

언젠가부터 빅데이터에 대한 언급이 많아지고 있습니다.
거대한 데이터를 수집하고 분석하는 작업에 대한 수요가 늘면서 이를 수행할 수 있는 툴들이 하나둘씩 나타나고 있습니다.
가령 요즘은 빅쿼리, 데이터브릭, 스노우플레이크와 같은 SaaS형태의 종합 빅데이터 분석도구가 수요를 충족하려 하고 있습니다.
하지만 이런 최근의 SaaS 툴 이전에 빅데이터 분석의 원조격으로 불리는 시스템이 존재했습니다.
그것이 바로 Apache hadoop 입니다.
Apache hadoop은 분산 환경에서 빅 데이터를 처리하기 위한 Open-source 프레임워크입니다.
그리고 Apache hadoop을 중심으로 HDFS,YARN 및 연관 도구들을 일컬어 Apache Hadoop Ecosystem(아파치 하둡 생태계)라고 합니다.
아파치 하둡 생태계는 빅데이터 분석에 뛰어난 면을 보여주지만, 통합된 모니터링 시스템이 부재하기 때문에 메트릭을 이용한 관리가 힘들다는 단점이 있습니다.
그래서 이번 포스팅에서는 프로메테우스와 그라파나를 이용해 하둡 생태계 클러스터를 모니터링할 수 있는 시스템을 구축해보고자 합니다.
하둡 클러스터는 GCP의 Managed Hadoop Service인 Dataproc을 이용해서 구축해보겠습니다.
1. Dataproc 클러스터 구축
기존의 오픈소스 Hadoop에 Spark+Hive 클러스터를 구축하려면 HDFS 설정, DB 구축, 메타스토어 구축 등등.. 해야 할 일이 많았지만 이제는 GCP의 Dataproc같은 서비스로 클릭 몇번만에 클러스터를 구성할 수 있습니다.
추가적으로 GCP Dataproc을 이용할 경우 하둡 생태계의 다양한 컴포넌트들(Zookeeper, Druid 등..)을 클릭 몇 번만으로 설치할 수 있고 Google에서 제공하는 스크립트들을 사용해 써드 파티 툴과 연계하기도 쉽습니다. Google Cloud Platform의 Cloud monitoring과 연동되어 별다른 설정 없이도 다양한 메트릭을 수집하고 확인할 수도 있습니다.
하지만 Dataproc의 Cloud monitoring에서 Job이나 인스턴스, YARN 단에서의 메트릭을 볼 순 있지만 더 깊은 JVM 메모리 단의 메트릭은 확인할 수 없어 더 상세한 진단에는 한계가 있다는 단점이 있습니다.
그럼으로 GCP Dataproc 클러스터에 Prometheus+Grafana를 추가적으로 구성해 부족한 가시성을 채워보겠습니다.
우선 GCP Dataproc 클러스터를 구축해보겠습니다. 클러스터 구축에 대한 튜토리얼 가이드는 GCP 공식 Document에서도 볼 수 있습니다.
1-1 Requirements
Dataproc 클러스터를 구성하기 전에 필요한 리소스들을 생성하고 구성을 변경해보겠습니다.
가장 먼저 GCP의 RDBMS 서비스인 CloudSQL을 메타스토어로 사용하기 위해 CloudShell에서 CloudSQL Admin API를 enable합니다.
|
1
|
gcloud services enable dataproc.googleapis.com sqladmin.googleapis.com
|
cs |
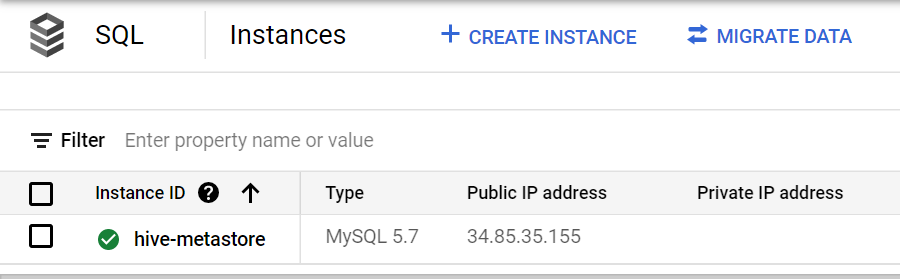
API를 enable했다면 CloudSQL 인스턴스를 하나 생성합니다. ZONE 값은 생성을 원하는 Zone으로 지정합니다. Dataproc 클러스터를 생성할 Zone과 동일하면 성능 상 이점이 있습니다.
|
1
2
3
4
|
gcloud sql instances create hive-metastore \
--database-version="MYSQL_5_7" \
--activation-policy=ALWAYS \
--zone ${ZONE}
|
cs |
Dataproc의 Datawarehouse로 사용할 GCS Bucket을 하나 생성합니다. 앞으로 Dataproc 클러스터에서 처리할 데이터는 모두 이 버켓 안에 담게 됩니다.
|
1
2
|
export PROJECT=$(gcloud info --format='value(config.project)')
gsutil mb -l ${REGION} gs://${PROJECT}-warehouse
|
cs |

이렇게 메타스토어 CloudSQL 인스턴스와 Datawarehouse GCS 버켓을 생성하면 클러스터 생성 준비는 끝입니다.
생성한 메타스토어와 Datawarehouse 버켓은 다른 Dataproc 클러스터들과 공유가 가능하기 때문에 차후 다른 클러스터를 생성하더라도 CloudSQL 인스턴스와 GCS 버켓을 또 생성할 필요는 없습니다.
1-2 Dataproc 클러스터 생성
Dataproc 클러스터 생성 자체는 커맨드로 작업하면 간단하겠지만 더 자세히 알아보기 위해 Web Console UI로 진행해보겠습니다.
Dataproc 생성 페이지로 진입해 Set up cluster 항목에서 클러스터의 이름, 로케이션, 타입, 스케일링 타입 등을 원하는 대로 지정합니다.
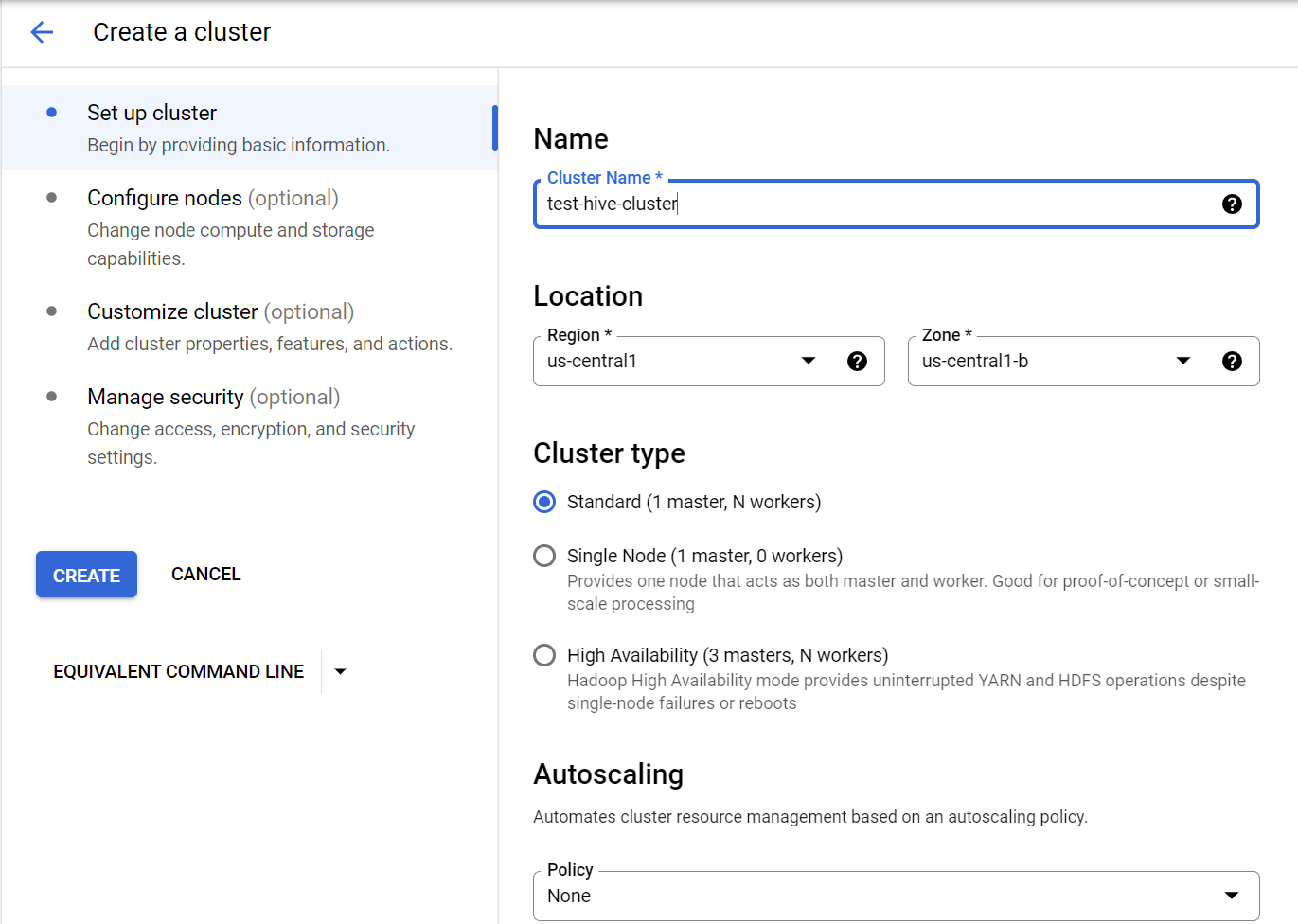
Configure nodes 항목에선 노드의 스펙 및 관련 옵션을 지정할 수 있습니다. 아래의 Totla YARN usage 항목을 참고해 얼만큼의 YARN 리소스를 사용할 수 있는지 확인할 수 있습니다.

Customize cluster 항목에서 클러스터의 속성 및 메타데이터 값을 지정할 수 있습니다. 속성을 지정해 클러스터의 Configuration을 변경하거나 Initialization action을 이용해 생성 시 동작할 스크립트를 돌릴 수도 있습니다.
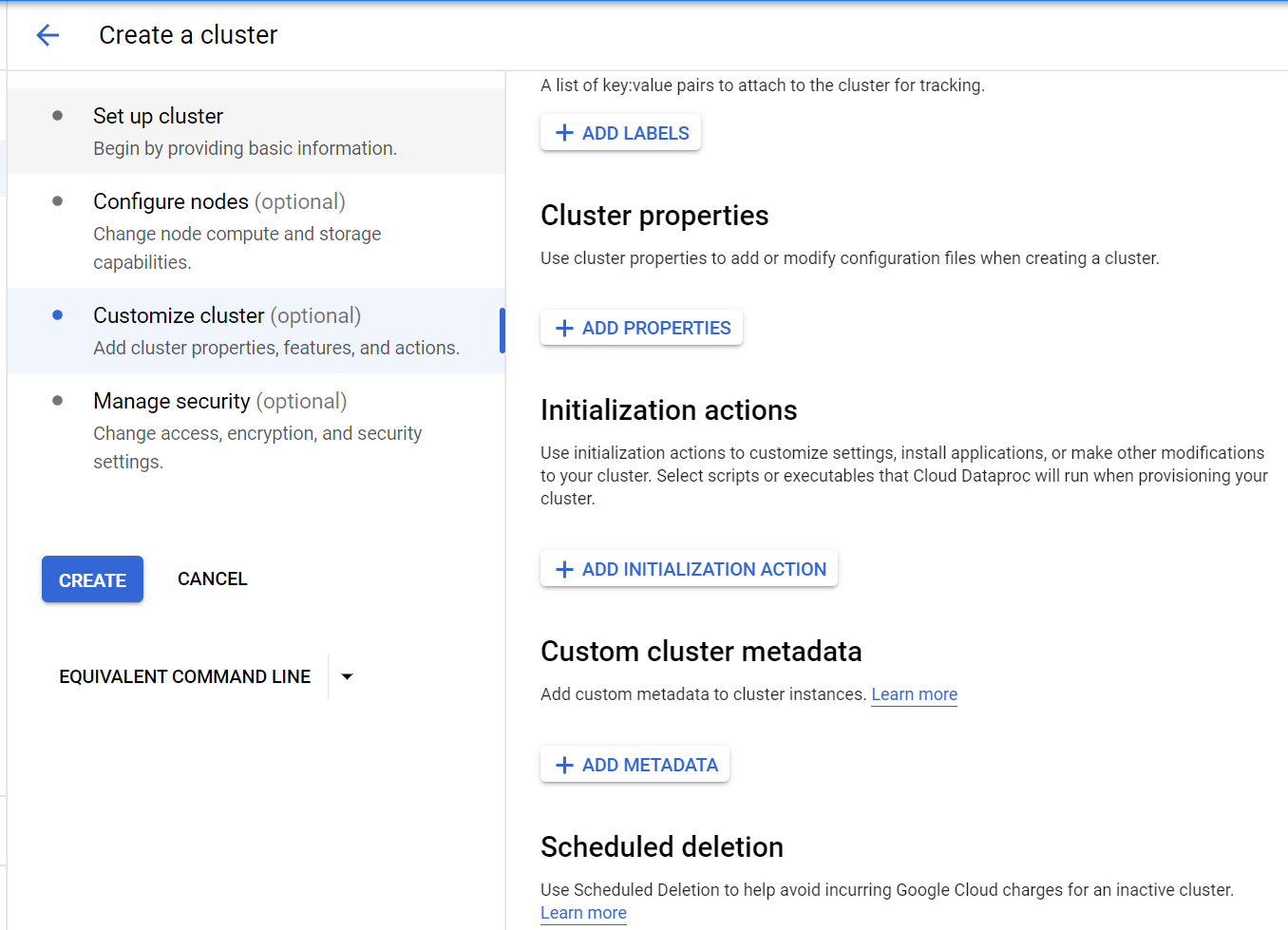
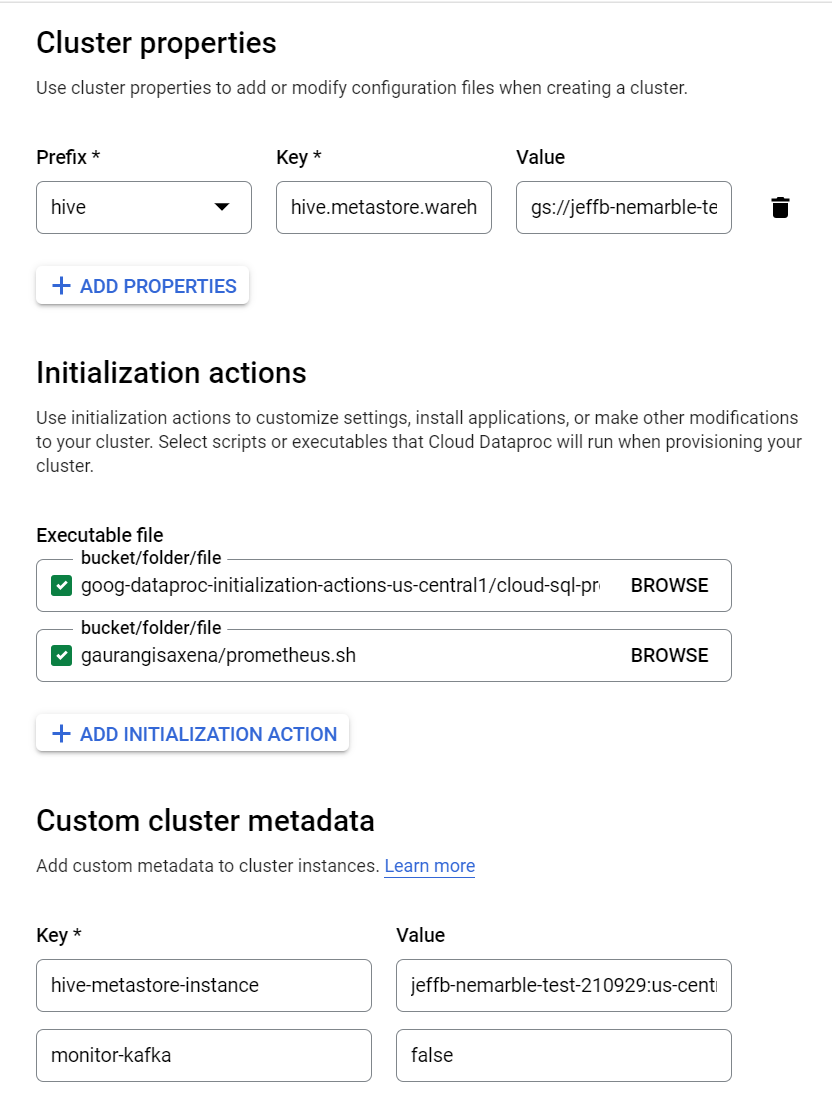
현재 Customize Cluster 페이지에서 몇 가지 값을 넣겠습니다.
우선 Cluster properites 란에 다음과 같은 값을 넣습니다. Cluster property는 설치한 clsuter의 속성을 지정할 수 있는 옵션입니다.
"hive.metastore.warehouse.dir" 속성은 방금 생성한 GCS bucket으로 클러스터의 Datawarehouse를 지정하는 속성입니다.
|
1
|
hive:hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse/datasets
|
cs |
Initialization actions 란에는 다음과 같은 GCS 버켓 경로를 넣습니다.
Initialization actions는 클러스터 생성 후 실행할 스크립트를 GCS 버켓 경로에 있는 sh파일로 지정해 실행할 수 있는 옵션입니다.
해당 옵션을 이용해 Startup script를 사용했을 때와 동일한 자동화를 구현할 수 있습니다.
아래 경로에서 REGION 값을 생성할 클러스터의 리전으로 바꿉니다.
- 첫 번째 경로는 Dataproc 클러스터와 CloudSQL 인스턴스를 연결할 CloudSQL Proxy 설치 스크립트입니다.
- 두 번째 경로는 Hadoop 및 Spark를 위한 Prometheus 설치 스크립트를 받을 수 있는 GCS 버켓 디렉토리입니다.
|
1
2
|
goog-dataproc-initialization-actions-${REGION}/cloud-sql-proxy/cloud-sql-proxy.sh
gaurangisaxena/prometheus.sh
|
cs |
마지막으로 Custom cluster metadata 란에 다음과 같은 값을 넣습니다.
Hive가 사용할 hive-site.xml파일을 수정하는 것과 동일한 옵션입니다.
- 방금 생성한 CloudSQL 인스턴스를 메타스토어로 지정합니다.
- 이 클러스터에서는 사용하지 않을 Kafka 모니터링을 Off하는 설정입니다.
|
1
2
|
hive-metastore-instance=${PROJECT}:${REGION}:hive-metastore
monitor-kafka=false
|
cs |
아래와 같이 모든 값이 입력되어야 합니다.
2. Dataproc 클러스터 설정
지금까지 Prometheus와 연계하기 위한 Dataproc 클러스터를 생성했습니다.
여기까지 진행했다면 이미 Hadoop과 관련한 메트릭운 Prometheus에서 수집하고 있는 상태입니다. 여기서 Grafana만 연동한다면 Hadoop 메트릭을 대쉬보드에서 확인할 수 있습니다.
하지만 Hive 메트릭은 아직 Prometheus에서 수집하고 있지 않은 상태입니다. 아직 Hive 메트릭을 export할 수 있는 exporter가 설치되어 있지 않기 떄문입니다.
여기서부터는 Hive 메트릭을 수집하기 위한 설정입니다. Hadoop 메트릭 수집으로 충분하다면 3장으로 넘어가도 무방합니다.
2-1. Hive 설정 구성
먼저 Hive 설정을 변경하기 위해 마스터 노드로 SSH 접속을 합니다.
그 후 /etc/hive/conf 경로에 존재하는 hive-env.sh 파일을 에디터로 다음과 같이 수정합니다.
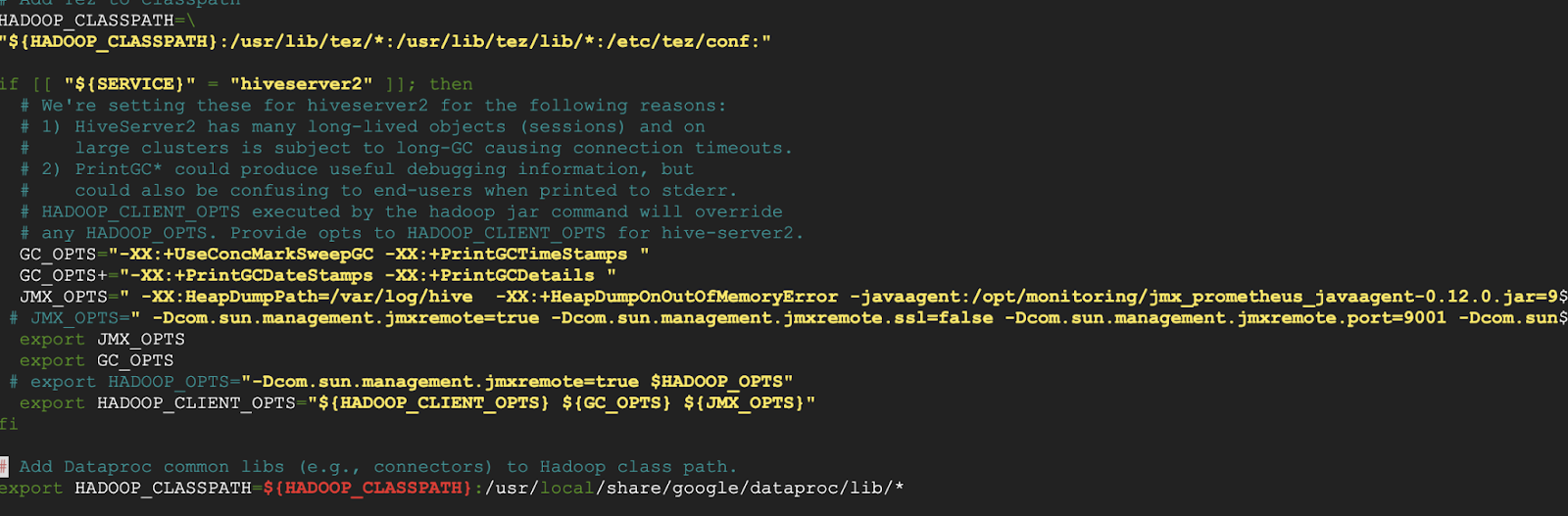
방법은 파일의 if [[ "${SERVICE}" = "hiveserver2" ]]; then 절에 아래 스크립트를 추가하면 됩니다.
(INSTANCE_EXTERNAL_IP를 마스터 노드 External IP로 치환)
|
1
2
3
4
5
|
GC_OPTS+="-XX:+PrintGCDateStamps -XX:+PrintGCDetails "
JMX_OPTS=" -javaagent:/opt/monitoring/jmx_prometheus_javaagent-0.12.0.jar=9008:/opt/monitoring/tomcat.yml -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=9001 -Djava.rmi.server.hostname=INSTANCE_EXTERNAL_IP"
export JMX_OPTS
export HADOOP_CLIENT_OPTS="${HADOOP_CLIENT_OPTS} ${GC_OPTS} ${JMX_OPTS}"
|
cs |
JMX 메트릭을 수집하는 /opt/monitoring/jmx_prometheus_javaagent-0.12.0.jar 경로의 JMX agent를 사용하고 해당 agent에 지정한 포트로 접근할 수 있게끔 하는 스크립트입니다. JMX agent는 JMX 메트릭을 Prometheus에서 사용할 수 있게끔 해주는 역할을 합니다.
이제 해당 포트로 Prometheus가 접근해 JMX 메트릭을 가져올 수 있습니다.
-javaagent 옵션만 삭제하면 jconsole 등 다른 툴에서도 JMX 메트릭을 가져올 수 있습니다.
수정 후 실제 /opt/monitoring/ 경로에 아래 jmx_prometheus_javaagent를 설치합니다.
jar 파일 : https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.12.0/

jar 파일과 함께 tomcat.yml 파일도 해당 경로에 넣습니다. tomcat.yml 파일의 컨텐츠는 다음과 같습니다.
|
1
2
3
4
5
6
|
---
lowercaseOutputLabelNames: true
lowercaseOutputName: true
rules:
- pattern: ".*"
|
cs |
다음에는 /etc/hive/conf 경로에 존재하는 hive-site.xml 파일도 에디터로 다음과 같이 수정합니다.
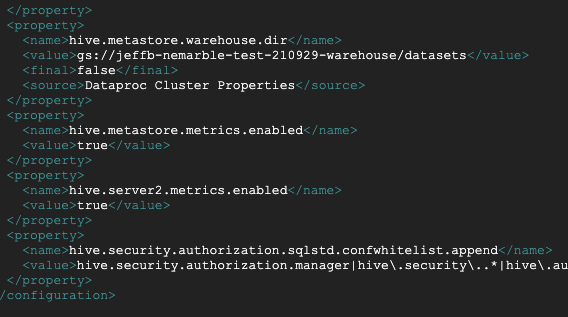
방법은 기존에 존재하던 <configuration> 절 내에 다음 스크립트를 추가합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<property>
<name>hive.metastore.metrics.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.server2.metrics.enabled</name>
<value>true</value>
</property>
|
cs |
hive-site.xml 파일을 보면 클러스터 생성 과정에서 Cluster properties에 넣었던 hive.metastore.warehouse.dir 속성이 이미 추가되어 있는 것을 볼 수 있습니다.
사실 Cluster properties 옵션은 클러스터 생성 과정에서 hive-site.xml 파일을 수정하는 것과 같습니다. 따라서 다음 클러스터 생성 시에는 생성 때 미리 위 속성을 Cluster properties에 넣어도 무방합니다.
2-2. Prometheus 설정
이제 prometheus가 JMX exporter가 수집한 메트릭들을 가져올 수 있도록 /etc/prometheus/ 경로의 prometheus.yml 파일을 수정합니다.
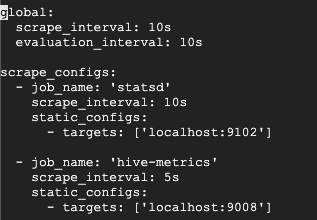
방법은 기존에 등록되어 있는 job_name: 'statsd' ... 항목 아래에 다음과 같은 새 항목을 추가합니다.
|
1
2
3
4
5
|
- job_name: 'hive-metrics'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9008']
|
cs |
'statsd'는 hadoop 메트릭을 수집하는 agent로 9102 포트로 메트릭을 노출하고 있습니다. 기존에는 Prometheus가 hadoop 메트릭만을 타겟으로 가져왔습니다.
그리고 저희는 방금 여기에 'hive-metrics' 라는 이름의 9008번 포트로 메트릭을 노출하는 agent를 Prometheus가 가져올 수 있도록 구성을 변경했습니다. 이제 hadoop과 더불어 hive 메트릭까지 prometheus에서 볼 수 있게 되었습니다.
Prometheus로 접속(hostname:9090)한 후 "Targets" 페이지에서 'statsd'와 'hive-metrics' 타겟이 등록되었다면 정상적으로 진행되고 있는 것입니다.
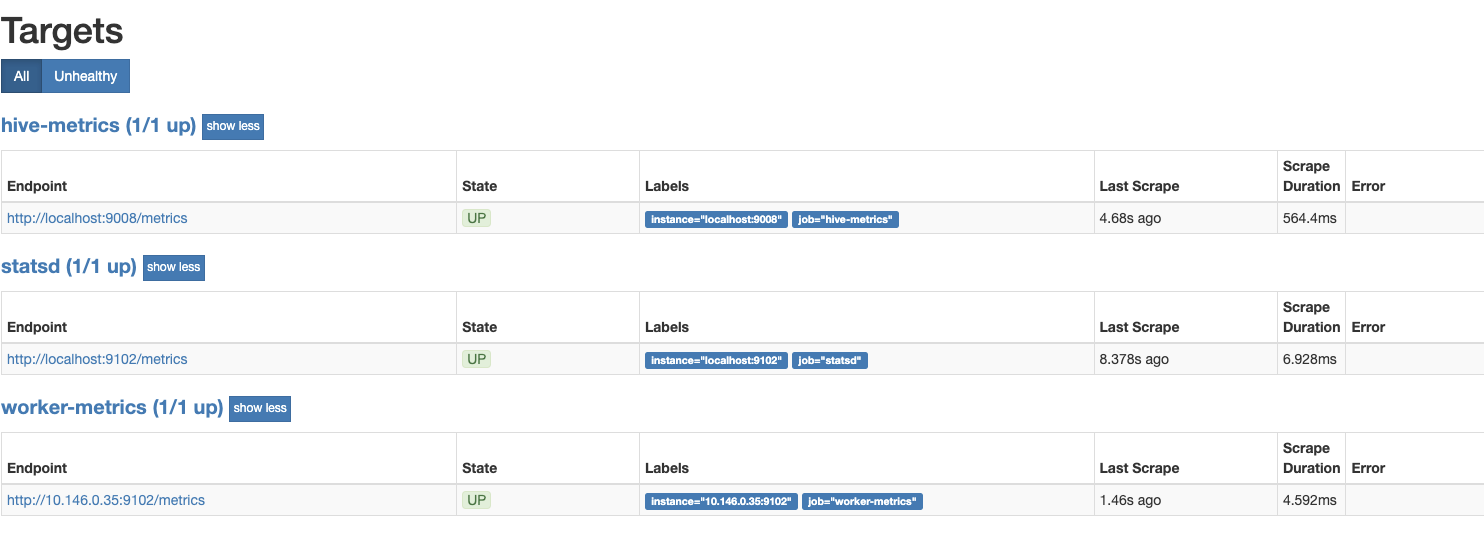
3. Grafana 설정 및 대쉬보드 사용
지금까지 Dataproc 클러스터의 메트릭을 Prometheus로 가져올 수 있었습니다.
마지막으로 Prometheus가 가져온 메트릭을 기반으로 Grafana 대쉬보드를 구성해 시각화된 구성으로 메트릭을 모니터링할 수 있습니다.
3-1. Grafana 설정
Grafana(hostname:3000)에 접속한 후 Configuration -> Add data source -> Prometheus 선택 후 Save&Test를 클릭합니다.
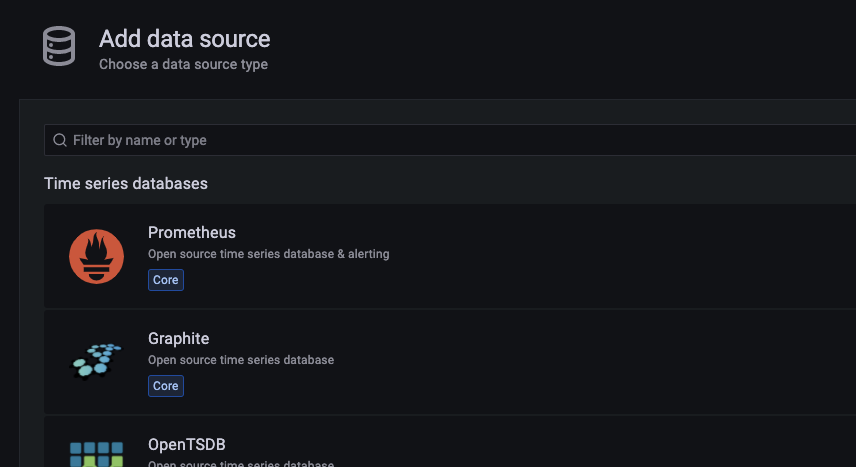
세이브가 정상적으로 진행됐다면 Prometheus가 가져온 Hadoop 및 Hive 메트릭을 Grafana에서 이용할 수 있습니다.
이미 만들어진 대쉬보드를 import하거나, 직접 커스텀 대쉬보드를 생성해 메트릭을 기반으로 한 대쉬보드를 구성할 수 있습니다.
3-2. Grafana 사용
이제 Grafana의 사용 준비까지 끝마쳤기 때문에 사용자가 원하는 대쉬보드를 구성해 메트릭을 모니터링할 수 있습니다.
이번 장에서는 간단하게 어떤 메트릭을 사용할 수 있는지 알아보고 커스텀 대쉬보드를 구성해보겠습니다.
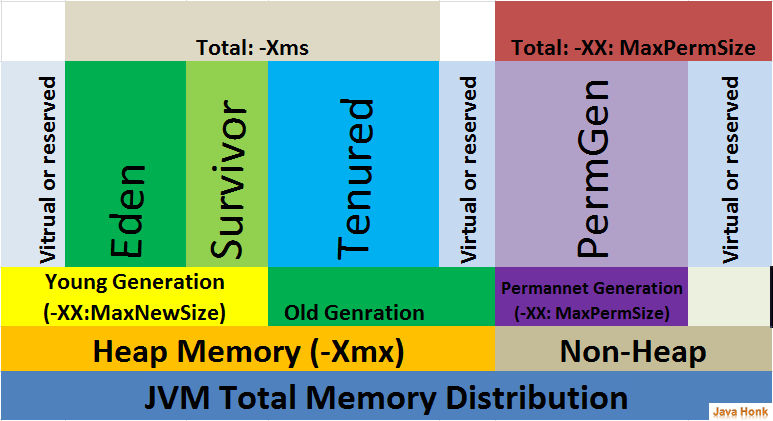
1. jvm_memory_pool_bytes_used
jvm 메모리 풀의 사용량을 나타내는 메트릭입니다. 메모리 사용량을 파악하는데 매우 중요한 메트릭입니다.
jvm 메모리는 Heap memory와 Non-Heap memory, 그 안에서도 Eden, Survivor, .. 등의 다양한 공간으로 이루어져 있는데, 공간마다 사용하고 있는 메모리 량을 파악함으로써 어떤 공간에서 메모리 사용량이 높아지는지, 메모리 리크는 어디서 발생하는지 등의 진단을 내릴 수 있습니다.

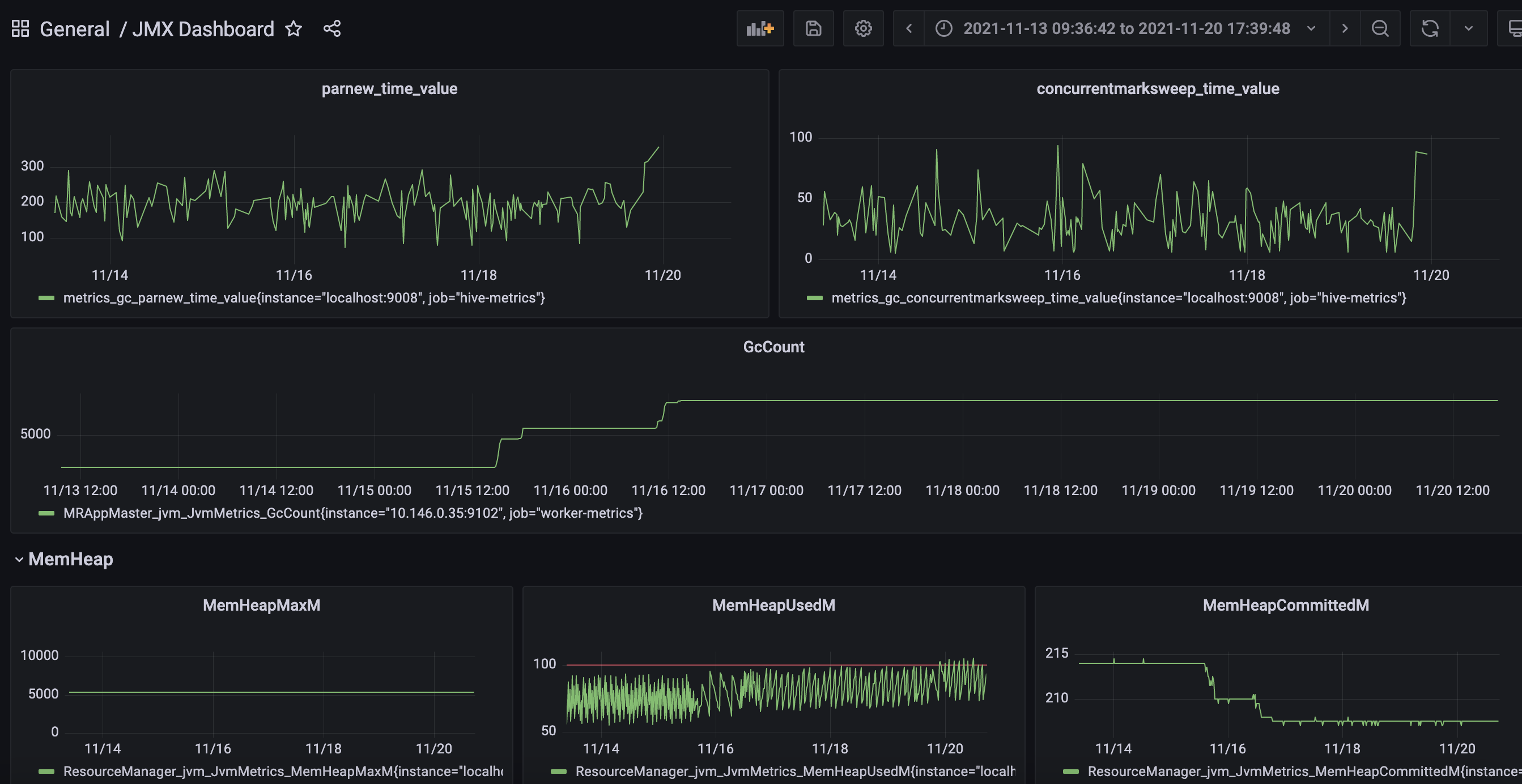
2. java_lang_GarbageCollector_LastGcInfo_duration
java 가비지컬렉터 별 가비지 컬렉팅 시간을 나타내는 메트릭입니다. 가비지 컬렉팅 시간이 길어진다는 것은 그만큼 쌓인 가비지가 많다던가, 가비지 컬렉션 알고리즘이 효율적이지 않다던가 하는 문제가 있을 수 있기 때문에 마찬가지로 중요한 메트릭입니다.
아래는 가비지 컬렉터 중 Parnew와 ConcurrentMarkSweep(CMS) 컬렉터의 가비지 컬렉팅 듀레이션을 나타내는 대쉬보드입니다.
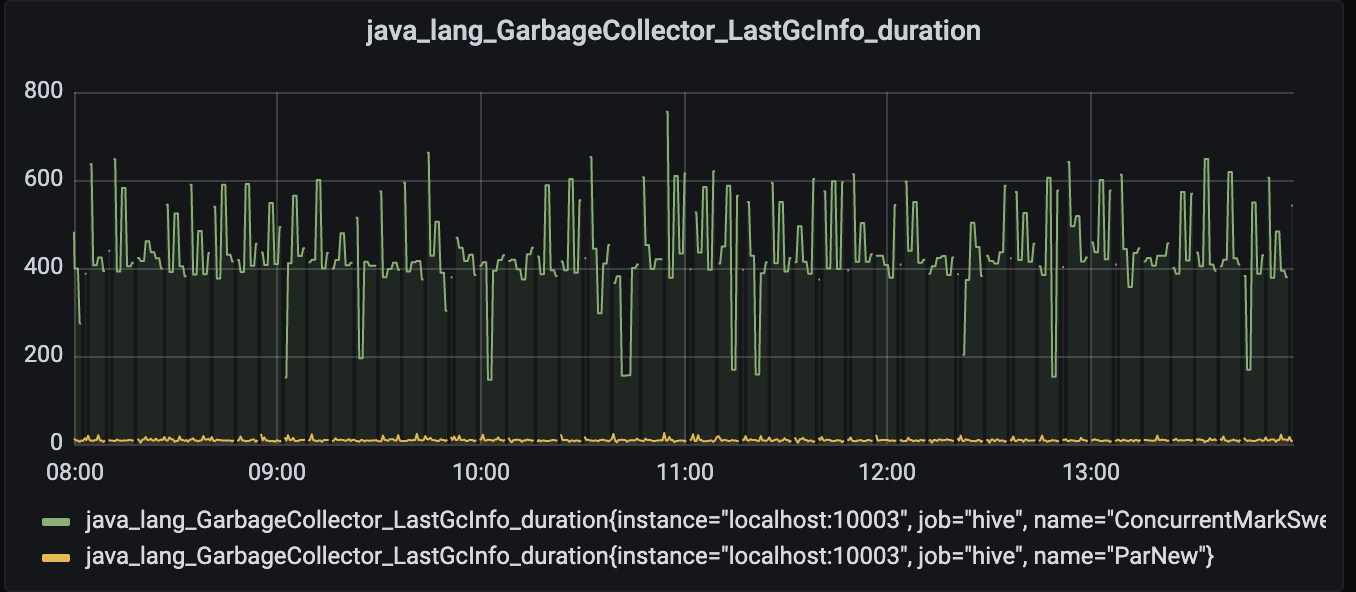
이 외에도 JVM 단, 혹은 하둡 및 하이브 단에서 수집할 수 있는 다양한 메트릭을 이용해 대쉬보드를 구성할 수 있습니다.
기존 Dataproc에서 제공하는 메트릭은 JVM단의 메트릭까지 제공하진 않기 때문에 상세한 진단을 내리기는 어렵습니다.
하지만 Prometheus와 Grafana를 이용한 모니터링 시스템을 구축함으로써 JVM 단까지 아우르는 더 상세한 모니터링을 통해 OOME나 메모리 리크같은 이슈까지 해결할 수 있는 진단을 할 수 있게 되었습니다.
4. 마무리
지금까지 Dataproc 클러스터에 올라간 Hadoop 플랫폼의 가시성을 확보하기 위해 Prometheus와 Grafana를 이용한 모니터링 시스템을 구축해봤습니다.
기존의 Hadoop 및 Hive에서 내보내고 있는 JMX 메트릭을 agent에서 수집해 Prometheus가 가져갈 수 있는 방식으로 변형 후 노출하고, Prometheus에서 노출된 포트로 메트릭을 수집해 Grafana로 시각화하는 과정이었습니다.
이 모니터링 시스템을 사용해 기존의 메트릭만으로는 부족했던 가시성을 채울 수 있습니다.
이 Dataproc 클러스터를 운영하며 가시성 면에서 부족함을 느끼거나 불편했던 분들에게 도움이 되는 포스팅이라 생각합니다.
'GCP' 카테고리의 다른 글
| Secret Manager에 저장된 중요 데이터를 Kubernetes Secret과 연동해보자(with GCP) (1) | 2022.04.11 |
|---|---|
| Kubernetes externalTrafficPolicy에 따른 동작과 GCP의 Container-native LoadBalancer 알아보기 (7) | 2022.02.23 |
| Google Cloud의 Cloud Deploy로 자동화된 CI/CD Pipeline 구성하기 (0) | 2021.11.05 |
| GCP Cloud armor의 DDoS protection 기능 사용 및 검증 (0) | 2021.10.07 |
| Function Framework를 이용해 local 환경에서 Cloud function을 사용해보자 (0) | 2021.07.24 |