은 훈련에 필요한 Data를 준비하는 것이었다.
왜냐하면 보통의 데이터들은 정제되지 않은 경우가 많고 학습에 필요한 요소와, 오히려 방해가 되는 요소가 혼재되어 있기 때문이다.
그래서 Auto ML Tables에서는 Data 준비 과정을 쉽게 할 수 있도록 Train에 들어가기 전에 Data를 Customize할 수 있는 기능을 제공한다.
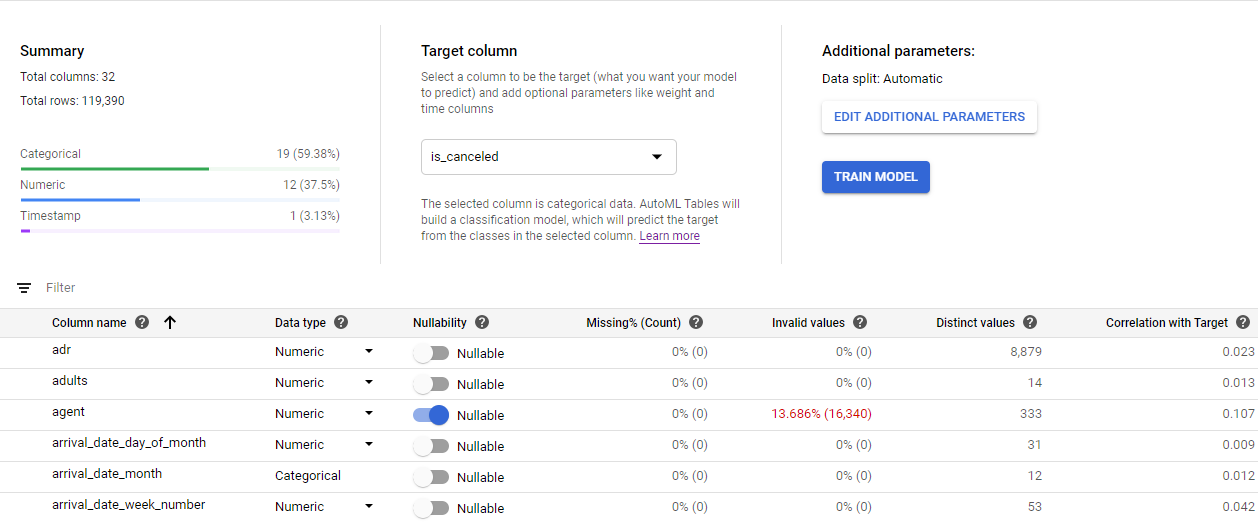
여기서 Import한 Data의 Type, Nullabillity, invalid value 등 구성을 볼 수 있고 Custom할 수 있다.
물론 AutoML Tables에서 제공하는 Data Custom 기능도 충분하지만,
더욱 높은 수준의 Data ETL이 필요하다면 Data prep이나 Data flow를 이용하면 된다.
여기서 가장 중요한 과정은 Target column을 설정하는 것으로 Data의 Column 중 예측하고자 하는 요소를 정하는 것이다.
본 과정에서는 호텔 예약의 취소 여부를 나타내는 Is_canceled 칼럼을 Target column으로 지정했다.
모든 설정을 끝마쳤다면 Train model 버튼을 눌러 학습을 시작하자.
2. 모델 학습시키기
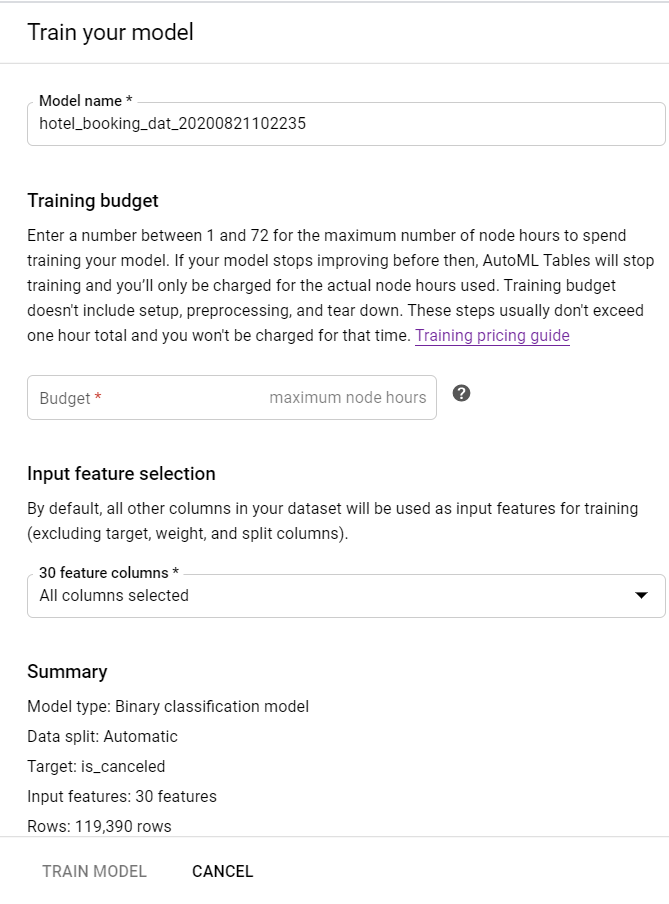
Train Model 버튼을 눌렀다면 오른쪽에 위와 같은 Panel이 생성된다.
여기서 모델을 학습하는데 동원될 Node의 개수와 학습에 포함할 Column을 설정할 수 있다.
여기서 정하는 Node의 개수가 많을수록 Training에 소요되는 시간은 짧아지겠지만,
대부분의 Cloud Service의 가격 정책이 그렇듯이 소요되는 금액 또한 높아지게 된다.

여기서 Train 버튼을 누르면 본격적으로 모델 학습에 진입하게 된다.
위의 경우에는 모델 학습에 4시간 정도가 걸린 것 같다.
학습이 완료되어 모델이 완성되면 GCP에 등록된 Email address로 알림이 온다.
3. 모델 평가하기
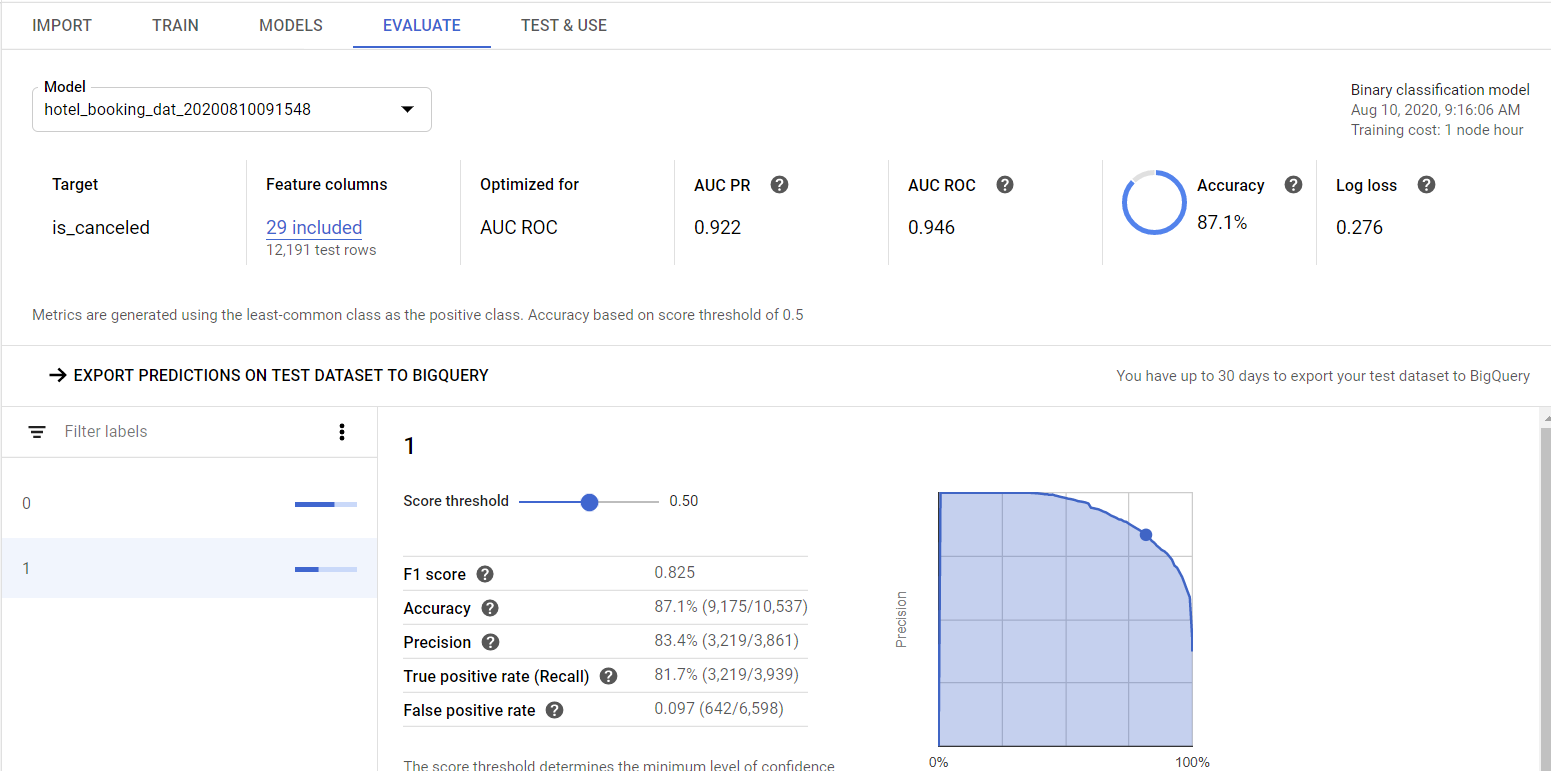
Model이 성공적으로 생성되었다면, 이제 생성된 Model이 적절한지 평가해야 한다.
AutoML Tables 에서는 Model을 평가할 수 있는 다양한 정보를 제공한다.
Evaluate 페이지에서 Model의 Accuracy같은 직관적인 정보부터 Confusion Matrix나 Feature Importance 같은 중요한 정보를 볼 수 있다.
여기서 생성한 Model의 예측 정확도는 87.1%로 나쁘지 않은 편인 것 같다.
중요한 점은 내가 Machine Learning 모델에 대한 아무런 설정을 하지 않았음에도
AutoML Tables에서 자동으로 두 가지의 정보를 분류할 수 있는 Binary Classification model을 생성했다는 점이다.
이렇게 AutoML Tables가 알아서 적절한 Model을 생성해주기 때문에 Machine Learning Model에 대한 아무런 지식 없이도 ML을 활용할 수 있다.
실제로 Document에서 보면 다양한 AutoML Tables는 몇개의 최신 Model을 동시에 학습시킨 뒤, 가장 적절한 결과를 내는 Model을 확정하는 방식이라고 한다.

위의 Confusion Matrix는 0과 1로 이루어진 두 가지 예측과 정답의 확률을 표시한 Matrix이다.
여기서 볼 수 있는 한 가지 재미있는 정보가 있다.
Feature Importance는 각 요소들이(Column들이) 예측에 얼마나 영향을 미치는 지 점수로 환산한 표이다.
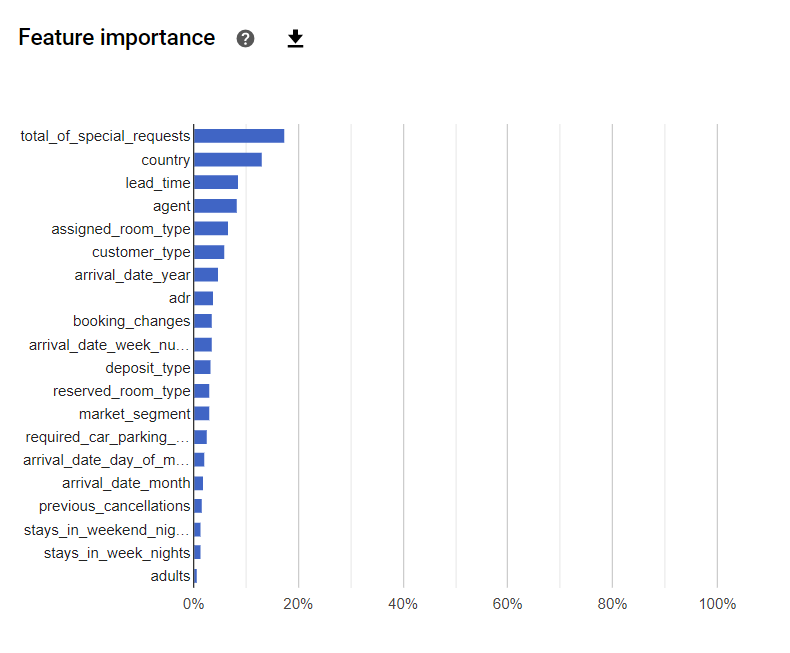
Feature Importance를 통해 total_of_special_requests와 country, lead_time Column이 높은 Importance를 가진다는 것을 알 수 있다.
즉 위의 세가지 요소들이 모델의 예측에 중대한 영향을 끼쳤다는 뜻이다.
실제로 몇몇 Data를 본 결과 특별 요청의 횟수가 많을 수록 예약 취소 확률이 현저하게 줄어든다는 것을 알 수 있었다.
고객의 출신 국가가 취소 확률에 유의미한 영향을 끼친다는 것도 주목할 만한 결과이다.
lead_time은 예약 시기와 실제로 호텔에 묵는 시기와의 차이를 나타낸 정보인데, 이 기간이 길수록 취소 확률도 높아지는 것으로 보인다.
4. 결론
AutoML Tables를 사용해보고 느낀 점은,
우선 Machine Learning을 수행하기 위해 처리해야 했던 수많은 절차를 Cloud 환경에서 자동으로 처리해 준다는 것이 편리하다는 것이었다.
실제로 필자는 ML에 대한 지식이 전무함에도 불구하고 위와 같이 Model을 토대로 예측을 진행할 수 있었다.
물론 이 Model이 적절한 지를 판단하는 데는 나름의 ML 지식이 필요할지도 모르겠지만
적당한 Data만 넣어주면 알아서 Model의 종류를 선별하고 예측을 진행해준다는 점에서 상당히 진보한 ML 서비스인 것을 알 수 있었다.
이 과정이 너무 빠르고 간단하게 진행되어 필자는 호텔의 취소 확률 예측 모델 말고도
고객 피드백을 바탕으로 문의사항의 중요도 판별, 여객기의 도착지연 여부 예측 모델도 진행해 보았다.

이렇게 코딩 한 줄 없이, ML에 대한 지식 하나 없이 단숨에 3개의 Model을 만들어낼 수 있음에 놀라웠다.
앞으로 이러한 AutoML 기술로 인해 Machine Learning이 더욱 친숙하고 가까워지리라 생각한다.