

Kubernetes 플랫폼이 대중화되면서 점점 다양한 워크로드들이 Kubernetes 위에서 실행되고 있습니다.
하지만 DB는 어떨까요? 어쩌면 유연하고 임시적인 Kubernetes 환경에서 내구성과 견고함이 중요한 DB는 언뜻 보기에 적절한 만남이 아닌 것 같아 보입니다.
Statefulset라는 상태 저장을 목적으로 하는 오브젝트를 지원함에도 여전히 DB를 Kubernetes 환경에서 운영하는 것은 비효율적이고 견고해 보이지 않기 때문에 지금도 DB를 Kubernetes 환경에서 운영하는 것에 거부감을 가진 사람들이 많습니다.
하지만 이런 의심의 눈초리와 관계없이 기술은 점점 발전해서 결국은 Operator를 사용해 DB를 운영하는 패턴이 등장해 Kubernetes 환경에서도 DB를 안정적으로 운영할 수 있게 되었습니다.
이번 포스팅에서는 Operator 패턴이 무엇인지, Operator 패턴을 사용해서 DB를 어떻게 운영할 수 있는지 대표적인 오픈소스 DB인 Mysql을 이용해서 살펴보도록 하겠습니다.
1. Operator 패턴이란?
Kubernetes 공식 도큐먼트에 따르면, Operator 패턴을 이렇게 소개하고 있습니다.
오퍼레이터(Operator)는 사용자 정의 리소스를 사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 익스텐션이다. 오퍼레이터는 쿠버네티스 원칙, 특히 컨트롤 루프를 따른다.
중요한 것은 오퍼레이터란 결국 사용자 정의 리소스를 사용해서 쿠버네티스 요소들을 관리하는 역할을 한다는 것입니다.(관리는 컨트롤 루프 원칙에 따라)
왜 사용자 정의 리소스를 사용할까? 이는 Kubernetes가 가지고 있는 오브젝트 한계를 확장하기 위해서입니다.
왜 kube-controller 등의 컴포넌트가 있는데 또 관리해야 할 주체(오퍼레이터)가 필요한걸까? 이는 기존 쿠버네티스가 관리하지 못했던 것들을 관리할 수 있게 하기 위해서입니다.
아래 그림처럼 오퍼레이터는 사용자 정의 리소스를 지속적으로 주시하고 있다가 변경 등의 이벤트가 발생하면 그에 맞추어 실제 Kubernetes 오브젝트를 조절하는 역할을 합니다.
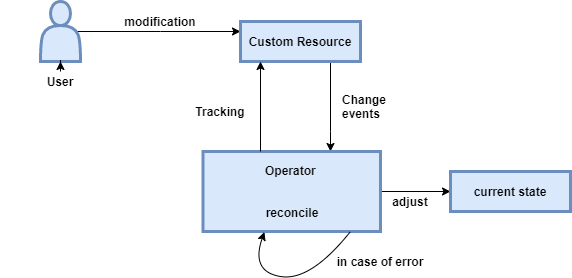
원래라면 User가 직접 Kubernetes 오브젝트를 목적에 따라 변경해야 했지만, DB나 모니터링 시스템 등 오브젝트들이 복잡하게 엮여있는 워크로드에서는 User가 오브젝트를 관리하기 쉽지 않기 때문에 이를 사용자 정의 리소스로 추상화해 관리하기 쉽도록 만든 것입니다.
정리하자면 Operator 패턴은 기존 Kubernetes에서 관리할 수 없었던 것들을 오퍼레이터라는 요소의 추가로 관리의 범위를 사용자 정의 리소스까지 확장해 관리성과 자동화를 향상하도록 등장한 개념입니다.
이 Operator 패턴을 사용하면 Statefulset로 이루어진 DB 클러스터와 Deployment로 이루어진 DB 라우터 등의 복잡한 구성요소들을 하나의 사용자 정의 리소스로 추상화시켜 Kubernetes 환경에서 DB를 간편하고 안전하게 관리할 수 있습니다.
이 Operator 패턴은 수많은 워크로드에서 사용할 수 있습니다.
현재 사용 가능한 Operator들의 모음은 Operatorhub.io 사이트에서 확인할 수 있는데요. 확인해보면 빅데이터, CI/CD, 모니터링 등 수많은 영역의 워크로드를 Operator 패턴으로 운영할 수 있는 것을 알 수 있습니다.
OperatorHub.io | The registry for Kubernetes Operators
operatorhub.io
사이트의 왼쪽 탭을 보면 워크로드별, 제공자 별, 마지막으로 Capability level이라는 필터로 Operator들을 분류할 수 있는데요.
Capability level이란 Operator 기술의 성숙도를 말합니다.
순서대로 Basic Install -> Seamless Upgrades -> Full Lifecycle -> Deep Insights -> Auto Pilot 순으로 기술의 성숙도가 높다는 것을 의미합니다.
가령 "Basic Install" Level은 자동화된 애플리케이션 프로비저닝과 설정 관리를 제공하지만, "Auto Pilot" Level은 수직/수평 확장, 자동 설정 튜닝, 이상 감지, 스케쥴링 튜닝 등의 고급 기능까지 제공해 자동화 수준이 더 높다는 것을 알 수 있습니다.
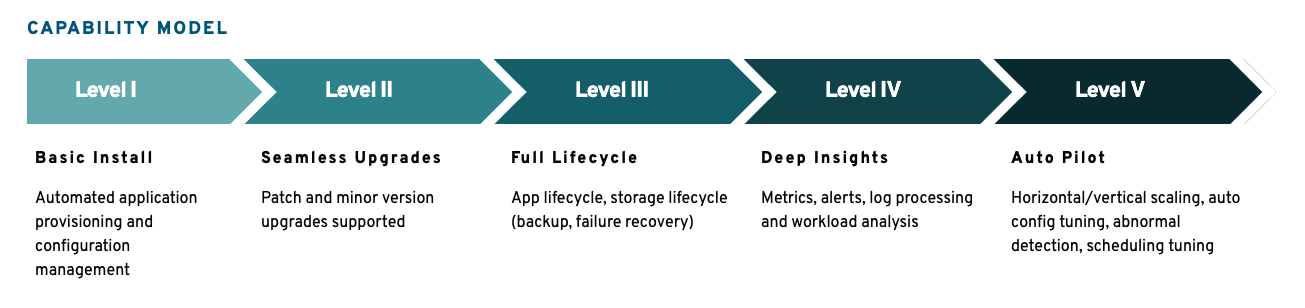
Operator 패턴을 사용하고자 할때 이 같은 성숙도 Level을 참고하면 대략적으로 Operator가 제공하는 자동화 수준을 가늠할 수 있습니다.
2. Mysql Operator란?
이번 시간에 알아볼 패턴은 DB, 그 중에서도 Mysql DB를 Operator 패턴으로 운영하는 방법에 대해 알아보는 것이기 때문에 Mysql DB Operator에 대해서 집중 탐구해보도록 하겠습니다.
안타깝게도 현재 Mysql Operator는 operatorhub.io에 등록되어 있지 않기 때문에 성숙도를 확인할 수는 없었습니다.
하지만 mysql operator는 Orale Mysql이 직접 운영하는 Operator이기 때문에 앞으로의 지원이 기대되는 부분이 있습니다.
mysql operator의 공식 도큐먼트는 아래 링크에서 찾을 수 있습니다.
https://dev.mysql.com/doc/mysql-operator/en/
MySQL :: MySQL Operator for Kubernetes Manual
dev.mysql.com
공식 도큐에 의하면 Mysql Operator for Kubernetes를 다음과 같이 소개하고 있습니다.
The MySQL Operator for Kubernetes is an operator focused on managing one or more MySQL InnoDB Clusters consisting of a group of MySQL Servers and MySQL Routers. The MySQL Operator itself runs in a Kubernetes cluster and is controlled by a Kubernetes Deployment to ensure that the MySQL Operator remains available and running.
Mysql Operator는 Mysql 서버와 Mysql 라우터로 이루어진 Mysql InnoDB 클러스터를 관리해준다고 언급되어 있습니다.
여기서 Mysql operator가 추상화해서 관리하는 오브젝트는 바로 Mysql InnoDB 클러스터임을 알 수 있습니다.
즉 Mysql operator는 InnoDB 클러스터라는 추상화된 사용자 정의 리소스로 Mysql 서버와 라우터들의 관리를 자동화하고 간편하게 만들어주는 역할을 합니다.
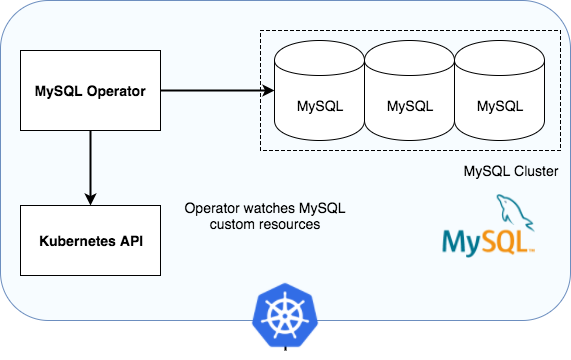
아래는 Mysql operator를 사용한 Kubernetes 환경의 아키텍쳐 다이어그램입니다.
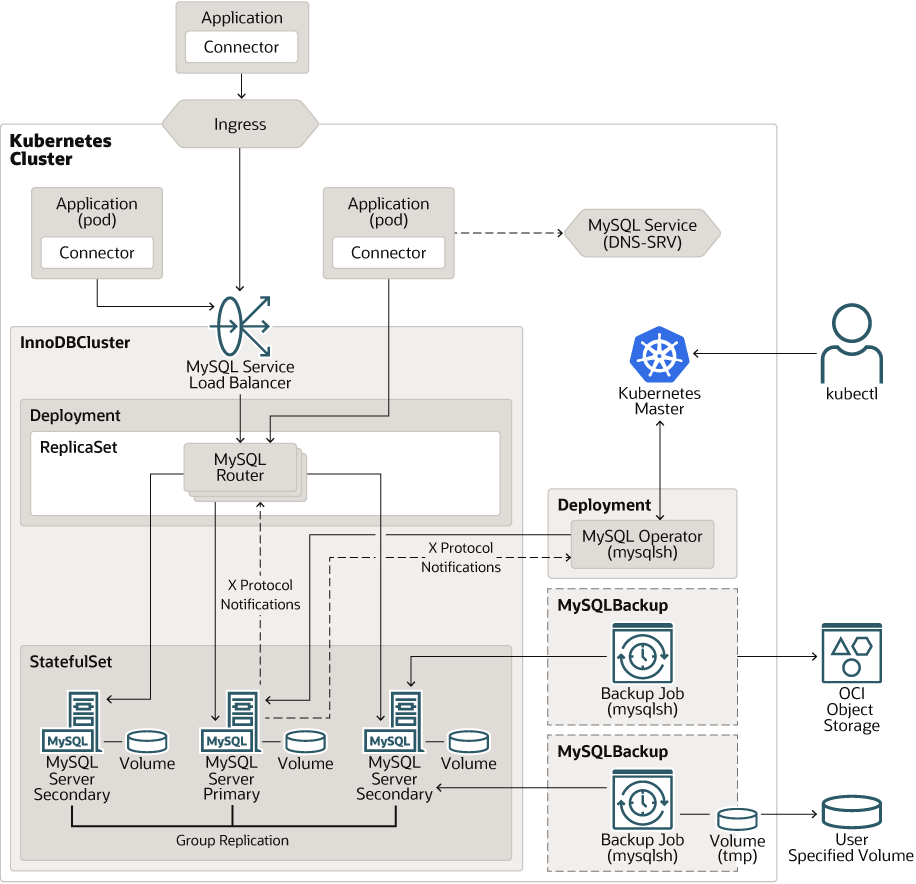
- Deployment로 관리되는 Mysql Router
Mysql 라우터는 Mysql 서버들 중 작업을 실행할 서버를 고르는 상태비저장(Statless) 애플리케이션입니다. DB 인스턴스를 캐시하여 라우팅할 인스턴스를 관리합니다. Mysql 라우터는 클러스터의 스케일에 따라 Deployment의 레플리카 개수를 조절하는 것으로 수평적 확장(Horizontal scaling)할 수 있습니다. - Replicaset으로 관리되는 Mysql Server instances
Mysql 서버는 실제 DB역할을 하게 되는 서버 인스턴스의 그룹입니다. 클러스터의 복제 방식은 Single-Primary mode와 Multi-Primary mode라는 2가지 Replication 모드 중 하나를 선택할 수 있습니다. Single-Primary mode는 전통적인 Master-Slave(이제 이런 표현은 사용하면 안되지만..) 구조의 복제 방식이며, Multi-Primary mode는 Mysql 8.0 버전에 등장한 Group Replication 복제 방식을 사용해 단방향 복제가 아닌 양방향 복제를 수행할 수 있습니다. - Deployment로 관리되는 Mysql Operator
위의 Mysql 서버와 Mysql 라우터들을 관리하는 Operator입니다. Deployment로 관리되며 Operator가 InnoDBCluster, Mysqlbackup 등의 사용자 정의 리소스를 통해 각각 서버 클러스터와 서버 백업을 추상화해 관리해줍니다.
3. Mysql Oprerator 설치해보기
Mysql Operator에 대해 알아보았으니 이제 실제로 Kubernetes 환경에 Mysql Operator를 구성해보겠습니다.
설치는 Helm으로 진행하는 방법과 Manifest를 직접 적용하는 방법 2가지를 사용할 수 있습니다.
이번 포스팅에서는 첫번째 방법인 Helm 차트를 사용해 Mysql Operator를 설치해보겠습니다.
Kubernetes를 구성한 환경에서 다음 명령어로 mysql-operator Helm 레포를 추가합니다.
|
1
2
|
helm repo add mysql-operator https://mysql.github.io/mysql-operator/
helm repo update
|
cs |
다음으로 mysql-operator 네임스페이스에 Mysql operator를 설치합니다.
|
1
2
|
helm install my-mysql-operator mysql-operator/mysql-operator \
--namespace mysql-operator --create-namespace
|
cs |
설치 후에는 아래와 같이 Deployment 하나와 ClusterIP 서비스 하나가 생성된 것을 확인할 수 있습니다.
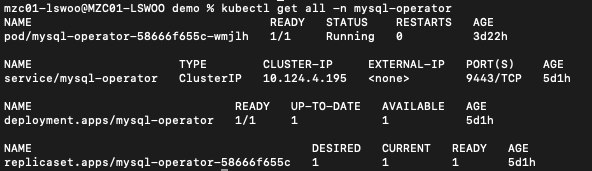
이제 설치한 Mysql Operator를 사용해서 DB 클러스터를 생성해보겠습니다. DB 클러스터는 InnoDBClusters라는 CRD(Custom Resource Definition)으로 생성할 수 있습니다.
InnoDBCluster 또한 Helm 차트를 사용한 방식과 Manifest를 직접 적용하는 방식으로 설치할 수 있습니다.
이번 포스팅에서는 Helm 차트를 사용해서 InnoDBCluster를 생성해보겠습니다. 아래 명령어를 실행해 mysql-cluster 네임스페이스에 Innodbcluster를 설치합니다.
|
1
|
helm install mycluster mysql-operator/mysql-innodbcluster --set credentials.root.password='PASSWORD' --set tls.useSelfSigned=true --namespace mysql-cluster --create-namespace
|
cs |
명령어를 실행한 뒤에는 다음과 같이 DB 클러스터 역할을 하는 Statefulset 1개와 ClusterIP와 Headless Service 1개씩, 그리고 Mysql 라우터 역할을 하는 Deployment 하나를 생성하는 것을 확인할 수 있습니다.
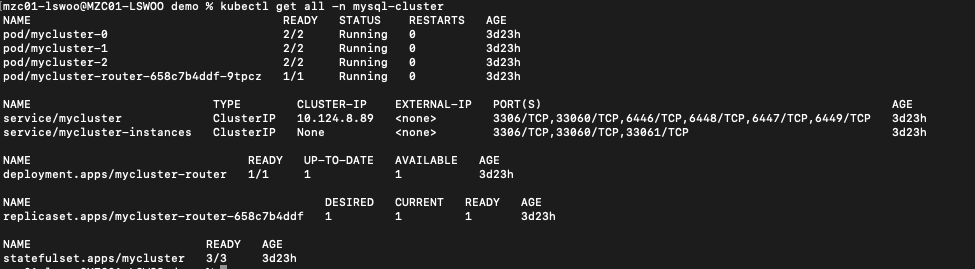
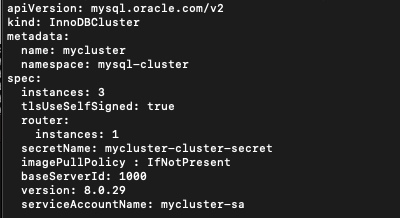
그리고 위의 오브젝트들을 묶어서 추상화한 InnoDBCluster라는 CR(Custom Resource)이 생성된 것을 확인할 수 있습니다.
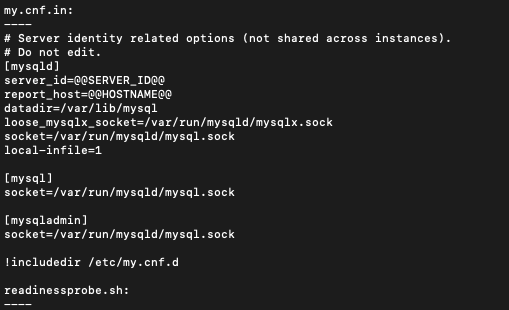
"CLUSTER_NAME-initconf" 이름의 Configmap이 생성된 것 또한 확인할 수 있습니다. 이 오브젝트 내의 my.cnf.in 데이터를 수정함으로써 mysql DB의 custom 설정을 넣을 수 있습니다.
지금까지 Helm 차트를 사용해서 mysql-operator와 mysql-innodbcluster 2개의 차트를 Kubernetes에 배포했습니다.
최종적으로 아래 그림과 같은 아키텍쳐로 Kubernetes 환경을 구성할 수 있었습니다.
4. Mysql Operator 사용해보기
이제 Kubernetes 환경에서 Mysql Operator를 활용해 DB Cluster를 구성했으니 DB에 접속해보겠습니다.
DB에 접속하는 방법은 2가지가 존재합니다.
1. mysql-operator를 사용한 Mysql shell 접속
2. Port-forward를 사용한 local 접속
이번 포스팅에서는 DB에 접속하는 2가지 방법 모두 알아보도록 하겠습니다.
추가적으로 mysql 라우터의 라우팅 규칙에 따른 부하분산 양상도 직접 접속을 통해 알아보도록 하겠습니다.
1. mysql-operator를 사용한 Mysql shell 접속
먼저 mysql-operator를 사용한 Mysql shell 접속 방법입니다.
다음 명령어를 사용해 mysql-operator에 접속한 뒤, 설치된 mysqlsh 도구를 실행합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
kubectl exec -n mysql-operator mysql-operator-58666f655c-dskmx -it -- mysqlsh
Cannot set LC_ALL to locale en_US.UTF-8: No such file or directory
MySQL Shell 8.0.29
Copyright (c) 2016, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates.
Other names may be trademarks of their respective owners.
Type '\help' or '\?' for help; '\quit' to exit.
MySQL JS >
|
cs |
정상적으로 실행하면 mysql shell에 접속할 수 있습니다.
mysql shell에서 mysql 헤들리스 서비스를 엔드포인트로 사용하는 접속 명령어를 입력합니다.
가령 아래와 같이 \connect root@mycluster.mysql-cluster.svc.cluster.local:3306 명령어를 사용하여 접속할 수 있습니다.
|
1
2
3
4
5
6
7
|
MySQL JS > \connect root@mycluster.mysql-cluster.svc.cluster.local:3306
Creating a session to 'root@mycluster.mysql-cluster.svc.cluster.local:3306'
Please provide the password for 'root@mycluster.mysql-cluster.svc.cluster.local:3306': ********
Fetching schema names for autocompletion... Press ^C to stop.
Your MySQL connection id is 15383
Server version: 8.0.29 MySQL Community Server - GPL
No default schema selected; type \use <schema> to set one.
|
cs |
이후 비밀번호를 입력하면 Mysql DB에 접속할 수 있습니다.
참고로 모든 헤들리스 서비스의 FQDN(Full Qullified Domain Name)은 Servicename.Namespace.svc.cluster.local입니다.
때문에 mysql-cluster 네임스페이스에 생성한 mycluster 헤들리스 서비스의 FQDN은 "mycluster.mysql-cluster.svc.cluster.local"입니다. 이를 참고해서 접속 엔드포인트 주소에 적으면 됩니다.
이 접근 방법의 장점은 Local 환경에 어떤 Mysql Client 도구가 존재하지 않아도 DB 인스턴스에 접근할 수 있다는 것입니다.
다만 사용할 수 있는 도구가 mysqlsh에 한정된다는 단점이 있지만, mysqlsh가 Mysql에서 내놓은 최신의 Client 도구이기 때문에 적응하면 사용성이 좋을 것 같습니다.
2. Port-forward를 사용한 local 접속
두번째 접속 방법은 port-forward를 사용한 local 접속 방법입니다.
이 방법을 사용하면 mysql-operator Pod를 통해 간접 접속하지 않고도 port-forward를 사용해 Local 환경에서 바로 DB 인스턴스로 접속할 수 있습니다.
다음 명령어를 입력해 port-forwarding을 실행합니다. 노출할 포트는 임의로 지정해도 무방합니다.
|
1
|
kubectl port-forward svc/mycluster 1090:3306
Forwarding from 127.0.0.1:1090 -> 6446 Forwarding from [::1]:1090 -> 6446 |
cs |
port-forwarding이 정상적으로 실행되었으면 원하는 환경에서 지정한 포트로 DB 인스턴스에 접근할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
% mysql -h 127.0.0.1 -uroot -ppassword -P 1090
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 15985
Server version: 8.0.29 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
|
cs |
port-forwarding 작업에서 1090 포트를 노출했기 때문에 -P 플래그로 1090 포트로 접속해야 한다는 점에 주의해야 합니다.
접속 호스트 주소도 "localhost"가 아닌 "127.0.0.1"이어야 합니다. port-forwarding 작업에서 노출한 주소는 127.0.0.1:1090이기 때문입니다.
localhost와 127.0.0.1 접속 차이의 자세한 내용은 아래 링크를 참고 바랍니다.
https://stackoverflow.com/questions/7382602/what-is-the-difference-between-127-0-0-1-and-localhost
What is the difference between 127.0.0.1 and localhost
Assuming the following is defined in .../hosts: 127.0.0.1 localhost What, if any, are the actual differences between using 127.0.0.1 and localhost as the server name, especially when hitting proc...
stackoverflow.com
Port-forwarding을 사용한 접속은 Local 환경에서 준비한 Mysql Client 도구를 그대로 사용할 수 있다는 장점이 있습니다.
다만 도구가 준비되어 있어야 한다는 점 자체가 단점으로 작용할 수도 있겠습니다.
3. Mysql 라우터의 부하분산 규칙
Mysql operator를 이용해서 설치한 InnoDBCluster는 여러 개의 DB 인스턴스로 이루어져 있기 때문에 하나의 인스턴스에 연결을 몰아주는 것이 아닌 연결의 부하 분산(Load Balancing)이 가능합니다.
이 부하 분산의 역할을 하는 것이 Mysql 라우터인데요. Mysql 라우터의 부하 분산 규칙은 접속 포트 별로 다르며 configuration 파일에 자세히 명시되어 있습니다.
configuration은 다음과 같이 mysql 라우터 Pod에 접속 후 /tmp/mysqlrouter/mysqlrouter.conf 파일에서 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
% kubectl exec mycluster-router-658c7b4ddf-7q4jg -it -- /bin/bash
bash-4.4$ cat /tmp/mysqlrouter/mysqlrouter.conf
# File automatically generated during MySQL Router bootstrap
[DEFAULT]
logging_folder=
runtime_folder=/tmp/mysqlrouter/run
data_folder=/tmp/mysqlrouter/data
keyring_path=/tmp/mysqlrouter/data/keyring
master_key_path=/tmp/mysqlrouter/mysqlrouter.key
connect_timeout=5
read_timeout=30
dynamic_state=/tmp/mysqlrouter/data/state.json
client_ssl_cert=/tmp/mysqlrouter/data/router-cert.pem
client_ssl_key=/tmp/mysqlrouter/data/router-key.pem
client_ssl_mode=PREFERRED
server_ssl_mode=AS_CLIENT
server_ssl_verify=DISABLED
unknown_config_option=warning
[logger]
level=INFO
[metadata_cache:bootstrap]
cluster_type=gr
router_id=2
user=mysqlrouter
metadata_cluster=mycluster
ttl=0.5
auth_cache_ttl=-1
auth_cache_refresh_interval=2
use_gr_notifications=0
[routing:bootstrap_rw]
bind_address=0.0.0.0
bind_port=6446
destinations=metadata-cache://mycluster/?role=PRIMARY
routing_strategy=first-available
protocol=classic
[routing:bootstrap_ro]
bind_address=0.0.0.0
bind_port=6447
destinations=metadata-cache://mycluster/?role=SECONDARY
routing_strategy=round-robin-with-fallback
protocol=classic
[routing:bootstrap_x_rw]
bind_address=0.0.0.0
bind_port=6448
destinations=metadata-cache://mycluster/?role=PRIMARY
routing_strategy=first-available
protocol=x
[routing:bootstrap_x_ro]
bind_address=0.0.0.0
bind_port=6449
destinations=metadata-cache://mycluster/?role=SECONDARY
routing_strategy=round-robin-with-fallback
protocol=x
[http_server]
port=8443
ssl=1
ssl_cert=/tmp/mysqlrouter/data/router-cert.pem
ssl_key=/tmp/mysqlrouter/data/router-key.pem
[http_auth_realm:default_auth_realm]
backend=default_auth_backend
method=basic
name=default_realm
[rest_router]
require_realm=default_auth_realm
[rest_api]
[http_auth_backend:default_auth_backend]
backend=metadata_cache
[rest_routing]
require_realm=default_auth_realm
[rest_metadata_cache]
require_realm=default_auth_realm
|
cs |
conf 파일을 확인해보면 6446~6449 4개의 포트가 할당되어 있으며 포트마다 사용하는 라우팅 전략(routing_strategy),프토로콜과 목적지가 각기 다른 것을 알 수 있습니다.
이를 정리해보면 다음과 같습니다.
| Port | Routing Strategy | Destination | Protocol |
| 6446 | first-available | Primary | Classic |
| 6447 | round-robin-with-fallback | Secondary | Classic |
| 6448 | first-available | Primary | X |
| 6449 | round-robin-with-fallback | Secondary | X |
실제로 6446 프로토콜을 통해 DB에 접속해보면 다음과 같이 mycluster-1 하나의 DB 인스턴스에만 지속적으로 접근하는 것을 알 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-1 |
+-------------+
1 row in set (0.41 sec)
mysql> exit;
Bye
mzc01-lswoo@MZC01-LSWOO ~ % mysql -h 127.0.0.1 -uroot -ppassword -P 1090
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 21929
Server version: 8.0.29 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-1 |
+-------------+
1 row in set (0.17 sec)
|
cs |
first-available 전략은 우선 Destination 인스턴스에 접근한 후, 접근에 실패하면 다음 인스턴스로 시도하는 것을 모든 인스턴스를 확인할떄까지 반복하는 전략입니다.

6446 포트의 Destination은 Primary 인스턴스이고, 현재 구성한 InnoDBCluster의 Primary는 "mycluster-1"이기 때문에 mycluster-1에만 접근하는 라우팅 결과가 나온 것입니다.
다음으로 6447 포트로 접근하게 되면 다음과 같이 Secondary 인스턴스인 mycluster-0과 mycluster-2에 Round-Robin 방식으로 부하 분산이 이루어지는 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-0 |
+-------------+
1 row in set (0.58 sec)
mysql> exit;
Bye
mzc01-lswoo@MZC01-LSWOO ~ % mysql -h 127.0.0.1 -uroot -ppassword -P 1090
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 12808
Server version: 8.0.29 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-2 |
+-------------+
1 row in set (0.62 sec)
|
cs |
round-robin-with-fallback 전략은 round-robin 방식으로 다음 Secondary 인스턴스에 접근하는 라우팅 전략입니다. 모든 Secondary 인스턴스가 접근 불가능하면 Primary로 접근을 시도합니다.

6447포트의 Destination은 Secondary이고, 라우팅 전략 또한 Secondary로 접근을 시도하므로 Secondary 인스턴스인 "mycluster-0"과 "mycluster-2"에 차례로 접근하는 라우팅 결과가 나왔습니다.
추가적으로 /tmp/mysqlrouter/data 디렉토리의 data.json 파일에는 mysql 라우터가 캐싱한 DB 인스턴스 정보가 기입되어 있습니다. Mysql 라우터는 이 정보를 기반으로 DB 인스턴스에게 부하를 분산합니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
cat state.json
{
"metadata-cache": {
"group-replication-id": "0de91bde-dd94-11ec-a349-f66752921b1a",
"cluster-metadata-servers": [
"mysql://mycluster-0.mycluster-instances.mysql-cluster.svc.cluster.local:3306",
"mysql://mycluster-1.mycluster-instances.mysql-cluster.svc.cluster.local:3306",
"mysql://mycluster-2.mycluster-instances.mysql-cluster.svc.cluster.local:3306"
]
},
"version": "1.0.0"
|
cs |
4. Single-Primary mode vs Multi-Primary mode
InnoDBCluster의 Replication Mode에는 하나의 Primary와 여러 개의 Secondary 인스턴스로 이루어져 있는 Single-Primary mode와 여러 개의 Primary 인스턴스로 이루어져 있는 Multi-Primary mode가 존재합니다.
Single-Primary mode는 기존에 존재하던 여러 개의 Replica들이 하나의 Primary를 참고해 지속적으로 복제를 수행하는 방식의 replication 모드입니다. 이때 Write 작업은 Primary에 들어오고, Read 작업은 Replica에 들어오게 되어 작업 부하를 분산하게 됩니다. Primary라는 특수한 역할을 가진 인스턴스가 존재하기 때문에 Primary가 존재하지 않을 경우 이를 선출하기 위한 특별한 작업이 필요합니다.
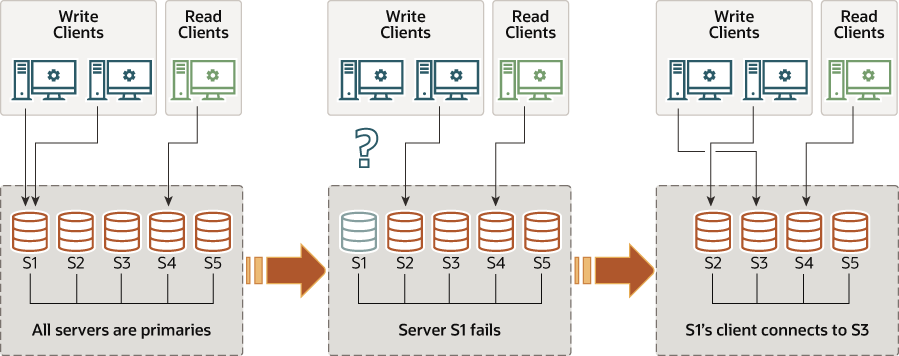
이와 달리 Multi-Primary mode는 말 그대로 그룹의 모든 구성원이 Primary로 동작하는 replication 모드입니다. 모든 구성원이 양방향으로 복제를 수행하기 때문에 Write 작업과 Read 작업을 고루 분산하게 됩니다. 자세한 사항은 아래 그림에서 참고할 수 있습니다. 모든 인스턴스가 특별한 역할을 가지고 있지 않기 때문에 선출과 같은 작업이 필요하지 않습니다.
InnoDBCluster를 Multi-cluster mode로 변경하기 위해서는 mysql 도구에서 다음과 같이 입력합니다.
|
1
2
3
4
5
6
7
8
|
mysql> SELECT group_replication_switch_to_multi_primary_mode();
+--------------------------------------------------+
| group_replication_switch_to_multi_primary_mode() |
+--------------------------------------------------+
| Mode switched to multi-primary successfully. |
+--------------------------------------------------+
1 row in set (1.19 sec)
|
cs |
변경 후 클러스터 멤버의 상태를 확인해보면 아래와 같이 모든 인스턴스의 역할이 Primary로 변경되어 있는 것을 확인할 수 있습니다.

다시 6446 포트로 접속해보면, Single-Primary mode였을 때와 달리 모든 인스턴스에게 연결이 분산되어 부하 분산이 이루어지는 것을 볼 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-0 |
+-------------+
1 row in set (0.20 sec)
mysql> exit;
Bye
mzc01-lswoo@MZC01-LSWOO ~ % mysql -h 127.0.0.1 -uroot -ppassword -P 1090
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 54377
Server version: 8.0.29 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-1 |
+-------------+
1 row in set (0.17 sec)
mysql> exit;
Bye
mzc01-lswoo@MZC01-LSWOO ~ % mysql -h 127.0.0.1 -uroot -ppassword -P 1090
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 31806
Server version: 8.0.29 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-2 |
+-------------+
1 row in set (0.64 sec)
|
cs |
이는 6446포트가 Primary에 우선 접근하려는 first-available 전략을 사용하기 때문인데, Multi-Primary mode에서는 모든 인스턴스가 Primary이기 때문에 모든 인스턴스에 고루 접근하게 되는 것입니다.
5. Mysql Operator Failover 테스트
처음에도 언급했지만 DB를 운영할때 가장 중요한 것은 가용성(availability)일 것입니다.
특히 Kubernetes 환경에서 운영하는 DB라면 다양한 Failure 상황에서도 복구할 수 있는 Failover 능력이 중요할 것입니다.
그렇다면 mysql operator를 사용한 mysql 클러스터가 다양한 Failure 상황에서도 가용성을 유지할 수 있는지 확인해보겠습니다.
1. DB Pod Failure
첫번째로 가정할 상황은 DB Pod의 Failure입니다.
mysql operator가 관리하는 InnoDBCluster의 인스턴스는 Statefulset으로 관리되고, Kubernetes의 Statefulset는 Pod가 중지되거나, 삭제되어도 이를 복구하는 기능이 있기 때문에 Pod의 Failover 기능이 Kubernetes 단에서는 존재합니다.
하지만 실제 DB를 사용하는 User 입장에서도 Failover가 정상적으로 동작하는지 확인해보겠습니다.
다음 명령어를 실행해 의도적으로 DB Pod를 삭제해보겠습니다.
|
1
2
|
% kubectl delete pod mycluster-1
pod "mycluster-1" deleted
|
cs |
그 결과 아래와 같이 잠깐의 Lost connection 이후 다시 정상적으로 다른 인스턴스로 접속된 것을 확인할 수 있었습니다.
접속은 port-forward로 진행했으며, mysql 라우터가 기존 DB Pod의 접속 이상을 감지한 후 자동으로 다른 호스트에 접속한 것으로 보입니다.
이렇게 DB Pod의 Failover는 mysql 라우터를 이용해서 이루어지는 것을 볼 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-1 |
+-------------+
1 row in set (0.34 sec)
mysql> select @@hostname;
ERROR 2013 (HY000): Lost connection to MySQL server during query
No connection. Trying to reconnect...
Connection id: 32247
Current database: *** NONE ***
+-------------+
| @@hostname |
+-------------+
| mycluster-2 |
+-------------+
1 row in set (0.93 sec)
|
cs |
2. Router Pod Failure
다음으로는 중간 Proxy 역할을 하는 mysql 라우터 pod의 Failure입니다.
mysql 라우터는 Deployment로 관리되는 Pod로 배포되어 있으며, 기본적으로 1개의 Replica를 가지고 있습니다.
Failover 능력을 검증하기 위해 Router Pod Failure의 테스트를 실행하기 전에 Replica의 개수를 2개로 늘려놓겠습니다.
mysql 라우터는 Deployment로 관리되는 Pod이기 때문에 DB 인스턴스와 마찬가지로 Pod가 중지 및 삭제되어도 복구되지만, DB User 입장에서는 어떻게 Failover가 동작하는지 살펴보겠습니다.
다음 명령어를 실행해 2개의 mysql 라우터 Pod 중 하나를 삭제합니다.
|
1
2
|
% kubectl delete pod mycluster-router-658c7b4ddf-8k8d2
pod "mycluster-router-658c7b4ddf-8k8d2" deleted
|
cs |
그 결과 다음과 같이 잠깐의 Disconnected 후 다시 접속이 재개되는 것을 확인할 수 있었습니다.
접속은 mysql-operator Pod에서 mysqlsh를 통해 진행했으며 mysqlsh가 자동으로 재접속을 시도해 세션이 유지되었습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
MySQL mycluster.mysql-cluster.svc.cluster.local:3306 ssl SQL > select @@hostname;
ERROR: 2013 (HY000): Lost connection to MySQL server during query
The global session got disconnected..
Attempting to reconnect to 'mysql://root@mycluster.mysql-cluster.svc.cluster.local:3306'..
The global session was successfully reconnected.
MySQL mycluster.mysql-cluster.svc.cluster.local:3306 ssl SQL > select @@hostname;
+-------------+
| @@hostname |
+-------------+
| mycluster-2 |
+-------------+
1 row in set (0.0008 sec)
|
cs |
3. Node Failure
마지막으로 테스트해볼 Failure는 Node의 중지입니다.
Kubernetes는 Node 단위로 Pod를 담기 때문에 Node의 Failure 상황이나 Node의 개수를 줄인다면 그 위의 Pod들은 모두 삭제되지만, 이러한 상황에서도 Kubernetes는 일반적인 Pod Failure 상황과 동일하게 다른 Node에서 Pod를 재생성하는 Failover를 수행하게 됩니다.
즉 Node의 Failure 상황에서도 일반적인 Pod Failure와 동일한 Failover 작업이 이루어진다는 뜻이죠.
하지만 Node Failure에서만 일어날 수 있는 최악의 상황은 InnoDBCluster를 이루는 DB Pod 구성원 모두가 삭제될 때 입니다. 이러한 상황에서는 다른 DB 구성원이 남아있지 않게 되기 때문에 장시간의 Lost Connection을 겪게 될 수 밖에 없죠.
이럴 때를 대비해서 InnoDBCluster 구성요소에는 PodDistruptionBudget 오브젝트가 포함되어 있습니다.
PodDistruptionBudget(이하 PDB)는 한 번에 삭제될 수 있는 Pod의 개수를 제한할 수 있는 오브젝트로 아래와 같이 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
% kubectl describe pdb mycluster-pdb
Name: mycluster-pdb
Namespace: mysql-cluster
Max unavailable: 1
Selector: component=mysqld,mysql.oracle.com/cluster=mycluster,tier=mysql
Status:
Allowed disruptions: 0
Current: 1
Desired: 2
Total: 3
Events: <none>
|
cs |
위와 같이 Max unavailable 값이 1로 설정되어 있기 때문에 DB 인스턴스가 최대 삭제될 수 있는 값은 1개입니다.
따라서 아래와 같이 Node를 강제로 Drain하려해도 PDB에 의해 DB 클러스터가 안정적으로 유지되는 것을 확인할 수 있습니다.

6. 마무리
지금까지 mysql operator를 사용해서 Kubernetes 환경에서의 mysql DB를 운영하는 방법에 대해 알아봤습니다.
비록 아직까지 kubernetes 환경에서 DB를 운영하는 것에 대해 부정적인 시각이 지배적이지만, Operator 패턴과 같은 기술의 등장으로 인해 Kubernetes에서 DB를 구성하는 것도 고려해볼 만한 선택지가 될 수 있다고 생각합니다.
특히 mysql과 같이 Operator가 공식으로 운영되는 DB는 앞으로의 지원이 더 기대되는 면이 있습니다.
비록 아직까지는 mysql-operator가 Cluster와 Backup의 관리에만 Operator의 역할이 미치고 있지만, 앞으로 기술이 더 성숙해지면 더 다양한 방면의 역할도 해낼 수 있을 것이라고 생각합니다.
물론 DB 뿐만 아니라 빅데이터, CI/CD, Obsevability 등 다양한 방면에서도 Operator 패턴을 사용할 수 있기 때문에 이러한 기술에 익숙해지면 Kubernetes를 이용함에 있어서 편리해질 것 같습니다.
'Devops' 카테고리의 다른 글
| Kubernetes에 존재하는 Metrics Server란 무엇일까? 그리고 어떻게 해야 잘 사용할 수 있을까? (1) | 2022.06.26 |
|---|---|
| Apache Kafka란? Apache Kafka를 Kubernetes에서 구성해보자 (1) | 2022.06.16 |
| 오픈소스 컨테이너 레지스트리 Harbor로 컨테이너 레지스트리 간 복제 수행하기 (0) | 2022.05.15 |
| Skaffold + buildpack 으로 쉽게 CI/CD Kubernetes pipeline 구성하기 (0) | 2021.07.30 |
| Gitlab CI/CD + Terraform 연동으로 IaaC 자동화 파이프라인 구축하기 (3) | 2021.05.30 |