

Apache beam은 Streaming 및 Batch성 데이터 작업을 지원하는 오픈소스 엔진입니다.
"beam"이라는 이름이 Batch에서 "B"를, Streaming에서 "eam"을 가져와 합친 단어라는 데서 Apache beam이 지향하고자 하는 바가 명확히 보입니다.
Apache beam은 단일 프로그래밍 모델로 Batch 와 Streaming 데이터 작업을 지원하며, 이렇게 작업한 모델은 다양한 런타임에서 구동할 수 있다는 다양한 활용성이 장점입니다.
현재 데이터 파이프라인 생성을 지원하는 언어는 Python, Java 및 Go가 있습니다. 간단히 Apache beam을 사용해보고자 한다면 아래 링크의 Beam Playground에서 웹 인터렉티브 환경을 이용해볼 수도 있습니다.
https://play.beam.apache.org/?example=SDK_JAVA/PRECOMPILED_OBJECT_TYPE_EXAMPLE/MinimalWordCount
Apache Beam Playground
play.beam.apache.org
이번 포스팅에서는 Apache beam으로 Batch 및 Streaming 데이터 파이프라인을 생성해보고 이를 로컬 및 Cloud 런타임인 GCP의 dataflow에서 실행해보도록 하겠습니다.
1. Apache beam의 구조
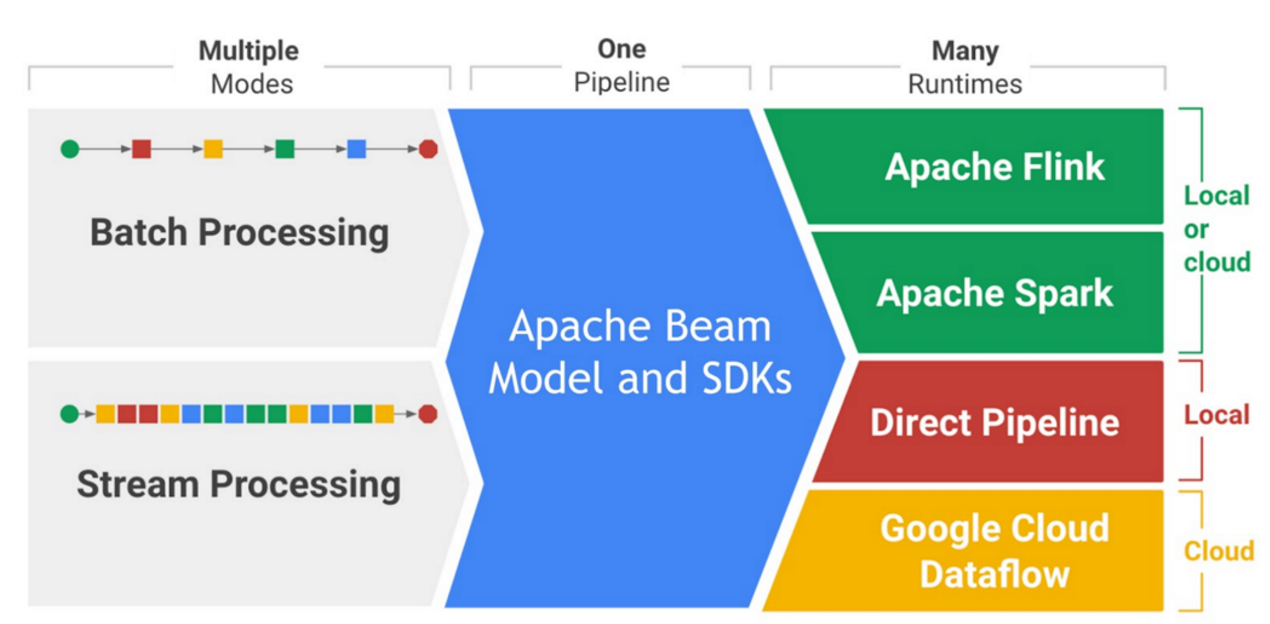
Apache beam은 위에서 말했듯이, Batch 및 Streaming 데이터 작업을 지원하는 단일 엔진입니다. 이는 위 이미지에서도 잘 나타나있습니다.
데이터 처리 작업의 상당 부분을 추상화했기 때문에 사용자 입장에서는 데이터가 연속적으로 들어오거나(Unbounded), 혹은 불연속적으로 들어오는지(Bounded)에 상관 없이 편리하게 처리 모델을 생성할 수 있습니다.
이를 가능케 하기 위해 Apache beam에서 사용하는 개념이 있습니다. 여러 중요한 개념들이 있지만 본 포스팅에서는 Apache beam의 근간을 이루는 몇 가지만 보도록 하겠습니다.
1. Pipeline
Pipeline은 Apache beam을 이용해 처리하려는 데이터 처리 작업의 총체를 말합니다.
우리는 Pipeline을 정의함으로써 데이터를 처리하고 내보내는 단일한 데이터 파이프라인을 생성할 수 있습니다.
이를 통해 각각 존재하는 데이터 처리 로직을 Pipeline이라는 구조로 묶어줄 수 있습니다.
2.PCollection
PCollection은 우리가 처리하고자 하는, 혹은 처리하고 난 뒤의 데이터셋을 말합니다.
Apache beam은 batch와 Streaming 데이터를 처리할 수 있기 때문에 PCollection 또한 연속적, 혹은 불연속적으로 들어오는 데이터 모두 포함할 수 있습니다.
3.PTransform
PTranform은 데이터를 어떻게 처리하고자 하는지를 정의한 로직을 말합니다.
보통 PCollection으로 들어오는 데이터셋을 PTransform으로 처리한 뒤, 다시 PCollection으로 내보내는 일련의 과정을 데이터 파이프라인으로 정의합니다.
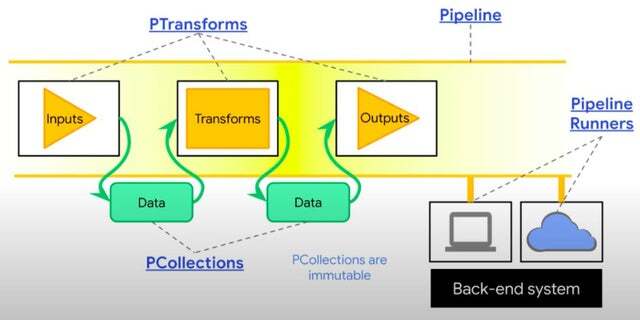
위 개념들을 이미지로 도식화해보면 위와 같습니다.
이미지에서 볼 수 있듯이 Apaceh beam의 데이터 파이프라인은 Pipeline이라는 데이터 파이프라인을 정의한 뒤, 원하는 데이터를 Pcollection으로 입력하고, 이를 PTransform으로 처리하면, 이로 인해 생성된 PCollection에서 원하는 데이터를 뽑아내는 일련의 과정으로 이루어져 있다는 것을 알 수 있습니다.
2. Apache beam 사용해보기
이제 본격적으로 Apache beam을 사용해보면서 어떻게 데이터 파이프라인을 생성하는지 알아보겠습니다
본 포스팅은 Apache beam이 지원하는 3가지 언어 중 Python을 사용하는 것으로 작성하였습니다.
1. 환경 구성
우선 Apache beam을 로컬에서 사용하기 위한 Python 환경을 설정해보겠습니다.
현재 Apache beam이 공식적으로 지원하는 Python SDK의 Python 버전은 3.6, 3.7, 3.8이며 PIP 버전은 7.0 이상 입니다.
이 버전 중 하나로 Python을 설치합니다. 본 포스팅에서는 Python 3.8.10, PIP 버전은 21.2.3, MACOS에서 진행했습니다.

기본 환경을 구성하기 위해 아래 명령어를 실행합니다.
|
1
2
3
|
python -m venv /path/to/directory
. /path/to/directory/bin/activate
pip install 'apache-beam[gcp]'
|
cs |
먼저 Python 가상 환경을 생성하기 위해 python -m venv ... 명령어를 실행합니다. "/path/to/directory" 부분을 원하는 경로로 수정합니다.
다음으로 생성된 venv 가상 환경을 실행합니다.
그 후 pip 패키지 매니저를 사용해 apache-beam[gcp] 패키지를 설치합니다. 본 패키지는 기본 apache-beam에 GCP를 위한 추가 dependancies를 설치하는 패키지입니다.
이번 포스팅에서는 GCP의 bigQuery 및 Pub/sub에서 데이터를 가져오고, Apach beam의 Cloud runtime인 Dataflow를 사용해볼 것이기 때문에 GCP 관련 dependancies도 설치해줍니다.
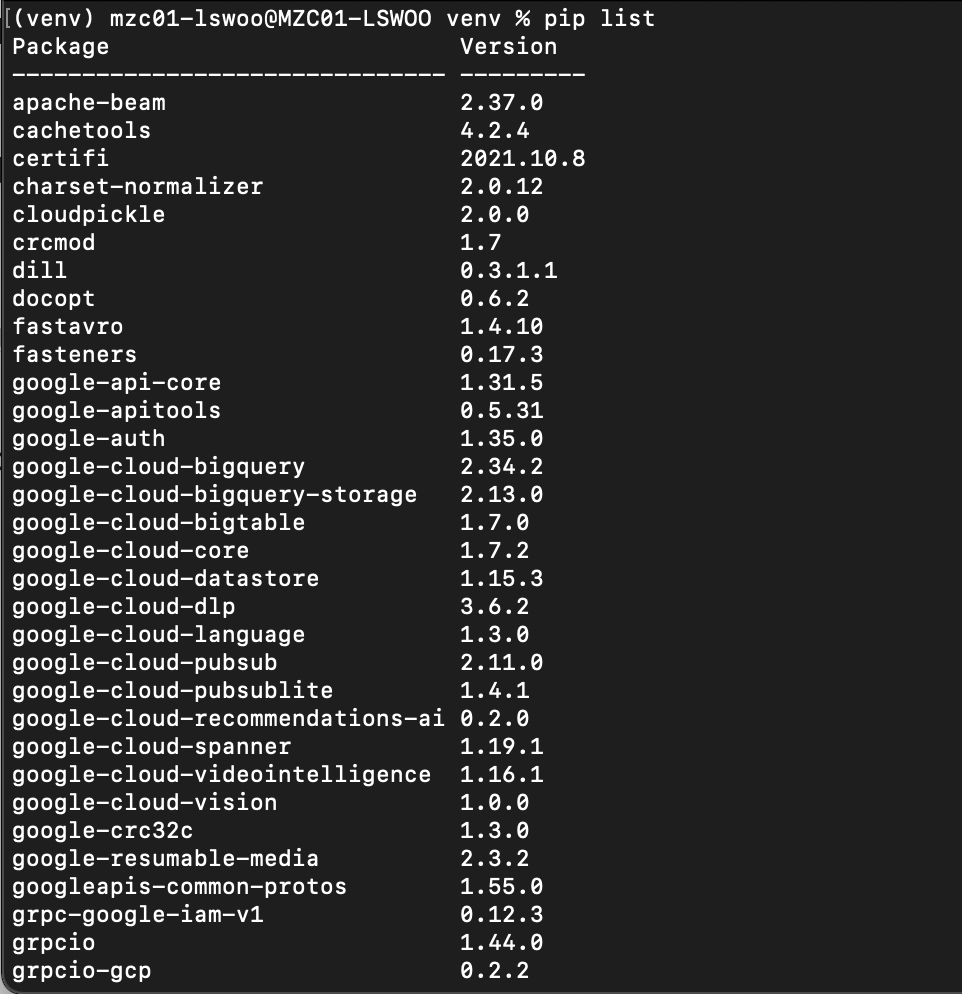
이후 pip list 명령어로 설치한 dependancies를 확인할 수 있습니다.
2. 기본 동작
Python 환경을 성공적으로 구성했다면 이제 IDE를 켜고 Python 코드를 작성해봅시다.
아래 코드를 바탕으로 Python 파일을 생성합니다. 이 코드는 Apache beam의 가장 기본적인 형태라고 할 수 있습니다.
|
1
2 3 4 5 6 7
|
import apache_beam as beam
with beam.Pipeline() as p: (p | beam.Create(['Hello Beam'])
| beam.Map(print))
|
cs |
Output :
Hello Beam
3번 라인의 with beam.Pipeline() as p: 는 apache beam의 데이터 파이프라인을 정의하는 부분입니다. 위에서 설명한 Apache beam의 Pipeline은 이런 방식으로 생성됩니다.
5번 라인의 p | ... 부터 Pipeline이 처리할 로직의 순서인 step을 정의할 수 있습니다.
Step은 파이프("|")로 구분하며 각 Step은 PCollection이나 PTransform같은 데이터 처리 로직을 정의해 사용할 수 있습니다
본 파이프라인에서는 첫번째 Step으로 PCollection의 일부인 데이터 생성 메소드 "Create"를 사용해 데이터를 생성했으며, 이로 생성된 데이터를 두번째 Step으로 PTransform의 일종인 "Map"을 사용해 Print했습니다.
이렇게 Apache beam의 모든 데이터 파이프라인은 p | STEP_1 | STEP_2 | ... 처럼 Pipeline을 생성한 뒤 그 내부에 각 Step을 정의하는 구조로이루어져 있습니다.
3. Element 단위 작업
다룰 수 있는 가장 작은 데이터 단위를 Apache beam에서는 Element라고 표현합니다.
Element 단위 작업이란 가장 작은 단위의 데이터인 Element를 기반으로 처리할 수 있는 작업이라는 것이죠.
Apache beam에서 대표적인 Element 단위 작업으로는 Map과 ParDo가 있습니다.
먼저 Map을 사용해보겠습니다. Map은 가장 간단하게 사용할 수 있는 Element 단위의 작업입니다.
|
1
2
3
4
5
6
7
8
|
import apache_beam as beam
with beam.Pipeline() as p:
(p | beam.Create([10, 20, 30, 40, 50])
| beam.Map(lambda num: num * 5)
| beam.Map(print))
|
cs |
Output :
50
100
150
200
250
위 코드는 7번 라인의 beam.Map(lambda num: num *5)로 Map을 정의해 사용한 데이터 파이프라인입니다.
[10, 20, 30, 40, 50] 으로 이루어진 데이터셋을 Element 단위, 즉 각 요소 단위로 5씩 곱하는 간단한 로직을 구현했습니다.
그 결과로 반환되는 데이터는 각 Element에 5를 곱한 [50, 100, 150, 200, 250]이 되는 것을 알 수 있습니다.
이렇게 Map에 Lambda 함수를 정의해서 간단한 데이터 처리 작업을 정의할 수 있습니다.
또 다른 Element 단위 작업으로 ParDo가 존재합니다. ParDo는 함수를 직접 정의해서 사용할 수 있는 작업입니다.
ParDo는 사실상 거의 모든 데이터 파이프라인 작업은 ParDo로 모두 처리할 수 있다고 할 정도로 범용성 높고 간단한 작업입니다.
아래는 ParDo를 사용한 데이터 파이프라인입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import apache_beam as beam
class MultiplyByTenDoFn(beam.DoFn):
def process(self, element):
yield element * 10
with beam.Pipeline() as p:
(p | beam.Create([1, 2, 3, 4, 5])
| beam.ParDo(MultiplyByTenDoFn())
| beam.Map(print))
|
cs |
Output:
10
20
30
40
50
13번 라인에서 볼 수 있듯이 ParDo는 원하는 데이터 처리 로직 Class를 정의해서 사용할 수 있습니다.
4번 라인에서 정의한 데이터 처리 로직인 MultiplyByTenDoFn을 불러와 각 Element에 10을 곱한 것을 볼 수 있습니다.
주의할 것은 함수가 반환할때 사용하는 키워드는 return이 아닌 yield여야 한다는 것입니다. ParDo는 단일 Element 별로 처리하는 작업이기 때문에 제너레이터를 반환해야 합니다.
현재 Apache beam에는 위의 두 작업 말고도 수 많은 데이터 처리 방식을 지원하는 작업을 지원하고 있습니다.
모든 작업을 이 포스팅에서 다루지는 못하지만, 가장 기초적이고 범용성 높은 두 작업을 이해하면 나머지 작업도 이해하기 어렵지 않을 것입니다.
지원하는 모든 작업의 리스트는 공식 문서를 참고해 주세요.
https://beam.apache.org/documentation/programming-guide/
Beam Programming Guide
beam.apache.org
4. 데이터셋 입출력
데이터를 처리하는 로직도 중요하지만 어떤 데이터셋을 가져와서 어디로 보낼지 정의하는 것 또한 실질적인 관점에선 더 중요한 작업입니다.
Apache beam은 일반 Text 파일부터 Database, Message bus, Object storage까지 다양한 방식의 데이터 IO를 지원하고 있습니다.
사용하고자 하는 데이터셋이 Apache beam의 built-in IO에 존재하지 않다면 Custom IO Connector를 만들어 사용할 수도 있습니다.
현재 Apache beam이 지원하는 모든 IO의 목록은 공식 문서에서 볼 수 있습니다.
https://beam.apache.org/documentation/io/built-in/
Built-in I/O Transforms
Built-in I/O Transforms This table contains the currently available I/O transforms. Consult the Programming Guide I/O section for general usage instructions. Adapt for: File-based These I/O connectors involve working with files. FileSystem Beam provides a
beam.apache.org
이번 포스팅에서는 Apache beam이 공식적으로 지원하는 IO 중 GCP의 Message bus인 Pub/Sub과 DW인 bigQuery를 데이터셋으로 사용해보겠습니다.
더 정확히는 GCP에서 Pubsub으로 제공하는 Public 스트리밍 데이터셋인 "taxirides-realtime"(이름에서 유추할 수 있듯이 실시간 택시 정보 데이터입니다.)을 받아서 bigQuery 테이블로 저장하는 데이터 파이프라인을 생성해보겠습니다.
이 작업은 GCP 프로젝트를 사용할 수 있는 계정이 존재하고 작업 환경에 CloudSDK가 설치되어 있음을 가정하고 진행합니다.
아래 코드를 사용합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import apache_beam as beam
import apache_beam.transforms.window as window
import json
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.io.gcp.internal.clients import bigquery
from typing import Any, Dict
project = PROJECT_ID table = TABLE_NAME bucket_url = gs://GCS_BUCKET output_table_spec = bigquery.TableReference(
projectId=project,
datasetId=table,
tableId='taxirides_output_table'
)
SCHEMA = {
'fields': [
{'name': 'ride_id', 'type': 'STRING', 'mode': 'REQUIRED'},
{'name': 'point_idx', 'type': 'INTEGER', 'mode': 'NULLABLE'},
{'name': 'longitude', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'timestamp', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'},
{'name': 'meter_reading', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'meter_increment', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'ride_status', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'passenger_count', 'type': 'INTEGER', 'mode': 'NULLABLE',}
]
}
options = PipelineOptions(streaming=True, project=project)
def parse_json_message(message: str) -> Dict[str, Any]:
row = json.loads(message)
return {
"ride_id": row['ride_id'],
"point_idx":row['point_idx'],
"longitude":row['longitude'],
"timestamp":row['timestamp'],
"meter_reading":row["meter_reading"],
"meter_increment":row['meter_increment'],
"ride_status":row["ride_status"],
"passenger_count":row["passenger_count"]
}
def run():
with beam.Pipeline(options=options) as p:
records = (p | "read" >> beam.io.ReadFromPubSub(
topic='projects/pubsub-public-data/topics/taxirides-realtime').with_output_types(bytes)
| "UTF-8 bytes to string" >> beam.Map(lambda msg: msg.decode("utf-8"))
| "Parse JSON messages" >> beam.Map(parse_json_message)
| "Fixed-size windows" >> beam.WindowInto(window.FixedWindows(60, 0))
)
write = records | "write" >> beam.io.WriteToBigQuery(table=output_table_spec,
schema=SCHEMA,
custom_gcs_temp_location='bucket_url',
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
if __name__ == '__main__':
run()
|
cs |
위 코드에서 PROJECT_ID, TABLE_NAME, GCS_BUCKET 부분을 각각 GCP 프로젝트 ID, bigQuery 테이블 이름, GCS 버켓 이름으로 치환합니다.
길이 상 위 코드를 단락 별로 나누어서 분석해보겠습니다.
1. output_table_spec ..
|
1
2
3
4
5
|
output_table_spec = bigquery.TableReference(
projectId=project,
datasetId=table,
tableId='taxirides_output_table'
)
|
cs |
bigQuery 테이블에 쓰기 작업을 하기 위해 필요한 요소 중 bigquery 테이블 규격을 정의하는 코드입니다.
Apache beam의 bigquery IO에서 TableReference()를 사용하면 쉽게 bigQuery 테이블을 정의할 수 있습니다.
2. SCHEMA = ...
|
1
2
3
4
5
6
7
8
9
10
11
12
|
SCHEMA = {
'fields': [
{'name': 'ride_id', 'type': 'STRING', 'mode': 'REQUIRED'},
{'name': 'point_idx', 'type': 'INTEGER', 'mode': 'NULLABLE'},
{'name': 'longitude', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'timestamp', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'},
{'name': 'meter_reading', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'meter_increment', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'ride_status', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'passenger_count', 'type': 'INTEGER', 'mode': 'NULLABLE',}
]
}
|
cs |
마찬가지로 bigQuery 테이블에 쓰기 작업을 하기 위해 필요한 요소 중 bigQuery 테이블 스키마를 정의하는 코드입니다.
Pub/sub 메세지를 통해서 오는 JSON 포맷과 동일하거나 "NULLABLE" mode의 칼럼이 생략된 스키마를 정의해야 합니다.
일반적인 구조의 bigQuery 테이블 스키마는 위와 같이 name, type, mode의 3개 요소를 정의할 수 있습니다.
단 Nested나 Repeated 칼럼의 경우 중첩된 구조를 사용해서 스키마를 구성해야 한다는 점에 주의해야 합니다.
3. options = ...
|
1
|
options = PipelineOptions(streaming=True, project=project)
|
cs |
Apache beam의 PIpeline에 사용할 Option을 지정하는 코드입니다.
Pub/sub을 통해서 받는 메세지 데이터는 Streaming 데이터이기 때문에, Streaming=True 옵션을 통해서 Streaming 모드로 바꿔줘야 Streaming 데이터를 처리할 수 있습니다.
4. def parse_json_message...
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def parse_json_message(message: str) -> Dict[str, Any]:
row = json.loads(message)
return {
"ride_id": row['ride_id'],
"point_idx":row['point_idx'],
"longitude":row['longitude'],
"timestamp":row['timestamp'],
"meter_reading":row["meter_reading"],
"meter_increment":row['meter_increment'],
"ride_status":row["ride_status"],
"passenger_count":row["passenger_count"]
}
|
cs |
parse_json_message()는 Pipeline의 Map 작업에 사용할 데이터 처리 로직입니다.
json형태로 들어오는 데이터를 딕셔너리 형태로 가공해 반환하는 함수입니다.
딕셔너리의 구조는 이전에 생성한 bigQuery 테이블의 스키마와 동일해야 bigQuery 테이블에 write 시 에러를 반환하지 않습니다.
5. def run(): ...
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def run():
with beam.Pipeline(options=options) as p:
records = (p | "Read from PubSub" >> beam.io.ReadFromPubSub(
topic='projects/pubsub-public-data/topics/taxirides-realtime').with_output_types(bytes)
| "UTF-8 bytes to string" >> beam.Map(lambda msg: msg.decode("utf-8"))
| "Parse JSON messages" >> beam.Map(parse_json_message)
| "Fixed-size windows" >> beam.WindowInto(window.FixedWindows(60, 0))
)
write = records | "Write to bigQuery" >> beam.io.WriteToBigQuery(table=output_table_spec,
schema=SCHEMA,
custom_gcs_temp_location='bucket_url',
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
if __name__ == '__main__':
run()
|
cs |
Apache beam을 사용해 실행하고자 하는 데이터 파이프라인을 정의하는 코드입니다.
전체 파이프라인의 Step은
Read from PubSub -> UTF-8 bytes to string -> Parse JSON messages -> Fixed-size windows -> Write to bigQuery
와 같은 구성으로 이루어져 있는 것을 볼 수 있습니다.
8번 라인의 beam.WindowInto()는 스트리밍으로 들어오는 데이터의 구간을 어떻게 설정할 것이냐를 정의하는 Windowing과 관련된 부분입니다.
현재는 60초 간격으로 고정된 Windowing을 사용하고 있는 것을 볼 수 있습니다.
코드를 실행하면 GCP bigQuery 콘솔에서 아래와 같은 작업 결과를 확인할 수 있습니다.
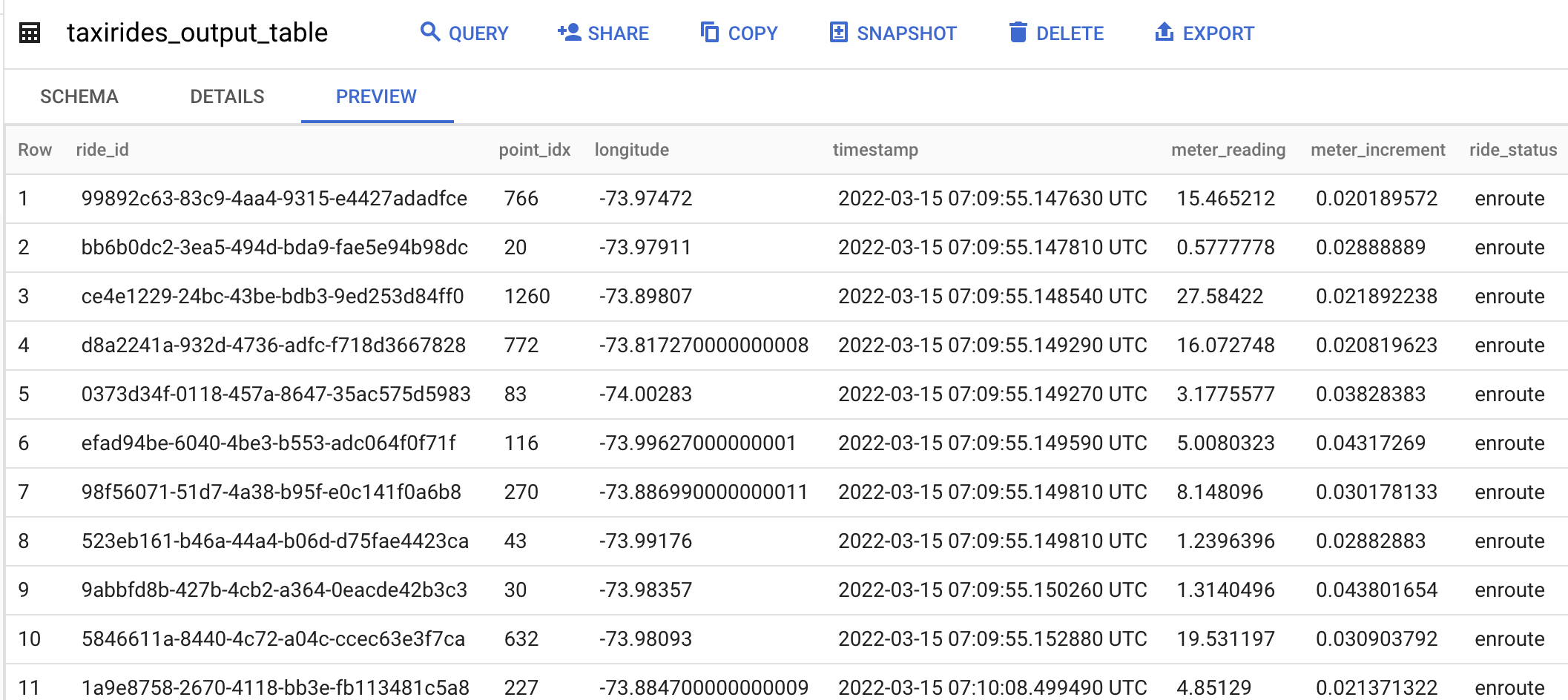
테이블 내용을 보면 Pub/sub으로 들어오는 데이터가 bigQuery 테이블에 지정한 Schema대로 입력된 것을 볼 수 있습니다.
이번 작업은 Streaming mode로 실행한 Apache beam 작업이기 때문에 지속적으로 테이블에 데이터가 쌓이게 됩니다.
Apache beam에서는 이러한 방식으로 데이터의 입출력을 이용해 데이터 파이프라인을 구성할 수 있습니다.
3. Cloud 환경에서 Apache beam 작업 실행하기
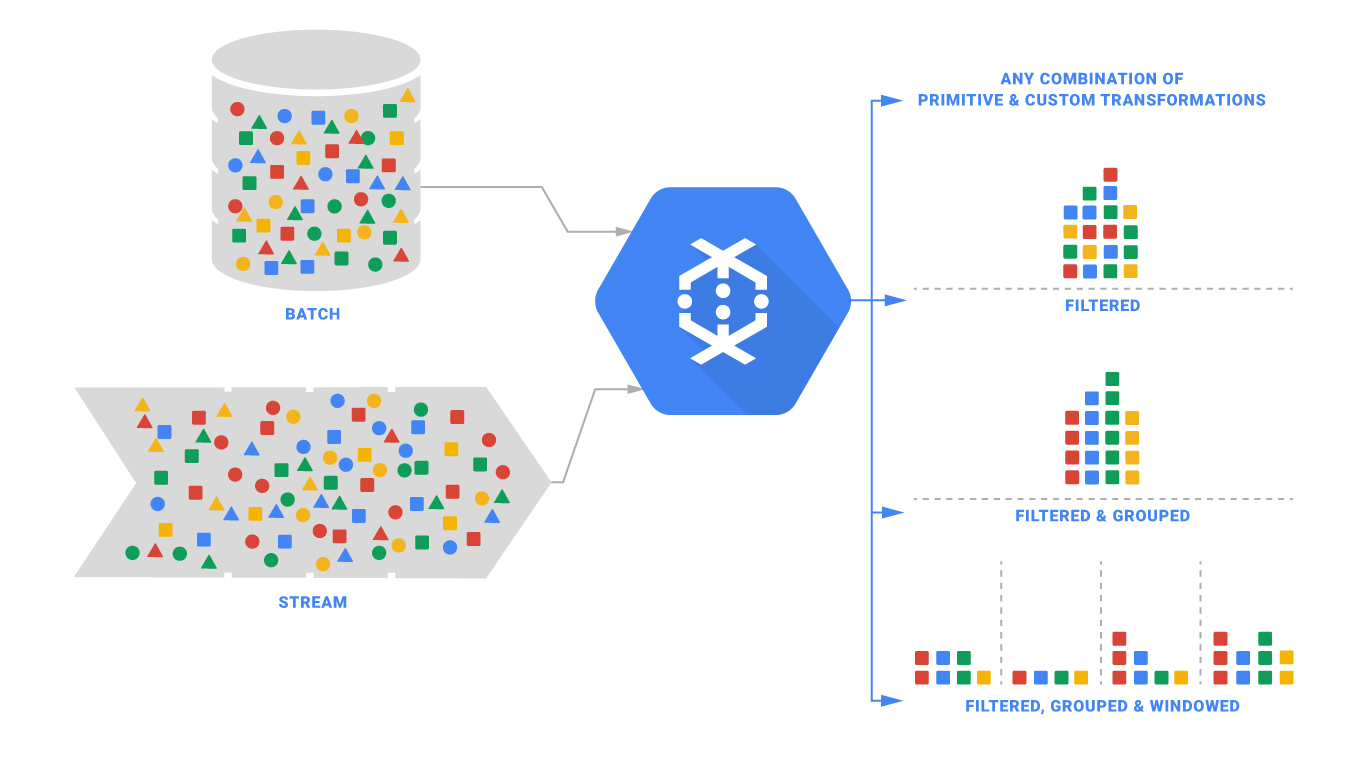
위에서 본 것처럼 지금까지의 Apache beam 작업은 모두 로컬 환경에서 구동했습니다.
로컬 환경에서 구동한다는 말은 즉 환경 구성 및 가용성, 리소스 관리 등을 모두 사용자가 맡아서 처리해야 한다는 뜻이기도 합니다.
때문에 모든 작업을 사용자가 관리해야 하고 작업이 로컬 환경에 종속된다는 단점이 있죠.
이런 단점을 극복할 수 있는 것이 바로 Cloud 환경에서의 작업이라고 할 수 있겠습니다.
Apache beam도 Cloud 환경에서의 작업을 지원하고 있는데요, 그 중에는 Cloud 환경에서 Apache beam 데이터 파이프라인을 구동할 수 있는 Dataflow Runner가 있습니다. Dataflow란 Google Cloud의 관리형 Apache beam 서비스입니다.
이번 장에서는 이 GCP Dataflow를 활용해 Cloud 환경에서 Apache beam 데이터 파이프라인을 구동해보겠습니다.
다음 명령어를 사용해 Apache beam 작업을 Dataflow로 제출합니다.
|
1
2
3
4
5
|
python -m APACHE_BEAM_SCRIPT \
--region DATAFLOW_REGION \
--runner DataflowRunner \
--project PROJECT_ID \
--temp_location gs://STORAGE_BUCKET/tmp/
|
cs |
APACHE_BEAM_SCRIPT : 작업을 실행할 Python 파일을 지정합니다.
DATAFLOW_REGION : Dataflow 작업을 실행할 인스턴스의 리전을 지정합니다.
PROJECT_ID : GCP 프로젝트 ID를 지정합니다.
STORAGE_BUCKET : GCS 버켓을 지정합니다.
커맨드를 실행하고 GCP 콘솔의 Dataflow 화면으로 진입하면 아래와 같이 제출한 작업이 실행되고 있는 것을 볼 수 있습니다.
실행되고 있는 작업을 클릭하면 작업의 세부 사항을 볼 수 있습니다.
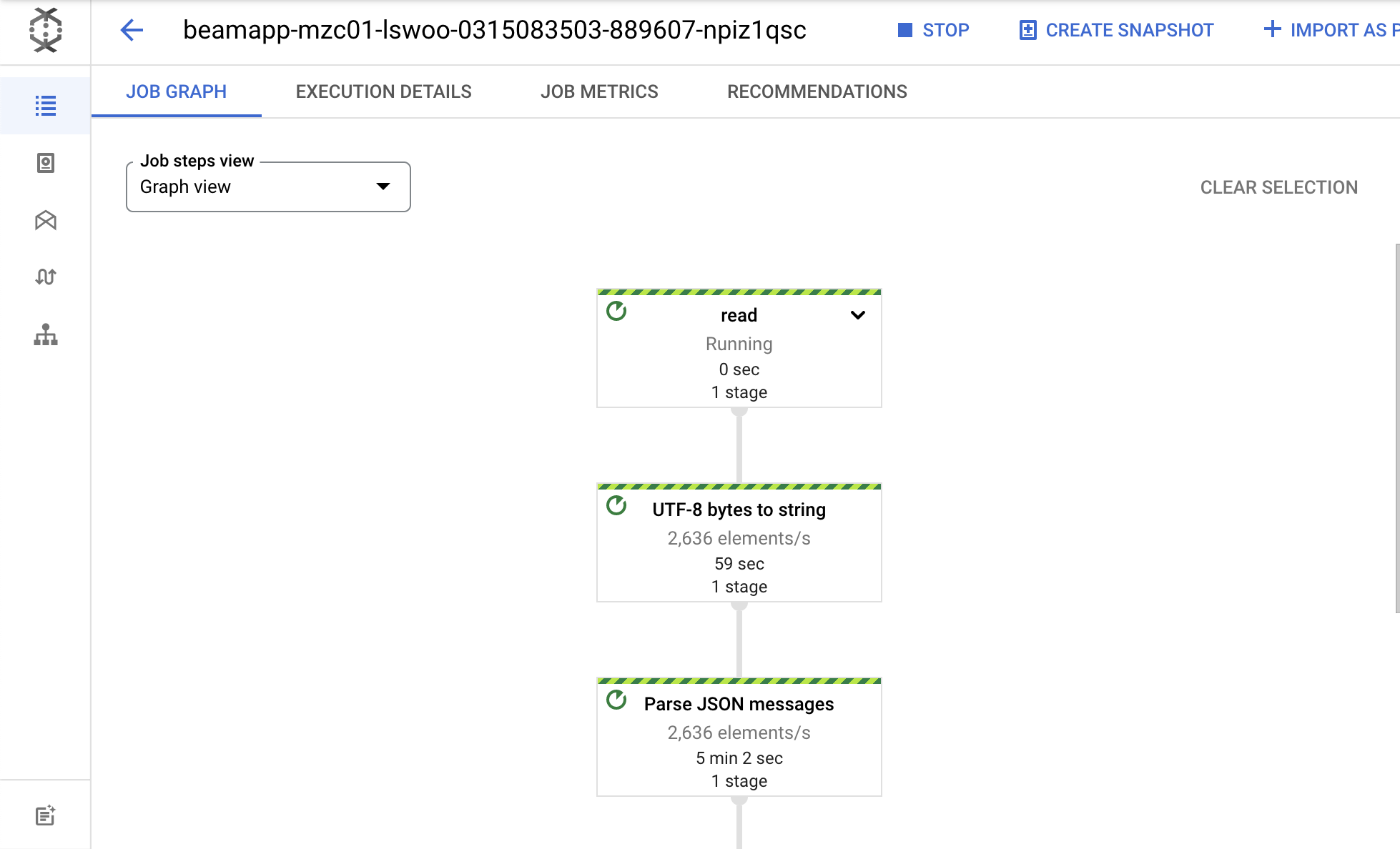
Dataflow는 Apache beam이 구동하고 있는 파이프라인을 시각화해주는 기능을 가지고 있습니다. 콘솔 화면의 JOB GRAPH 탭에서 파이프라인의 각 Step이 표현된 것을 볼 수 있습니다.
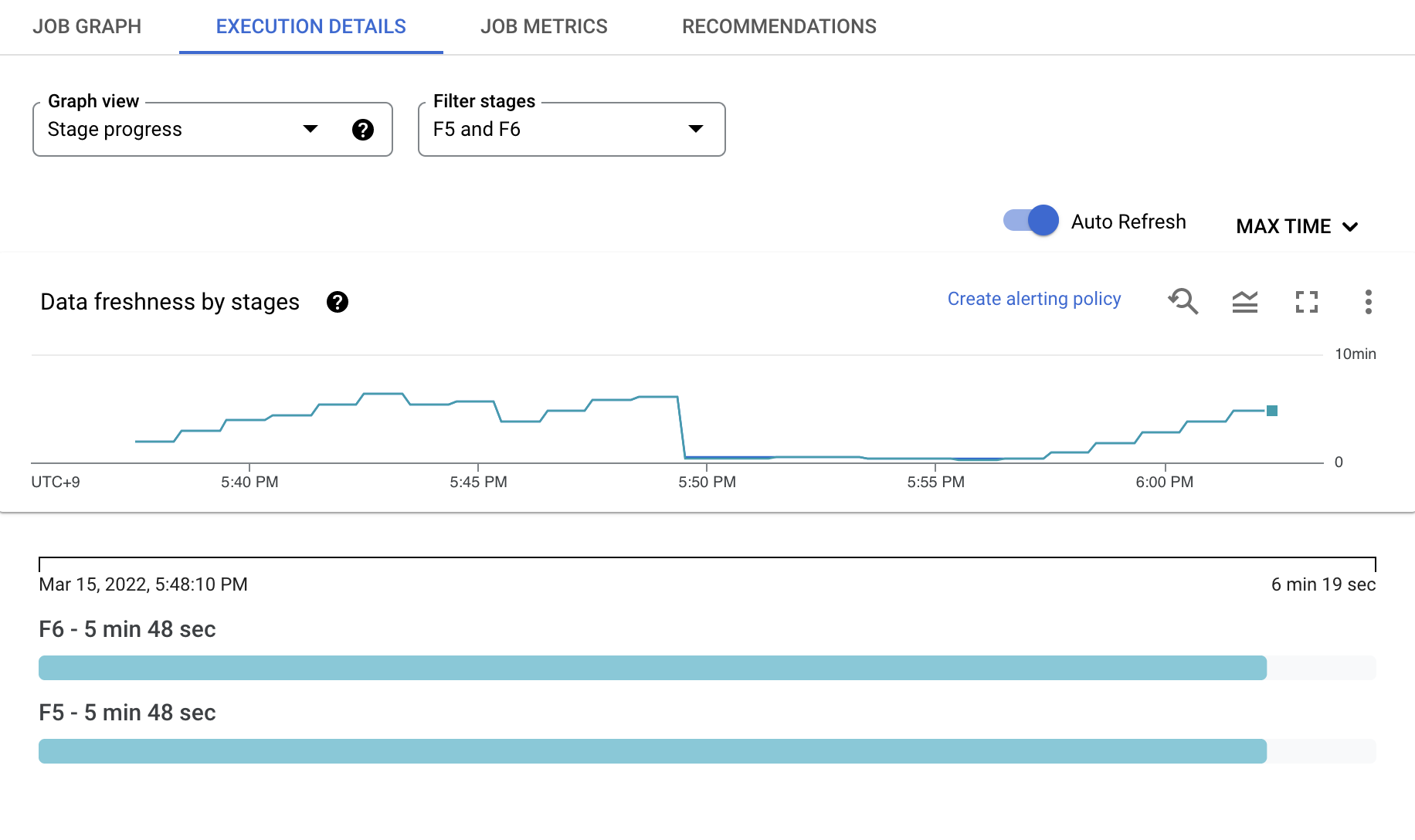
EXECUTION DETAILS 탭에서는 파이프라인을 실행하며 처리된 데이터들의 Freshness를 그래프로 확인할 수 있습니다.
이를 통해 Dataflow를 통해 처리된 데이터가 언제 들어온 데이터인지 쉽게 확인할 수 있습니다.
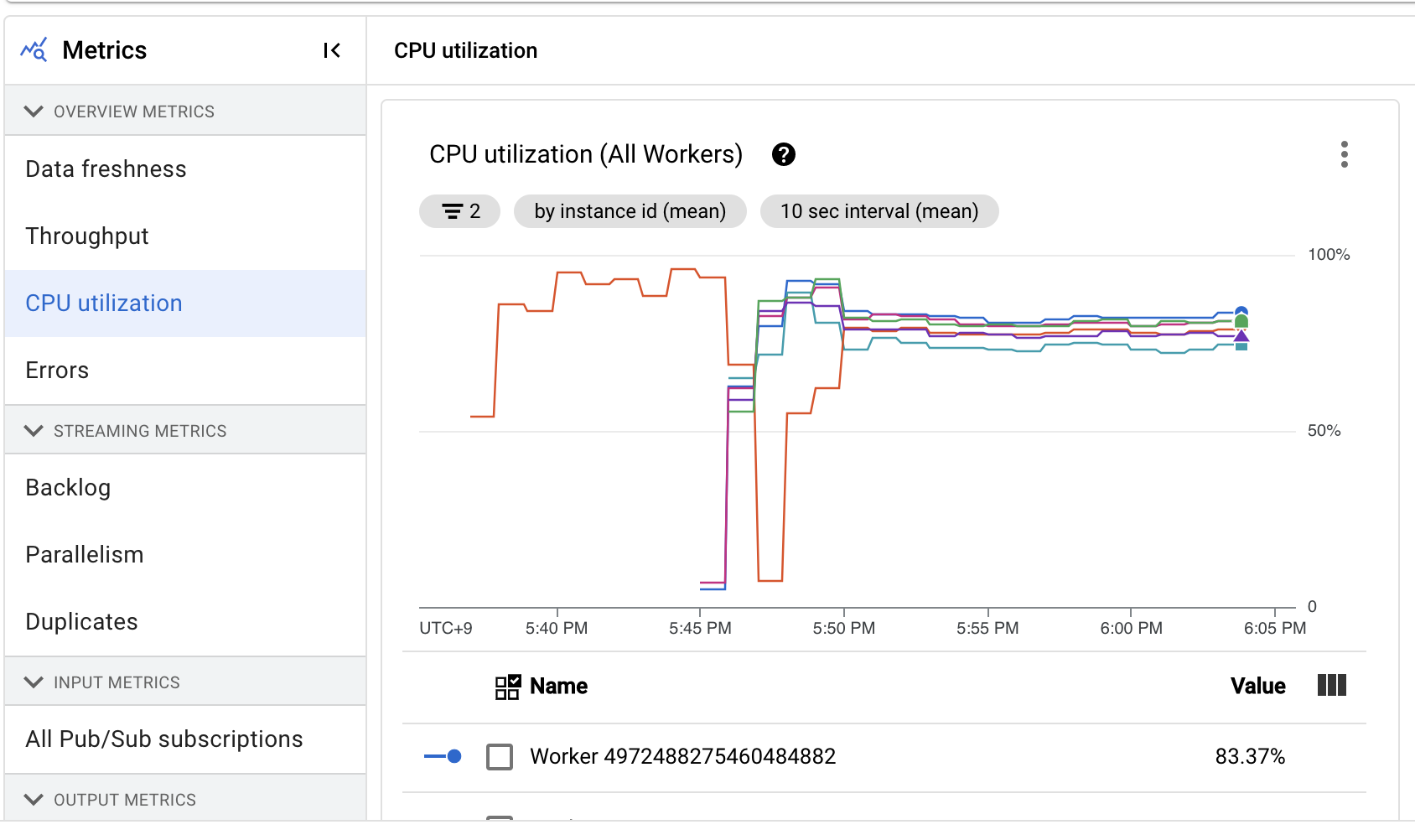
JOB METRICS 탭에서는 Dataflow를 실행하며 뽑아낸 각종 Metrics들을 확인할 수 있습니다.
이같은 관측 가능성(Observability)의 확보는 Dataflow와 같은 관리형 서비스의 장점이라고 할 수 있습니다.
이러한 기능을 통해 사용자는 따로 환경을 구성하지 않아도 관리형 서비스가 제공하는 Metrics를 보며 작업의 상태를 체크할 수 있습니다.
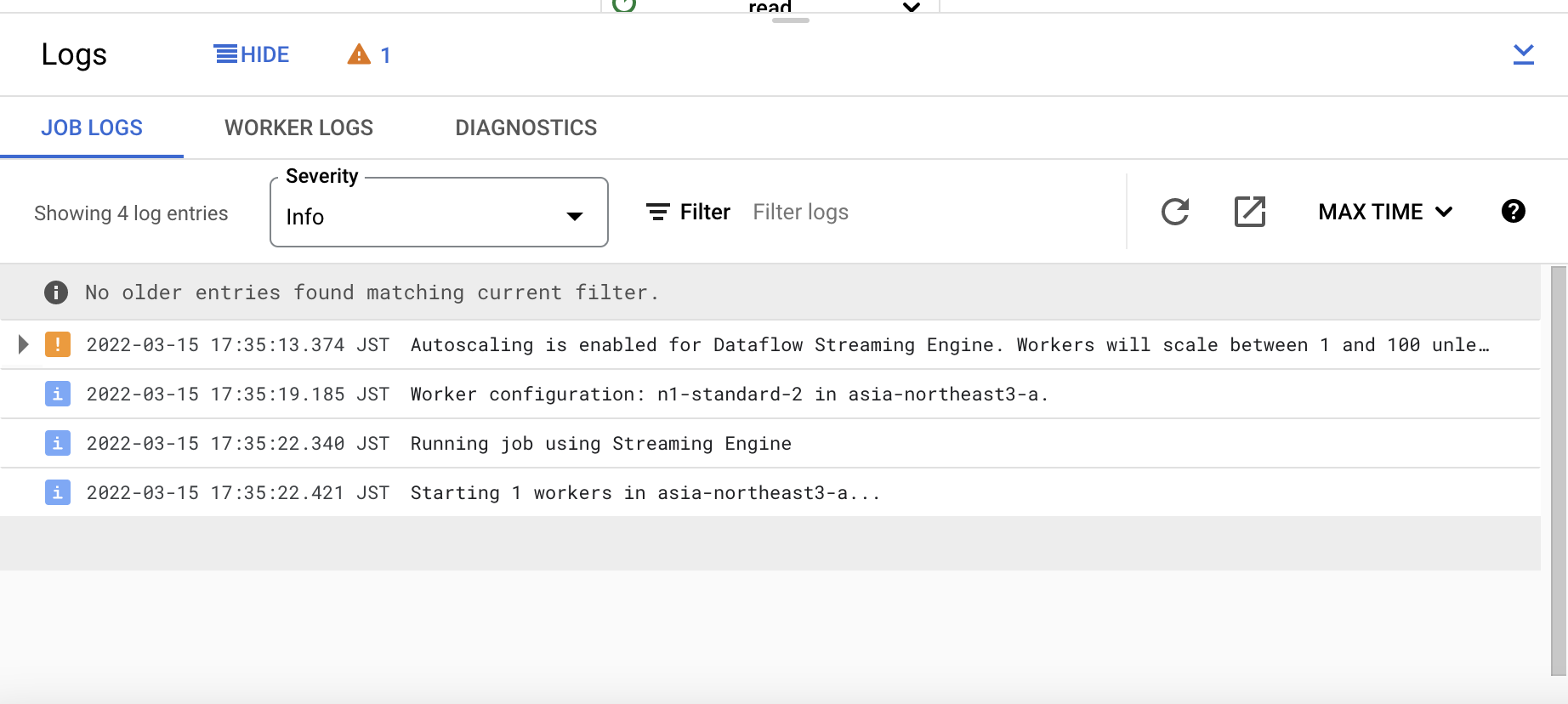
하단의 JOB LOGS 탭에서는 로깅과 관련된 정보를 볼 수 있습니다.
위의 Metric과 마찬가지로 Log 또한 자동으로 수집해주며, 생성된 관측 가능성 데이터들은 GCP의 관리형 스토리지에 저장되기 때문에 데이터의 용량이나 관리에 신경쓰지 않아도 됩니다.
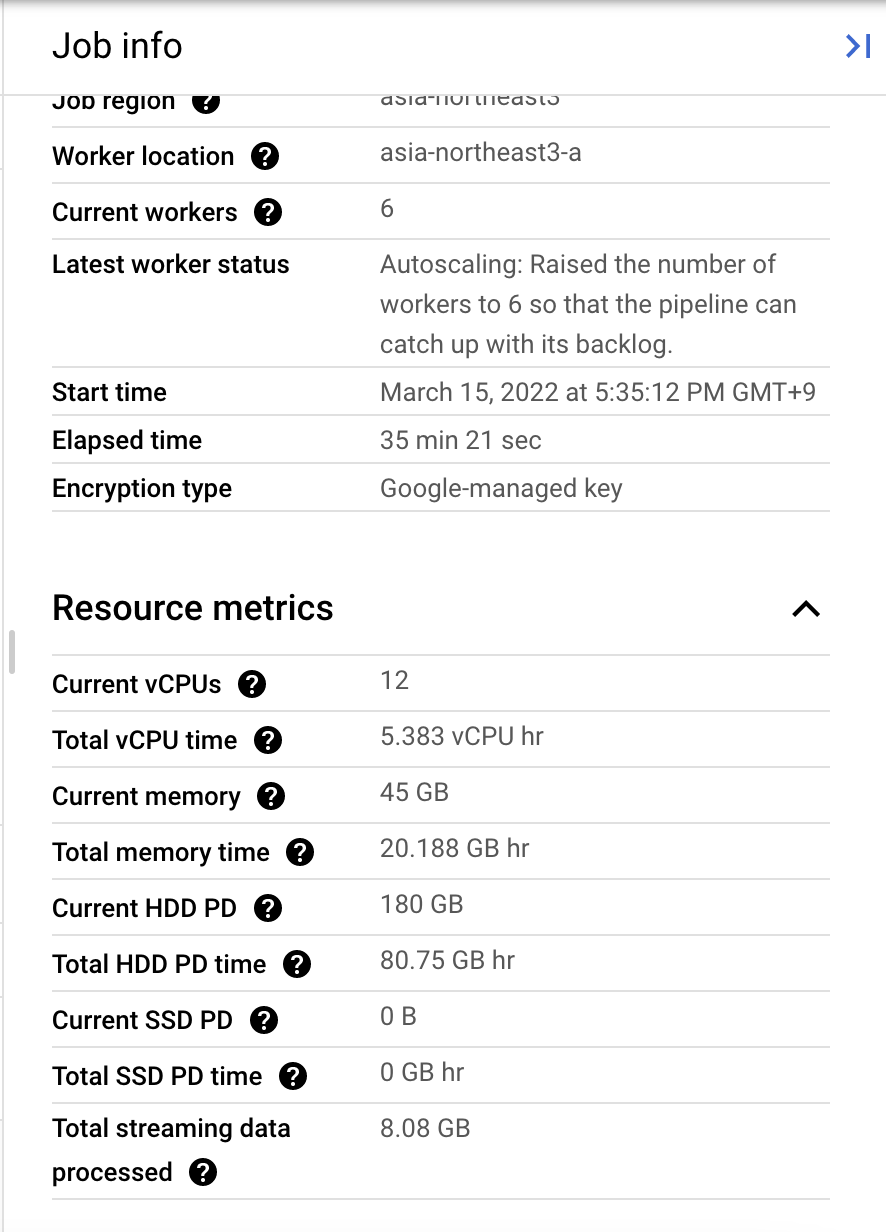
우측의 JOB INFO 탭에서는 작업의 내용, 리소스 사용량 등의 대략적인 정보를 볼 수 있습니다.
리소스 관련해서 제공되는 기능 중 하나가 Autoscaling 기능인데요. Dataflow는 작업에 더 많은 리소스가 필요하다고 판단하는 순간 Vertical scaling, 혹은 Horizontal scaling을 통해 크기를 자동으로 확장하는 기능을 가지고 있습니다.
이 기능으로 사용자는 작업의 리소스 사용량에 크게 구애받지 않을 수 있다는 장점이 있습니다.
5. 마무리
지금까지 Apache beam이 무엇인지, 또 어떻게 사용할 수 있는지 간단하게 알아봤습니다.
정리하자면 Apache beam은 Steaming 및 Batch 작업을 지원하는 오픈소스 도구이며, 자신만의 로직을 사용해 간단하게 데이터 파이프라인을 생성할 수 있는 엔진입니다.
로컬 환경에서 Apache beam 작업을 구동할 수도 있지만, GCP의 Dataflow라는 Cloud 환경으로 작업을 제출할 수 있기 때문에 관리형 및 클라우드 서비스 기반의 기능을 사용해 파이프라인을 생성할 수도 있었습니다.
그 밖에도 Apache beam과 관련된 개념과 내용들이 많지만 자세한 내용은 공식 도큐먼트를 참고하시면 될 것 같습니다.
이 포스팅을 보신 분들이 Apache beam에 대해 많은 정보를 가져가셨으면 합니다.
Apache Beam
Try Beam Playground Beam Playground is an interactive environment to try out Beam transforms and examples without having to install Apache Beam in your environment. You can try an Apache Beam examples at Beam Playground (Beta).
beam.apache.org
'Dev' 카테고리의 다른 글
| Go로 커맨드를 실행할 수 있는 CLI를 구현해보자 (With Cobra) (1) | 2023.06.26 |
|---|---|
| Gradle을 이용해서 Springboot + GCP API 연동한 Java 프로젝트 생성 및 배포하기 (2) | 2022.02.12 |
| Onclick vs AddEventListener 어떤 것을 사용해야 할까? (2) | 2020.03.27 |
| Django 의 Password Validation 삽질기 (1) | 2020.03.24 |
| Node.js + MongoDB 로 이미지 웹 만들어보기 (2) (0) | 2020.03.12 |
Apache beam은 Streaming 및 Batch성 데이터 작업을 지원하는 오픈소스 엔진입니다.
"beam"이라는 이름이 Batch에서 "B"를, Streaming에서 "eam"을 가져와 합친 단어라는 데서 Apache beam이 지향하고자 하는 바가 명확히 보입니다.
Apache beam은 단일 프로그래밍 모델로 Batch 와 Streaming 데이터 작업을 지원하며, 이렇게 작업한 모델은 다양한 런타임에서 구동할 수 있다는 다양한 활용성이 장점입니다.
현재 데이터 파이프라인 생성을 지원하는 언어는 Python, Java 및 Go가 있습니다. 간단히 Apache beam을 사용해보고자 한다면 아래 링크의 Beam Playground에서 웹 인터렉티브 환경을 이용해볼 수도 있습니다.
https://play.beam.apache.org/?example=SDK_JAVA/PRECOMPILED_OBJECT_TYPE_EXAMPLE/MinimalWordCount
Apache Beam Playground
play.beam.apache.org
이번 포스팅에서는 Apache beam으로 Batch 및 Streaming 데이터 파이프라인을 생성해보고 이를 로컬 및 Cloud 런타임인 GCP의 dataflow에서 실행해보도록 하겠습니다.
1. Apache beam의 구조
Apache beam은 위에서 말했듯이, Batch 및 Streaming 데이터 작업을 지원하는 단일 엔진입니다. 이는 위 이미지에서도 잘 나타나있습니다.
데이터 처리 작업의 상당 부분을 추상화했기 때문에 사용자 입장에서는 데이터가 연속적으로 들어오거나(Unbounded), 혹은 불연속적으로 들어오는지(Bounded)에 상관 없이 편리하게 처리 모델을 생성할 수 있습니다.
이를 가능케 하기 위해 Apache beam에서 사용하는 개념이 있습니다. 여러 중요한 개념들이 있지만 본 포스팅에서는 Apache beam의 근간을 이루는 몇 가지만 보도록 하겠습니다.
1. Pipeline
Pipeline은 Apache beam을 이용해 처리하려는 데이터 처리 작업의 총체를 말합니다.
우리는 Pipeline을 정의함으로써 데이터를 처리하고 내보내는 단일한 데이터 파이프라인을 생성할 수 있습니다.
이를 통해 각각 존재하는 데이터 처리 로직을 Pipeline이라는 구조로 묶어줄 수 있습니다.
2.PCollection
PCollection은 우리가 처리하고자 하는, 혹은 처리하고 난 뒤의 데이터셋을 말합니다.
Apache beam은 batch와 Streaming 데이터를 처리할 수 있기 때문에 PCollection 또한 연속적, 혹은 불연속적으로 들어오는 데이터 모두 포함할 수 있습니다.
3.PTransform
PTranform은 데이터를 어떻게 처리하고자 하는지를 정의한 로직을 말합니다.
보통 PCollection으로 들어오는 데이터셋을 PTransform으로 처리한 뒤, 다시 PCollection으로 내보내는 일련의 과정을 데이터 파이프라인으로 정의합니다.
위 개념들을 이미지로 도식화해보면 위와 같습니다.
이미지에서 볼 수 있듯이 Apaceh beam의 데이터 파이프라인은 Pipeline이라는 데이터 파이프라인을 정의한 뒤, 원하는 데이터를 Pcollection으로 입력하고, 이를 PTransform으로 처리하면, 이로 인해 생성된 PCollection에서 원하는 데이터를 뽑아내는 일련의 과정으로 이루어져 있다는 것을 알 수 있습니다.
2. Apache beam 사용해보기
이제 본격적으로 Apache beam을 사용해보면서 어떻게 데이터 파이프라인을 생성하는지 알아보겠습니다
본 포스팅은 Apache beam이 지원하는 3가지 언어 중 Python을 사용하는 것으로 작성하였습니다.
1. 환경 구성
우선 Apache beam을 로컬에서 사용하기 위한 Python 환경을 설정해보겠습니다.
현재 Apache beam이 공식적으로 지원하는 Python SDK의 Python 버전은 3.6, 3.7, 3.8이며 PIP 버전은 7.0 이상 입니다.
이 버전 중 하나로 Python을 설치합니다. 본 포스팅에서는 Python 3.8.10, PIP 버전은 21.2.3, MACOS에서 진행했습니다.
기본 환경을 구성하기 위해 아래 명령어를 실행합니다.
|
1
2
3
|
python -m venv /path/to/directory
. /path/to/directory/bin/activate
pip install 'apache-beam[gcp]'
|
cs |
먼저 Python 가상 환경을 생성하기 위해 python -m venv ... 명령어를 실행합니다. "/path/to/directory" 부분을 원하는 경로로 수정합니다.
다음으로 생성된 venv 가상 환경을 실행합니다.
그 후 pip 패키지 매니저를 사용해 apache-beam[gcp] 패키지를 설치합니다. 본 패키지는 기본 apache-beam에 GCP를 위한 추가 dependancies를 설치하는 패키지입니다.
이번 포스팅에서는 GCP의 bigQuery 및 Pub/sub에서 데이터를 가져오고, Apach beam의 Cloud runtime인 Dataflow를 사용해볼 것이기 때문에 GCP 관련 dependancies도 설치해줍니다.
이후 pip list 명령어로 설치한 dependancies를 확인할 수 있습니다.
2. 기본 동작
Python 환경을 성공적으로 구성했다면 이제 IDE를 켜고 Python 코드를 작성해봅시다.
아래 코드를 바탕으로 Python 파일을 생성합니다. 이 코드는 Apache beam의 가장 기본적인 형태라고 할 수 있습니다.
|
1
2 3 4 5 6 7
|
import apache_beam as beam
with beam.Pipeline() as p: (p | beam.Create(['Hello Beam'])
| beam.Map(print))
|
cs |
Output :
Hello Beam
3번 라인의 with beam.Pipeline() as p: 는 apache beam의 데이터 파이프라인을 정의하는 부분입니다. 위에서 설명한 Apache beam의 Pipeline은 이런 방식으로 생성됩니다.
5번 라인의 p | ... 부터 Pipeline이 처리할 로직의 순서인 step을 정의할 수 있습니다.
Step은 파이프("|")로 구분하며 각 Step은 PCollection이나 PTransform같은 데이터 처리 로직을 정의해 사용할 수 있습니다
본 파이프라인에서는 첫번째 Step으로 PCollection의 일부인 데이터 생성 메소드 "Create"를 사용해 데이터를 생성했으며, 이로 생성된 데이터를 두번째 Step으로 PTransform의 일종인 "Map"을 사용해 Print했습니다.
이렇게 Apache beam의 모든 데이터 파이프라인은 p | STEP_1 | STEP_2 | ... 처럼 Pipeline을 생성한 뒤 그 내부에 각 Step을 정의하는 구조로이루어져 있습니다.
3. Element 단위 작업
다룰 수 있는 가장 작은 데이터 단위를 Apache beam에서는 Element라고 표현합니다.
Element 단위 작업이란 가장 작은 단위의 데이터인 Element를 기반으로 처리할 수 있는 작업이라는 것이죠.
Apache beam에서 대표적인 Element 단위 작업으로는 Map과 ParDo가 있습니다.
먼저 Map을 사용해보겠습니다. Map은 가장 간단하게 사용할 수 있는 Element 단위의 작업입니다.
|
1
2
3
4
5
6
7
8
|
import apache_beam as beam
with beam.Pipeline() as p:
(p | beam.Create([10, 20, 30, 40, 50])
| beam.Map(lambda num: num * 5)
| beam.Map(print))
|
cs |
Output :
50
100
150
200
250
위 코드는 7번 라인의 beam.Map(lambda num: num *5)로 Map을 정의해 사용한 데이터 파이프라인입니다.
[10, 20, 30, 40, 50] 으로 이루어진 데이터셋을 Element 단위, 즉 각 요소 단위로 5씩 곱하는 간단한 로직을 구현했습니다.
그 결과로 반환되는 데이터는 각 Element에 5를 곱한 [50, 100, 150, 200, 250]이 되는 것을 알 수 있습니다.
이렇게 Map에 Lambda 함수를 정의해서 간단한 데이터 처리 작업을 정의할 수 있습니다.
또 다른 Element 단위 작업으로 ParDo가 존재합니다. ParDo는 함수를 직접 정의해서 사용할 수 있는 작업입니다.
ParDo는 사실상 거의 모든 데이터 파이프라인 작업은 ParDo로 모두 처리할 수 있다고 할 정도로 범용성 높고 간단한 작업입니다.
아래는 ParDo를 사용한 데이터 파이프라인입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import apache_beam as beam
class MultiplyByTenDoFn(beam.DoFn):
def process(self, element):
yield element * 10
with beam.Pipeline() as p:
(p | beam.Create([1, 2, 3, 4, 5])
| beam.ParDo(MultiplyByTenDoFn())
| beam.Map(print))
|
cs |
Output:
10
20
30
40
50
13번 라인에서 볼 수 있듯이 ParDo는 원하는 데이터 처리 로직 Class를 정의해서 사용할 수 있습니다.
4번 라인에서 정의한 데이터 처리 로직인 MultiplyByTenDoFn을 불러와 각 Element에 10을 곱한 것을 볼 수 있습니다.
주의할 것은 함수가 반환할때 사용하는 키워드는 return이 아닌 yield여야 한다는 것입니다. ParDo는 단일 Element 별로 처리하는 작업이기 때문에 제너레이터를 반환해야 합니다.
현재 Apache beam에는 위의 두 작업 말고도 수 많은 데이터 처리 방식을 지원하는 작업을 지원하고 있습니다.
모든 작업을 이 포스팅에서 다루지는 못하지만, 가장 기초적이고 범용성 높은 두 작업을 이해하면 나머지 작업도 이해하기 어렵지 않을 것입니다.
지원하는 모든 작업의 리스트는 공식 문서를 참고해 주세요.
https://beam.apache.org/documentation/programming-guide/
Beam Programming Guide
beam.apache.org
4. 데이터셋 입출력
데이터를 처리하는 로직도 중요하지만 어떤 데이터셋을 가져와서 어디로 보낼지 정의하는 것 또한 실질적인 관점에선 더 중요한 작업입니다.
Apache beam은 일반 Text 파일부터 Database, Message bus, Object storage까지 다양한 방식의 데이터 IO를 지원하고 있습니다.
사용하고자 하는 데이터셋이 Apache beam의 built-in IO에 존재하지 않다면 Custom IO Connector를 만들어 사용할 수도 있습니다.
현재 Apache beam이 지원하는 모든 IO의 목록은 공식 문서에서 볼 수 있습니다.
https://beam.apache.org/documentation/io/built-in/
Built-in I/O Transforms
Built-in I/O Transforms This table contains the currently available I/O transforms. Consult the Programming Guide I/O section for general usage instructions. Adapt for: File-based These I/O connectors involve working with files. FileSystem Beam provides a
beam.apache.org
이번 포스팅에서는 Apache beam이 공식적으로 지원하는 IO 중 GCP의 Message bus인 Pub/Sub과 DW인 bigQuery를 데이터셋으로 사용해보겠습니다.
더 정확히는 GCP에서 Pubsub으로 제공하는 Public 스트리밍 데이터셋인 "taxirides-realtime"(이름에서 유추할 수 있듯이 실시간 택시 정보 데이터입니다.)을 받아서 bigQuery 테이블로 저장하는 데이터 파이프라인을 생성해보겠습니다.
이 작업은 GCP 프로젝트를 사용할 수 있는 계정이 존재하고 작업 환경에 CloudSDK가 설치되어 있음을 가정하고 진행합니다.
아래 코드를 사용합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import apache_beam as beam
import apache_beam.transforms.window as window
import json
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.io.gcp.internal.clients import bigquery
from typing import Any, Dict
project = PROJECT_ID table = TABLE_NAME bucket_url = gs://GCS_BUCKET output_table_spec = bigquery.TableReference(
projectId=project,
datasetId=table,
tableId='taxirides_output_table'
)
SCHEMA = {
'fields': [
{'name': 'ride_id', 'type': 'STRING', 'mode': 'REQUIRED'},
{'name': 'point_idx', 'type': 'INTEGER', 'mode': 'NULLABLE'},
{'name': 'longitude', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'timestamp', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'},
{'name': 'meter_reading', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'meter_increment', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'ride_status', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'passenger_count', 'type': 'INTEGER', 'mode': 'NULLABLE',}
]
}
options = PipelineOptions(streaming=True, project=project)
def parse_json_message(message: str) -> Dict[str, Any]:
row = json.loads(message)
return {
"ride_id": row['ride_id'],
"point_idx":row['point_idx'],
"longitude":row['longitude'],
"timestamp":row['timestamp'],
"meter_reading":row["meter_reading"],
"meter_increment":row['meter_increment'],
"ride_status":row["ride_status"],
"passenger_count":row["passenger_count"]
}
def run():
with beam.Pipeline(options=options) as p:
records = (p | "read" >> beam.io.ReadFromPubSub(
topic='projects/pubsub-public-data/topics/taxirides-realtime').with_output_types(bytes)
| "UTF-8 bytes to string" >> beam.Map(lambda msg: msg.decode("utf-8"))
| "Parse JSON messages" >> beam.Map(parse_json_message)
| "Fixed-size windows" >> beam.WindowInto(window.FixedWindows(60, 0))
)
write = records | "write" >> beam.io.WriteToBigQuery(table=output_table_spec,
schema=SCHEMA,
custom_gcs_temp_location='bucket_url',
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
if __name__ == '__main__':
run()
|
cs |
위 코드에서 PROJECT_ID, TABLE_NAME, GCS_BUCKET 부분을 각각 GCP 프로젝트 ID, bigQuery 테이블 이름, GCS 버켓 이름으로 치환합니다.
길이 상 위 코드를 단락 별로 나누어서 분석해보겠습니다.
1. output_table_spec ..
|
1
2
3
4
5
|
output_table_spec = bigquery.TableReference(
projectId=project,
datasetId=table,
tableId='taxirides_output_table'
)
|
cs |
bigQuery 테이블에 쓰기 작업을 하기 위해 필요한 요소 중 bigquery 테이블 규격을 정의하는 코드입니다.
Apache beam의 bigquery IO에서 TableReference()를 사용하면 쉽게 bigQuery 테이블을 정의할 수 있습니다.
2. SCHEMA = ...
|
1
2
3
4
5
6
7
8
9
10
11
12
|
SCHEMA = {
'fields': [
{'name': 'ride_id', 'type': 'STRING', 'mode': 'REQUIRED'},
{'name': 'point_idx', 'type': 'INTEGER', 'mode': 'NULLABLE'},
{'name': 'longitude', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'timestamp', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'},
{'name': 'meter_reading', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'meter_increment', 'type': 'FLOAT', 'mode': 'NULLABLE'},
{'name': 'ride_status', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'passenger_count', 'type': 'INTEGER', 'mode': 'NULLABLE',}
]
}
|
cs |
마찬가지로 bigQuery 테이블에 쓰기 작업을 하기 위해 필요한 요소 중 bigQuery 테이블 스키마를 정의하는 코드입니다.
Pub/sub 메세지를 통해서 오는 JSON 포맷과 동일하거나 "NULLABLE" mode의 칼럼이 생략된 스키마를 정의해야 합니다.
일반적인 구조의 bigQuery 테이블 스키마는 위와 같이 name, type, mode의 3개 요소를 정의할 수 있습니다.
단 Nested나 Repeated 칼럼의 경우 중첩된 구조를 사용해서 스키마를 구성해야 한다는 점에 주의해야 합니다.
3. options = ...
|
1
|
options = PipelineOptions(streaming=True, project=project)
|
cs |
Apache beam의 PIpeline에 사용할 Option을 지정하는 코드입니다.
Pub/sub을 통해서 받는 메세지 데이터는 Streaming 데이터이기 때문에, Streaming=True 옵션을 통해서 Streaming 모드로 바꿔줘야 Streaming 데이터를 처리할 수 있습니다.
4. def parse_json_message...
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def parse_json_message(message: str) -> Dict[str, Any]:
row = json.loads(message)
return {
"ride_id": row['ride_id'],
"point_idx":row['point_idx'],
"longitude":row['longitude'],
"timestamp":row['timestamp'],
"meter_reading":row["meter_reading"],
"meter_increment":row['meter_increment'],
"ride_status":row["ride_status"],
"passenger_count":row["passenger_count"]
}
|
cs |
parse_json_message()는 Pipeline의 Map 작업에 사용할 데이터 처리 로직입니다.
json형태로 들어오는 데이터를 딕셔너리 형태로 가공해 반환하는 함수입니다.
딕셔너리의 구조는 이전에 생성한 bigQuery 테이블의 스키마와 동일해야 bigQuery 테이블에 write 시 에러를 반환하지 않습니다.
5. def run(): ...
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def run():
with beam.Pipeline(options=options) as p:
records = (p | "Read from PubSub" >> beam.io.ReadFromPubSub(
topic='projects/pubsub-public-data/topics/taxirides-realtime').with_output_types(bytes)
| "UTF-8 bytes to string" >> beam.Map(lambda msg: msg.decode("utf-8"))
| "Parse JSON messages" >> beam.Map(parse_json_message)
| "Fixed-size windows" >> beam.WindowInto(window.FixedWindows(60, 0))
)
write = records | "Write to bigQuery" >> beam.io.WriteToBigQuery(table=output_table_spec,
schema=SCHEMA,
custom_gcs_temp_location='bucket_url',
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
if __name__ == '__main__':
run()
|
cs |
Apache beam을 사용해 실행하고자 하는 데이터 파이프라인을 정의하는 코드입니다.
전체 파이프라인의 Step은
Read from PubSub -> UTF-8 bytes to string -> Parse JSON messages -> Fixed-size windows -> Write to bigQuery
와 같은 구성으로 이루어져 있는 것을 볼 수 있습니다.
8번 라인의 beam.WindowInto()는 스트리밍으로 들어오는 데이터의 구간을 어떻게 설정할 것이냐를 정의하는 Windowing과 관련된 부분입니다.
현재는 60초 간격으로 고정된 Windowing을 사용하고 있는 것을 볼 수 있습니다.
코드를 실행하면 GCP bigQuery 콘솔에서 아래와 같은 작업 결과를 확인할 수 있습니다.
테이블 내용을 보면 Pub/sub으로 들어오는 데이터가 bigQuery 테이블에 지정한 Schema대로 입력된 것을 볼 수 있습니다.
이번 작업은 Streaming mode로 실행한 Apache beam 작업이기 때문에 지속적으로 테이블에 데이터가 쌓이게 됩니다.
Apache beam에서는 이러한 방식으로 데이터의 입출력을 이용해 데이터 파이프라인을 구성할 수 있습니다.
3. Cloud 환경에서 Apache beam 작업 실행하기
위에서 본 것처럼 지금까지의 Apache beam 작업은 모두 로컬 환경에서 구동했습니다.
로컬 환경에서 구동한다는 말은 즉 환경 구성 및 가용성, 리소스 관리 등을 모두 사용자가 맡아서 처리해야 한다는 뜻이기도 합니다.
때문에 모든 작업을 사용자가 관리해야 하고 작업이 로컬 환경에 종속된다는 단점이 있죠.
이런 단점을 극복할 수 있는 것이 바로 Cloud 환경에서의 작업이라고 할 수 있겠습니다.
Apache beam도 Cloud 환경에서의 작업을 지원하고 있는데요, 그 중에는 Cloud 환경에서 Apache beam 데이터 파이프라인을 구동할 수 있는 Dataflow Runner가 있습니다. Dataflow란 Google Cloud의 관리형 Apache beam 서비스입니다.
이번 장에서는 이 GCP Dataflow를 활용해 Cloud 환경에서 Apache beam 데이터 파이프라인을 구동해보겠습니다.
다음 명령어를 사용해 Apache beam 작업을 Dataflow로 제출합니다.
|
1
2
3
4
5
|
python -m APACHE_BEAM_SCRIPT \
--region DATAFLOW_REGION \
--runner DataflowRunner \
--project PROJECT_ID \
--temp_location gs://STORAGE_BUCKET/tmp/
|
cs |
APACHE_BEAM_SCRIPT : 작업을 실행할 Python 파일을 지정합니다.
DATAFLOW_REGION : Dataflow 작업을 실행할 인스턴스의 리전을 지정합니다.
PROJECT_ID : GCP 프로젝트 ID를 지정합니다.
STORAGE_BUCKET : GCS 버켓을 지정합니다.
커맨드를 실행하고 GCP 콘솔의 Dataflow 화면으로 진입하면 아래와 같이 제출한 작업이 실행되고 있는 것을 볼 수 있습니다.
실행되고 있는 작업을 클릭하면 작업의 세부 사항을 볼 수 있습니다.
Dataflow는 Apache beam이 구동하고 있는 파이프라인을 시각화해주는 기능을 가지고 있습니다. 콘솔 화면의 JOB GRAPH 탭에서 파이프라인의 각 Step이 표현된 것을 볼 수 있습니다.
EXECUTION DETAILS 탭에서는 파이프라인을 실행하며 처리된 데이터들의 Freshness를 그래프로 확인할 수 있습니다.
이를 통해 Dataflow를 통해 처리된 데이터가 언제 들어온 데이터인지 쉽게 확인할 수 있습니다.
JOB METRICS 탭에서는 Dataflow를 실행하며 뽑아낸 각종 Metrics들을 확인할 수 있습니다.
이같은 관측 가능성(Observability)의 확보는 Dataflow와 같은 관리형 서비스의 장점이라고 할 수 있습니다.
이러한 기능을 통해 사용자는 따로 환경을 구성하지 않아도 관리형 서비스가 제공하는 Metrics를 보며 작업의 상태를 체크할 수 있습니다.
하단의 JOB LOGS 탭에서는 로깅과 관련된 정보를 볼 수 있습니다.
위의 Metric과 마찬가지로 Log 또한 자동으로 수집해주며, 생성된 관측 가능성 데이터들은 GCP의 관리형 스토리지에 저장되기 때문에 데이터의 용량이나 관리에 신경쓰지 않아도 됩니다.
우측의 JOB INFO 탭에서는 작업의 내용, 리소스 사용량 등의 대략적인 정보를 볼 수 있습니다.
리소스 관련해서 제공되는 기능 중 하나가 Autoscaling 기능인데요. Dataflow는 작업에 더 많은 리소스가 필요하다고 판단하는 순간 Vertical scaling, 혹은 Horizontal scaling을 통해 크기를 자동으로 확장하는 기능을 가지고 있습니다.
이 기능으로 사용자는 작업의 리소스 사용량에 크게 구애받지 않을 수 있다는 장점이 있습니다.
5. 마무리
지금까지 Apache beam이 무엇인지, 또 어떻게 사용할 수 있는지 간단하게 알아봤습니다.
정리하자면 Apache beam은 Steaming 및 Batch 작업을 지원하는 오픈소스 도구이며, 자신만의 로직을 사용해 간단하게 데이터 파이프라인을 생성할 수 있는 엔진입니다.
로컬 환경에서 Apache beam 작업을 구동할 수도 있지만, GCP의 Dataflow라는 Cloud 환경으로 작업을 제출할 수 있기 때문에 관리형 및 클라우드 서비스 기반의 기능을 사용해 파이프라인을 생성할 수도 있었습니다.
그 밖에도 Apache beam과 관련된 개념과 내용들이 많지만 자세한 내용은 공식 도큐먼트를 참고하시면 될 것 같습니다.
이 포스팅을 보신 분들이 Apache beam에 대해 많은 정보를 가져가셨으면 합니다.
Apache Beam
Try Beam Playground Beam Playground is an interactive environment to try out Beam transforms and examples without having to install Apache Beam in your environment. You can try an Apache Beam examples at Beam Playground (Beta).
beam.apache.org
'Dev' 카테고리의 다른 글
| Go로 커맨드를 실행할 수 있는 CLI를 구현해보자 (With Cobra) (1) | 2023.06.26 |
|---|---|
| Gradle을 이용해서 Springboot + GCP API 연동한 Java 프로젝트 생성 및 배포하기 (2) | 2022.02.12 |
| Onclick vs AddEventListener 어떤 것을 사용해야 할까? (2) | 2020.03.27 |
| Django 의 Password Validation 삽질기 (1) | 2020.03.24 |
| Node.js + MongoDB 로 이미지 웹 만들어보기 (2) (0) | 2020.03.12 |