
gRPC는 Google에서 개발한 Opensource RPC 프레임워크입니다.
gRPC는 HTTP/2를 기반으로 동작하기 때문에 효율적으로 요청을 전달할 수 있으며, ProtoBuf를 이용해 데이터를 직렬화(Serialization)하기 때문에 적은 용량으로 데이터를 전송할 수 있다는 장점이 있습니다.
MSA 아키텍쳐가 보편화되어 효율적인 통신이 필요한 요즈음 많은 Application들이 위와 같은 장점을 가진 gRPC를 사용하고 있는데요.
하지만 Kubernetes 환경에서 이러한 gRPC의 특성들이 초래하는 예상치 못한 문제가 존재합니다.
이번 포스팅은 Kubernetes에서 gRPC 통신을 구성할시 발생할 수 있는 문제와 그 원인, 그리고 해결 방법에 대해서 알아보도록 하겠습니다.
1. Issue

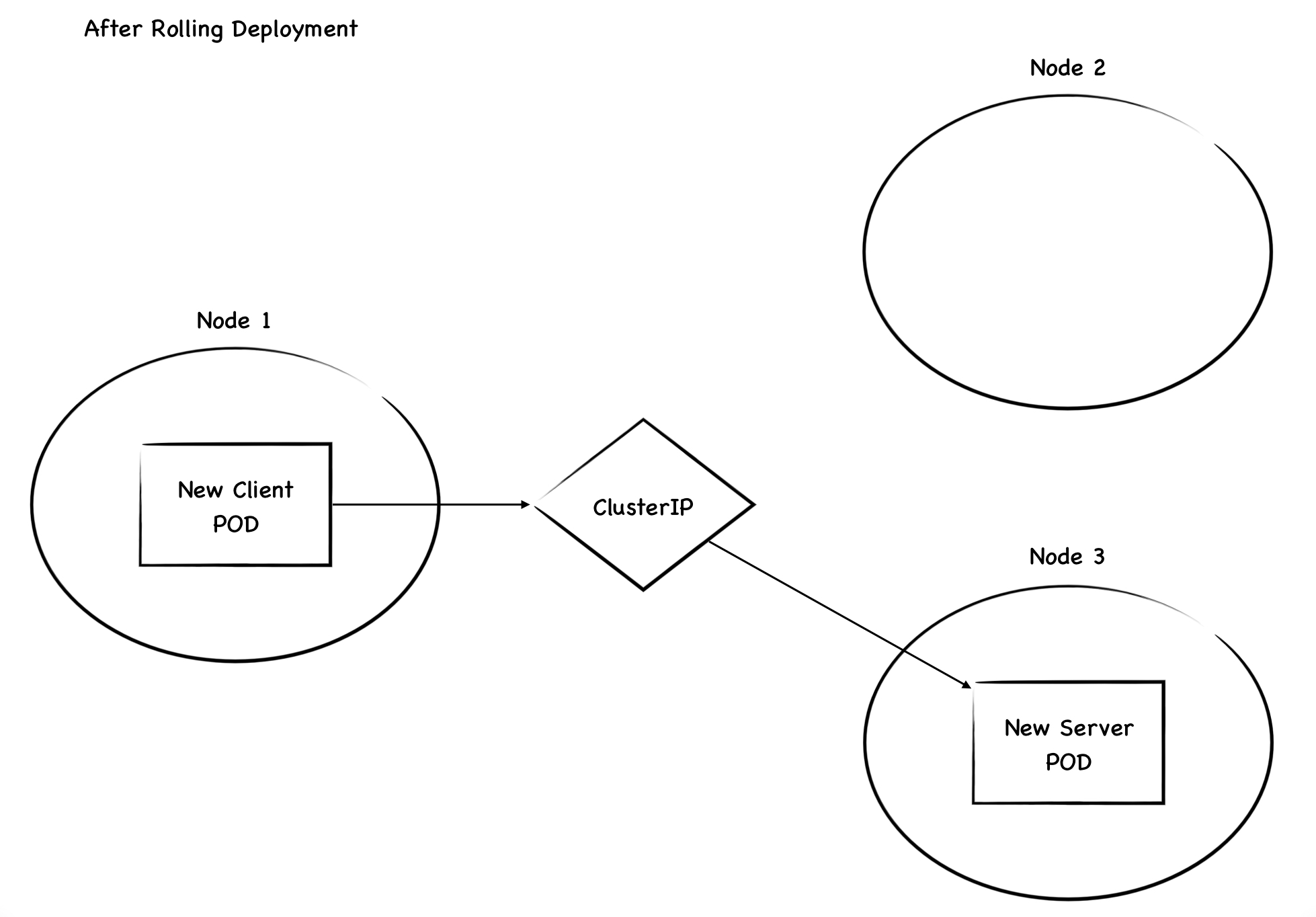
최초 이슈는 gRPC 기반의 Client와 Server 어플리케이션(이하 Client, Server)의 Rolling Deployment를 수행했을때 발견했습니다.
Client는 Server Pod로 향하는 ClusterIP를 Endpoint로 삼아 Request를 전송하고 있었으며, Rolling Deployment 중 리소스 부족으로 인해 Server Pod는 새 Node에 Scheduling된 상황이었습니다.
Rolling Deployment를 수행한 이후 Client, Server Pod 모두 Liveness, Readiness Probe를 통과해 Running 상태로 통신이 가능한 상태였습니다.
하지만 gRPC로 통신해야 하는 두 Pod들이 패킷을 주고받지 않아 Throughput이 배포 이후에도 전혀 늘어나지 않는 현상이 발생했습니다.
Client는 Metric상으로 Network Transfer(TX) 수치가 배포 전과 동일하며, Log상으로는 Server측으로 Request를 전송하지만 Connection 유지 시간인 10분 뒤 해당 Request가 Timeout되는 것이 관측되었습니다.
Server는 Metric상으로 Network Recieve(RX) 수치가 거의 늘어나지 않으며, Log상으로는 Client 측으로부터 오는 어떤 Request도 받지 못하는 것이 관측되었습니다.
위 현상은 약 10~30분 뒤 해소되었으며, 이후에는 정상적으로 패킷을 주고받는 것이 확인되었습니다.
2. Analyze
2-1. Issue Reprocuing
몇 번의 에러 재구현 결과 위 Issue는 아래와 같은 상황에서 발생한다는 것을 확인할 수 있었습니다.
- Client는 Server에게 gRPC로 Request를 전송
- Client의 Request는 ClusterIP를 사용해 Routing됨
- Client와 Server간 Connection이 형성된 상태에서 Server Pod가 새로 Deployment됨
- 새로 배포된 Server Pod는 기존과 다른 Node에 Scheduling됨
위 4개 조건이 충족된 상황에서 Server와 Client를 배포하면 어김없이 10~30분 가량의 통신 장애가 발생했으며, 이는 어떤 Kubernetes 클러스터에서도 구현 가능했습니다.
2-2. Root Cause
결과적으로 위 현상은 gRPC가 Long-lived Connection을 맺는 HTTP/2를 기반으로 통신하기 때문에 발생하는 Issue입니다.
HTTP/2는 Request마다 Connection을 맺는 HTTP/1과 달리, 하나의 Long-lived Connection을 맺어 해당 Connection으로 Request를 전송하는 Multiplexing을 사용합니다.
Multiplexing은 Connection 설정에 소요되는 Overhead를 줄일 수 있기에 효율적인 방법이지만, 문제는 해당 기능이 L4 Proxy를 매개로 전달될때 이슈가 될 여지가 존재한다는 것입니다.

gRPC의 Multiplexing 기능은 L4 Proxy를 통해 전달될 경우 위처럼 동일한 Destination에게만 패킷을 전달하게 됩니다.
그 이유는 L4 Proxy는 Layer 4 단의 정보만을 인지할 수 있기 때문에, Layer 7에서 이루어지는 Connection level의 전송 제어를 수행할 수 없기 때문입니다.
따라서 gRPC의 Long-lived Connection이 Kubernetes의 ClusterIP와 같은 L4 Proxy를 매개로 전달될 경우, Load balancing이 수행되지 않거나 이미 사라진 Destination을 향해 패킷을 전달하는 Issue가 발생하게 됩니다.
위 분석 결과를 종합하면 본 포스팅에서 발생한 Issue의 경우 아래와 같은 Timeline으로 정리할 수 있습니다.

1. T+0
Rolling Deployment가 수행되기 전 상태입니다.
Client와 Server 간의 최초 Connection이 ClusterIP를 매개로 라우팅되어 맺어집니다.
이후 Long-lived Connection을 맺은 Client는 ClusterIP의 개입 없이 Multiplexing 기능을 통해 Request 패킷을 전송합니다.

2. T+1
Rolling Deployment가 수행된 직후 상태입니다.
새 Server Pod는 Node의 자원 부족으로 인해 Node 3가 Cluster에 참여할때까지 스케쥴링되지 않으며, 때문에 새 Client Pod가 먼저 배포됩니다.
새 Client Pod는 T+0과 동일하게 ClusterIP를 통해 HTTP/2 Connection을 맺은 후 패킷을 Destination으로 전송합니다.

3. T+2
Node 3가 정상적으로 Cluster에 join한 뒤, 새 Server Pod가 Node 3에 Scheduling되어 배포가 완료된 상태입니다.
아직 맺어진 HTTP/2 Connection의 만료 시간이 도달하지 않았기 때문에 Client는 사라진 기존 Server Pod로 계속하여 패킷을 전달하려 합니다.
Node 2에는 패킷을 받을 Pod가 존재하지 않기 때문에 해당 패킷은 Drop됩니다.
따라서 해당 시간부터 Client와 Server는 통신이 불가능한 상태가 되며, 장애가 발생하게 됩니다.

4. T+3
기존 Connection이 끊어지고 ClusterIP를 통해 새 Server Pod로 새 Connection이 맺어진 상태입니다.
이 시간부터 Client와 Server가 통신이 가능해지며 장애가 해소됩니다.
3. Solutions
위와 같은 issue를 해결하는 방법은 크게 두 가지로 나눌 수 있습니다.
1. Client side에서 Load balancing 구현
2. L4 Proxy가 아닌 L7 Proxy를 경유하도록 구성
3-1. Client Side Load Balancing
Client에서 자체적으로 Load Balancing을 구현해 배포 중에도 Subchannel을 통해 새 Server Pod로 즉시 패킷을 전달하는 방법입니다.

이 방법을 사용하면 여러 Server가 존재하는 상태에서도 패킷을 단일한 Destination으로만 전송하지 않기 때문에, 새 Connection이 맺어지기까지 발생하는 Downtime을 방지할 수 있습니다.
단 Client가 Server의 IP Address를 인지해야 가능한 방법이기 때문에 ClusterIP를 Headless Service로 변경해야 한다는 제약사항이 존재합니다.
Pros : Client단에서 패킷을 제어하기 때문에 적은 Overhead로 높은 성능을 기대할 수 있음
Cons : 자체적인 Load Balancing 구현 및 Headless Service 도입으로 인한 복잡도 증가
3-2. L7 Proxy Implementation
통신을 위해 경유하던 기존 L4 Proxy를 L7 Proxy로 변경하여 gRPC의 패킷 전달을 정상화하는 방법입니다.
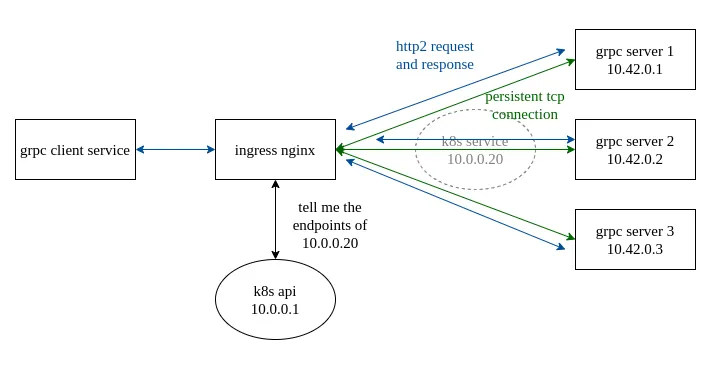
이 방법은 Client side Load Balancing과 달리 Application의 로직을 변경하지 않고 Proxy단에서 Issue를 해결할 수 있습니다.
Layer 4 정보만을 인지해 gRPC 통신을 제어하지 못하던 ClusterIP 대신 L7 Proxy를 경유하도록 변경해 패킷이 정상적으로 전달될 수 있도록 구성할 수 있습니다.
현재 Kubernetes에서 구현할 수 있는 L7 Proxy는 Istio, Linkerd와 같은 Service Mesh와 Nginx, AWS ALB와 같은 Ingress object를 사용할 수 있습니다.
Pros : Client의 로직 변경 없이 Network 구성의 변경 만으로 구현 가능
Cons : L7 Proxy를 경유하므로 패킷 전송에 Overhead 존재
4. 마무리
지금까지 gRPC를 사용하는 Application이 Kubernetes 환경에서 통신할 시 발생할 수 있는 문제와 그 원인, 그리고 해결 방법을 알아봤습니다.
gRPC는 하나의 Long-lived Connection을 맺어 패킷을 전달하는 HTTP/2를 기반으로 통신하기 때문에, L4 Proxy인 ClusterIP를 경유해 통신할 경우 정상적으로 패킷이 전달되지 않을 수 있음을 확인했습니다.
따라서 Rolling deployment 등의 원래 Destination이 소실되는 경우 다시 Connection을 맺을 때까지 Downtime이 발생할 수 있었습니다.
이에 대한 해결방법으로는 Client side Load Balancing을 구현하거나 L4가 아닌 L7 Proxy를 경유하도록 변경하는 방법이 존재합니다.
두 방법은 각각의 장단점이 존재하므로, 현재 상황과 환경에 유리하게 작용하는 방법을 선택해 구현할 수 있습니다.
이 포스팅을 읽으신 분들이 동일한 이슈를 쉽게 해결할 수 있기를 바랍니다.
'Devops' 카테고리의 다른 글
| Terraform을 GitOps 방식으로 사용하기 위한 도구 선택하기(With TACOS) (0) | 2024.01.27 |
|---|---|
| Kubernetes 환경에서 발생하는 DNS Query Failed 이슈와 NodeLocal DNSCache를 이용한 해결 (5) | 2023.12.30 |
| EKS Kubernetes의 롤링 업데이트 시 일시적인 500 에러의 원인과 해결 (1) | 2023.11.30 |
| Kubecost로 Kubernetes 환경의 FinOps를 구현해보자 (0) | 2023.11.29 |
| Clean Code를 구현하기 위해 Sonarqube로 정적 코드 분석을 해보자 (2) | 2023.10.28 |