

1. 시작
평소에 '대란'이라고 하는 쇼핑 정보를 온갖 사이트에서 찾아보곤 한다.
'대란'이라 함은 낮은 가격으로 물건 이 올라올때 '~~ 대란'이라고 하는 데서 유래했다.
아주 싼 가격에 올라오기 때문에 짧은 시간 안에 구매 해야 품절되기 전에 구입할 수 있다는 특징이 있다.
그래서 '대란'글은 글을 얼마나 빨리 발견하느냐에 따라 구입 승패여부가 갈라진다.
문제는 '대란'글이 올라오는 사이트가 한 두 군데가 아니라는 것이다.
여러 사이트들을 돌다보면 내가 다른 사이트를 보는 사이 괜찮은 '대란'글이 올라오는 경우가 부지기수였다.
여러 사이트들을 일일이 도는 것도 여간 귀찮은 일이 아니였다.
그렇게 몇 번의 구입실패와 귀찮음를 경험하고 나서, 나는 모든 사이트들의'대란'글들을 몰아서 볼 수 있다면 좋을텐데, 라는 생각을 했다.
그것이 Daeran.net이 탄생하는 계기가 되었다.
2. 계획
없으면 내가 만들면 되지, 라는 생각으로 내가 직접 원하는 웹 애플리케이션을 만들기로 했다.
우선 개발 framework를 정해야 한다.
저번 프로젝트에서 Node.js를 이용해서 웹을 하나 만들었던 적이 있어 이번에도 Node.js로 만들어볼까 했지만, Django의 편리한 기능들과 (템플릿 기능, 게시판,회원 기능들이 갖추어져 있다는 점) Python 언어의 편리함을 경험해보고 싶었기에 django를 선택하기로 했다.
그래서 자연스럽게 개발 언어는 python이 주력이 되었다.
database 환경은 Mysql을 이용하기로 했다.
여러가지 선택지가 있었지만, 우선 Nosql은 제외했다.
왜냐하면 게시판,회원 기능들을 구현하는 데에는 테이블로 구성되어 있고, ACID를 충족하는 관계형 데이터 베이스가 더 유리하기 때문이라고 생각했다.
RDBMS 중에서도 무료이고 뛰어난 기능을 가진 workbench를 이용할 수 있는 Mysq을 선택했다.
AWS RDS에서 Mysql을 지원하는 것도 한 몫했다.
배포 환경은 AWS를 이용하기로 했다.
AWS 클라우드 환경을 선택한 것은 내 컴퓨터에서 24시간 서버를 돌릴 수없거니와 AWS 자격증을 취득한 만큼 AWS 클라우드 환경에서 돌리는 것이 나에겐 더 익숙하기 때문이다.
사이트 곳곳의 '대란' 글들은 크롤러를 제작해 긁어오기로 했다.
크롤러가 수집한 정보를 테이블에 맞게 재가공해 DB에 저장하면 될 것 같다.
이렇게 대강 만들고자 하는 틀이 잡혔다.
개발 Framework : django 2.1
프로그래밍 언어 : Python 3.6
Database 환경 : MySQL 5.7 (AWS RDS instance)
배포 환경 : AWS Elastic Beanstalk
개발 환경 : Ubuntu 18.04 (AWS EC2 instance)
내가 애플리케이션에서 구현하고자 하는 기능들은 우선 크롤링한 글을 담을 게시판 기능, 회원 기능(그냥 넣어보고 싶었다), 게시판에 쓰일 댓글 기능이다.
추가로 사이트의 '대란'글을 어떻게 긁어올지 크롤러의 세부사항을 결정해야 한다.
3. 구현
django는 Node.js와 유사한 점이 많지만, 다른 것은 Templete, View, Model의 3가지 요소로 작동한다는 것이다.
Templete은 렌더링되는 요소로 View에서 지정한 대로 문맥(Context)를 받아 웹의 보이는 부분을 그리게 된다.
View는 기능을 정하는 요소로 Templete에 문맥을 전달해주고 기능들이 어떻게 구현되는지 정한다.
마지막으로 Model은 DB에 저장될 스키마를 지정하는 요소이다.
우선 Templete에서 가장 기본이 되는 base 파일부터 만들어보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
!DOCTYPE html>
<HTML LANG="KO">
<HEAD>
<title>{% block title%} Daeran.net{% endblock %}</title>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
<script src="https://kit.fontawesome.com/5b3a7428a6.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js" integrity="sha384-wfSDF2E50Y2D1uUdj0O3uMBJnjuUD4Ih7YwaYd1iqfktj0Uod8GCExl3Og8ifwB6" crossorigin="anonymous"></script>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</HEAD>
<body>
{% block content %}{% endblock %}
{% block script %}{% endblock %} {% comment %} script는 </body>위가 가장 빠르다 {% endcomment %}
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.bundle.min.js">
{% load static %}
<LINK REL='STYLESHEET' HREF="{% static 'boardapp/assets/css/main.css' %}" />
</body>
</HTML>
|
cs |
앞으로 쓰일 jquery,bootstrap같은 외부 라이브러리를 가져오고 한글을 지원하기 위해 charset도 UTF-8로 지정한다.
CSS 파일도 가져온다. {% ~~ %}형식으로 되어 있는 부분은 django templete language를 사용하는 것으로,django에서제공하는 강력한 기능이다.
django templete language를 사용해서 문맥(context)를 html로 편리하게 적용할 수 있다.
추가적으로 사이트의 대문이 될 Main.html 파일을 임시로 만든다.
다음은 url.py 파일로 들어가서 대문의 경로를 지정해준다. Node.js에서의 Routing 과 같은 기능을 한다.
|
1
2
3
4
5
|
from django.urls import path
urlpatterns = [
path('', main_page, name='main'),
]
|
cs |
url 패턴 안에 path를 지정해주는 방식으로 편리하게 구현할 수 있다.
위의 경우에는 사이트의 첫 진입 시 (어느 디렉토리에도 진입하지 않을 시) main_page 함수를 실행하고 이 path의 이름은 'main'으로 정해놓은 모습이다. View로 넘어가서 main_page 함수를 구현하자.
|
1
2
|
def main_page(request):
return render(request,'main.html')
|
cs |
위는 view.py 내의 main_page 함수이다 .render 메소드에 request인자와 렌더링할 html파일 인자를 넣는다.
이렇게 Templete 과 View를 구현하고 url로 라우팅해주는 방식으로 대부분의 개발이 이루어진다.
다음은 Model을 구현해 db와의 연계를 해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Boards(models.Model) :
category = models.ForeignKey(BoardCategories, models.DO_NOTHING)
user = models.ForeignKey(User, models.DO_NOTHING)
title = models.CharField(max_length=300)
content = models.TextField()
registered_date = models.DateTimeField(default=timezone.now)
last_update_date = models.DateTimeField(default=timezone.now)
view_count = models.IntegerField(blank=True,default=0)
image = models.ImageField(upload_to="images/%Y/%m/%d", blank=True)
def __str__(self):
return '[%d] %.40s' % (self.id, self.title)
class Meta :
managed = False
db_table = 'boards'
|
cs |
Model.py에서 위와 같이 Boards Model을 구현한다. 카테고리와 글쓴이, 제목, 내용, 작성일, 마지막 수정일, 조회수,
이미지 속성이 존재한다. 카테고리는 BoardCategories 테이블과 연계하는 외래키로 설정했다.
models.DO_NOTHING은 개체가 삭제될 때 외래키로 연계된 값을 어떻게 할지 정하는 인자이다.
아무것도 안하기(DO_NOTHING), 삭제, 캐스캐이딩을 설정할 수 있다.
Mysql에도 동일한 스키마를 만들면 된다. (사실 순서 상 db상에서 스키마 구현이 먼저다.)
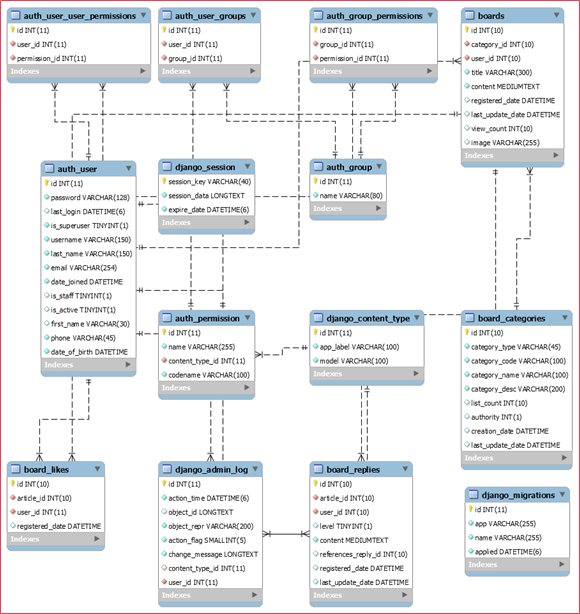
최종적으로 만들어진 DB의 ERD 구조이다. 게시판 모델인 Boards 와 카테고리 모델인 Boards_categories, 댓글 모델인 board_replies, 그리고 쓰일지 안쓰일지 모를 board_likes 모델을 만들어 '좋아요' 기능에 대응하도록 했다.
회원 관리 관련 Model은 대부분 django의 contirb에서 제공하는 User 모델을 차용했다.
이렇게 하면 set_password 메소드를 사용해 password 기능도 간편하게 구현할 수 있고,완성도 있는 모델을 쉽게 사용할 수 있다는 장점이 있다.
Abstactbaseuser를 상속받아 내가 원하는 대로 이름과 이메일, 전화번호 등의 요소도 추가한다.
이제 위의 방식과 같이 개발을 진행해보자.
4. 계속 구현
게시판 기능을 먼저 구현했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
<table class="table table-striped">
<thead>
<tr>
<th scope="col-3">카테고리</th>
<th scope="col-1">No.</th>
<th scope="col-4">제목</th>
<th scope="col-1">글쓴이</th>
<th scope="col-2">등록일</th>
<th scope="col-1">조회 수</th>
</tr>
</thead>
<tbody>
<tr>
{% for article in articles %}
{% if article.category.category_name == 'Ppompu' %}
<td scope="col-3"><span class="badge badge-success">{{ article.category.category_name }}</span></td>
{% elif article.category.category_name == 'Ruriweb' %}
<td scope="col-3"><span class="badge badge-info">{{ article.category.category_name }}</span></td>
{% elif article.category.category_name == "Clien" %}
<td scope="col-3"><span class="badge badge-warning">{{ article.category.category_name }}</span></td>
{% else %}
<td scope="col-3"><span class="badge badge-primary">{{ article.category.category_name }}</span></td>
{% endif %}
<td scope="col-1">{{article.id}}</td>
<th scope="col-4"><a href="{% url 'boardview' article.id %}">
{{ article.title }}
{% if article.reply_count > 0 %}
[{{ article.reply_count }}]
{% endif %}</th>
<td scope="col-1">{{ article.user.last_name }}</td>
<td scope="col-2">{{ article.registered_date |date:"Y-m-d H:i:s" }}</td>
<td scope="col-1">{{ article.view_count }}</td>
</tr>
{% endfor %}
</tbody>
</table>
|
cs |
위에서 설명했던 django templete language( {%~~%} ) 의 장점을 볼 수 있다.
{% for article in articles %} 처럼 for문도 사용할 수 있다.
db의 게시물 수만큼 {% endfor %}까지의 내용을 반복한다.
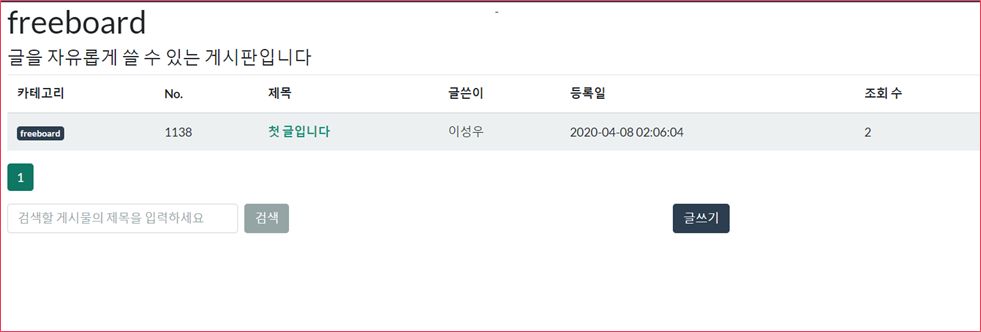
이렇게 view와 template에서 board 기능을 구현한 모습이다.
Pagination 기능을 통해 페이지 수를 나타내도록 했고, 게시물 검색 기능도 추가했다.
글쓰기 기능을 구현하던 중, textarea 안의 내용이 개행이 적용되지 않은 채로 게시물이 작성되는 경우가 있었다.
알아보니 개행이 적용되려면 '/n'을 넣어야 된다고 한다. 하지만 글을 쓰면서 일일이 /n을 타이핑할 수 없으니 방법을 찾아보기로 했다.
그러던 중 django의 templete language에 이 기능을 쉽게 구현해주는 방법이 있는 것을 발견했다.
{{ ~~ |linebreaks }} 를 통해서 django가 알아서 개행이 적용될 부분에 개행을 넣어주는 것이다.
|
1
2
3
4
5
6
7
|
<div class="row">
<div class="col-12 view-content">
<p class="content-box">{{ object.content|linebreaks }}</p> {% comment %} 개행을 적용하기 위해서 linebreaks를 쓴다 {% endcomment %}
{% if object.image %}<img src="{{ object.image.url }}" />
{% endif %}
</div>
</div>
|
cs |
위는 게시판 뷰 템플릿에서 linebreak 기능이 구현된 상태이다.
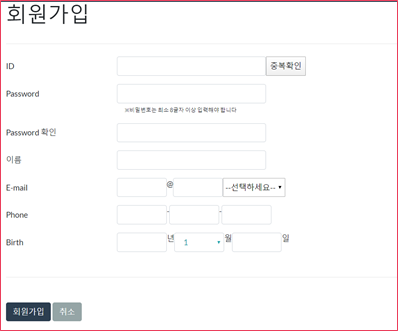
위는 회원가입을 구현한 상태이다.
ID,PASSWORD 등을 폼에 입력하게 하고, 중복확인은 Ajax로 동일 ID 여부를 확인하고 중복여부를 새로고침없이 띄우게 했다.
E-mail의 도메인 선택 창도 Ajax로 구현해 원하는 도메인을 새로고침 없이 선택 가능하게 했다.
폼을 작성하고 회원가입 버튼을 누르면 view에서 정보를 검증한 뒤(폼 작성 여부, 올바른 데이터 여부 등) 회원가입 축하 페이지로 리다이렉션 하게 했다.
5. 크롤러 만들기
웹 애플리케이션의 기본적인 기능은 구현했으니, 이제 대란 글을 긁어올 크롤러를 만들어 보자.
크롤러는 beautifulsoup4를 사용해 html을 파싱하고 selenium을 이용해 원하는 정보에 접근하도록 했다.
내가 쇼핑정보를 얻기 위해 자주 가는 뽐뿌, 루리웹, 클리앙의 글을 긁어오도록 하자.
크롤링하는 과정은 다음과 같다. 우선 selenium을 통해 원하는 사이트에 접근한다. 그 뒤 bs4를 사용해 html을 파싱한 뒤 선택자를 사용해 원하는 정보를 뽑아온다.
마지막으로 뽑아온 데이터를 DB에 Insert하고 commit한다.

위의 사진과 같이 개발자도구를 사용해 원하는 정보를 찾은 뒤 Copy selector를 누르면 그 정보로 향하는 경로를 쉽게 얻을 수 있다.
이 경로를 사용해 원하는 정보만 크롤링 해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
try:
titleSelector = soup.select(
'tr > td:nth-child(2) > a > font')
titles=[]
siteUrls=[]
a=0
b=0
href = soup.select(
'tr > td:nth-child(2) > a'
)
for titleSelector in titleSelector:
title = titleSelector.get_text()
titles.insert(b,title)
b=b+1
for href in href:
siteUrl= 'http://www.ppomppu.co.kr/zboard/' + href.get('href')
siteUrls.insert(a,siteUrl) #siteUrls에 접근할 수 있도록 번호 부착
a=a+1
|
cs |
위에서 'tr > td:nth-child(2) > a > font' 부분이 내가 원하는 게시물의 제목 경로이다. 한 페이지의 게시물을 전부 가져오려면 특정 게시물을 지정하는 숫자를 지워주면 된다.
이러한 방식으로 게시물 제목과 링크를 가져온다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
try:
for titles in reversed(titles): #titles를 그대로 읽게 되면 최신의 역순으로 저장되므로, reversed를 통해 반대로 읽는다.
titles= pymysql.escape_string(titles) #mysql은 작은따옴표(')를 insert하지 못하기 때문에 excape_string으로 escape해준다
print(a)
sql = "SELECT * FROM `boards` WHERE `title` = ('%s') " % titles
if (curs.execute(sql)==0):
sql = """insert into boards(category_id,user_id,title,content)
values (%s, %s, %s, %s)"""
curs.execute(sql, (10,8,titles,siteUrls[a]))
print(titles+'수집 완료')
a=a-1
print(a) # href는 titles와 반대 순으로 저장되어 있으므로, a 변수를 통해 반대로 읽어준다.
except Exception as e:
print(e)
print("오류로 인해 실행 중단")
conn.commit()
print("Clien 크롤링 완료")
|
cs |
긁어온 정보들은 위와 같이 db에 commit한다. python에서 sql은 "SELECT * FROM `boards` WHERE `title` = ('%s') "
와 같은 방식으로 작성한다.
크롤러를 작성하고 구현하는 데까지는 성공했는데, 로컬 환경에서 크롤러를 24시간 돌릴 수는 없는 노릇이다.
그래서 클라우드 환경에서 크롤러를 돌리는 방안을 탐색했다.
마침 AWS에서 Lambda라는 코드리스 컴퓨팅 기능을 제공해주는 것을 발견했다.
전체 애플리케이션이 AWS 위에서 돌아가니, 크롤러도 AWS 클라우드 위에서 돌리는 것이 맞다.
문제는, Lambda에 코드와 필요한 모듈을 업로드해야 하는데, Selenium 파일 자체를 업로드해서 lambda에서 구동하는 것이 여간 까다로운 것이 아니였다.
그래서 크롤러 코드를 selenium 없이 구동하는 방향으로 수정했다.
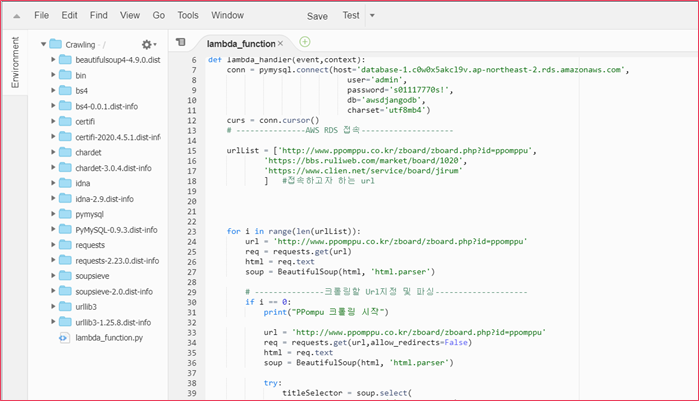
위는 Lambda에 최종 크롤러 코드를 업로드한 모습이다. 처음 접하는 서비스를 이용하려니 몇 번의 시행착오를
거치고서야 온전히 작동시킬 수 있었다. 그 외에 bs4와 pymysql 도 업로드해서 사용할 수 있게 했다.
또 다른 문제는 크롤러를 매 순간마다 돌릴 수는 없는 지라 크롤링이 구동될 시간을 정해야 하는데, n시간 마다 크롤러를 작동시킨다는 트리거를 어떻게 구현해야 할지 막막했다.
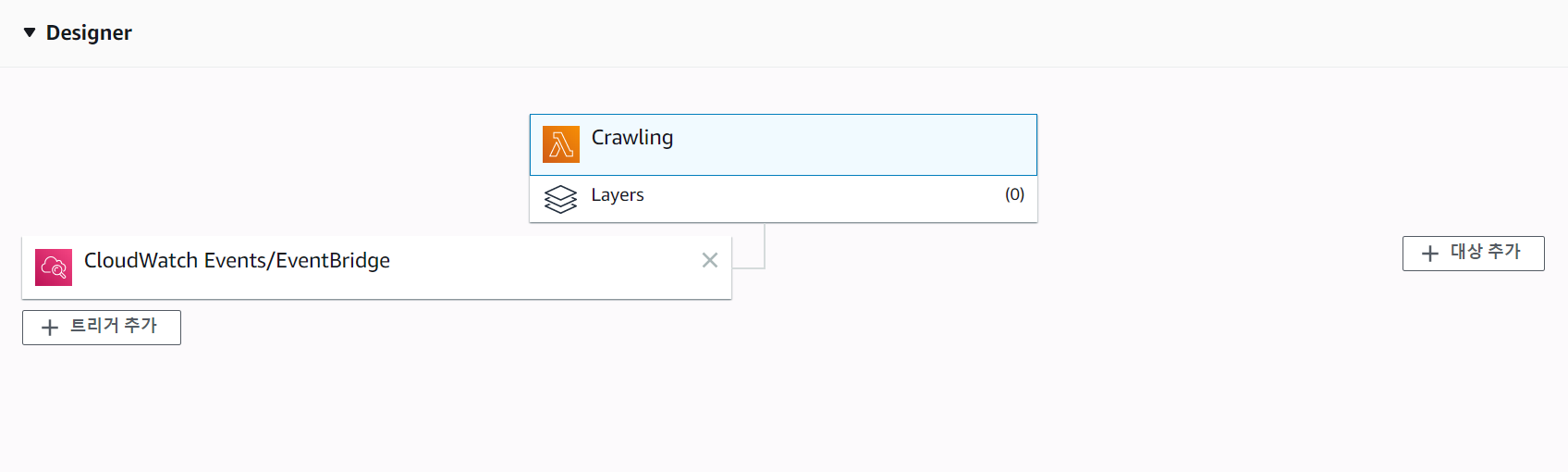
이 문제 또한 AWS가 풀어주었는데, AWS Cloudwatch Event의 EventBridge를 Lambda의 트리거로 설정해 n시간마다 함수를 실행할 수 있게 할 수 있었다.
(이 과정에서 Cron문법을 알게 되었는데, 정말 생소한 문법이라 신기했던 기억이 난다)
추가적으로 계속 데이터가 쌓이는 것을 방지하기 위해 3일이 지난 데이터는 삭제하는 Lambda 함수를 추가해 최종적으로 크롤러 구현을 마치게 되었다.
2부에서 계속...
'AWS' 카테고리의 다른 글
| S3 + Cloudfront를 이용해 www redirect를 구현한 Static Website 호스팅하기 (0) | 2023.08.22 |
|---|---|
| AWS EKS의 IP 주소 관리: 쿠버네티스 클러스터의 네트워킹 고려사항 (0) | 2023.08.01 |
| django + mysql + AWS 로 쇼핑 정보 가져오는 게시판 만들기 (Daeran.net) (2) (4) | 2020.04.21 |
| AWS Certified Solutions Architect-Associate(AWS SAA) 자격증 취득기 -2 (0) | 2020.02.05 |
| AWS Certified Solutions Architect-Associate(AWS SAA) 자격증 취득기 -1 (0) | 2020.02.04 |
1. 시작
평소에 '대란'이라고 하는 쇼핑 정보를 온갖 사이트에서 찾아보곤 한다.
'대란'이라 함은 낮은 가격으로 물건 이 올라올때 '~~ 대란'이라고 하는 데서 유래했다.
아주 싼 가격에 올라오기 때문에 짧은 시간 안에 구매 해야 품절되기 전에 구입할 수 있다는 특징이 있다.
그래서 '대란'글은 글을 얼마나 빨리 발견하느냐에 따라 구입 승패여부가 갈라진다.
문제는 '대란'글이 올라오는 사이트가 한 두 군데가 아니라는 것이다.
여러 사이트들을 돌다보면 내가 다른 사이트를 보는 사이 괜찮은 '대란'글이 올라오는 경우가 부지기수였다.
여러 사이트들을 일일이 도는 것도 여간 귀찮은 일이 아니였다.
그렇게 몇 번의 구입실패와 귀찮음를 경험하고 나서, 나는 모든 사이트들의'대란'글들을 몰아서 볼 수 있다면 좋을텐데, 라는 생각을 했다.
그것이 Daeran.net이 탄생하는 계기가 되었다.
2. 계획
없으면 내가 만들면 되지, 라는 생각으로 내가 직접 원하는 웹 애플리케이션을 만들기로 했다.
우선 개발 framework를 정해야 한다.
저번 프로젝트에서 Node.js를 이용해서 웹을 하나 만들었던 적이 있어 이번에도 Node.js로 만들어볼까 했지만, Django의 편리한 기능들과 (템플릿 기능, 게시판,회원 기능들이 갖추어져 있다는 점) Python 언어의 편리함을 경험해보고 싶었기에 django를 선택하기로 했다.
그래서 자연스럽게 개발 언어는 python이 주력이 되었다.
database 환경은 Mysql을 이용하기로 했다.
여러가지 선택지가 있었지만, 우선 Nosql은 제외했다.
왜냐하면 게시판,회원 기능들을 구현하는 데에는 테이블로 구성되어 있고, ACID를 충족하는 관계형 데이터 베이스가 더 유리하기 때문이라고 생각했다.
RDBMS 중에서도 무료이고 뛰어난 기능을 가진 workbench를 이용할 수 있는 Mysq을 선택했다.
AWS RDS에서 Mysql을 지원하는 것도 한 몫했다.
배포 환경은 AWS를 이용하기로 했다.
AWS 클라우드 환경을 선택한 것은 내 컴퓨터에서 24시간 서버를 돌릴 수없거니와 AWS 자격증을 취득한 만큼 AWS 클라우드 환경에서 돌리는 것이 나에겐 더 익숙하기 때문이다.
사이트 곳곳의 '대란' 글들은 크롤러를 제작해 긁어오기로 했다.
크롤러가 수집한 정보를 테이블에 맞게 재가공해 DB에 저장하면 될 것 같다.
이렇게 대강 만들고자 하는 틀이 잡혔다.
개발 Framework : django 2.1
프로그래밍 언어 : Python 3.6
Database 환경 : MySQL 5.7 (AWS RDS instance)
배포 환경 : AWS Elastic Beanstalk
개발 환경 : Ubuntu 18.04 (AWS EC2 instance)
내가 애플리케이션에서 구현하고자 하는 기능들은 우선 크롤링한 글을 담을 게시판 기능, 회원 기능(그냥 넣어보고 싶었다), 게시판에 쓰일 댓글 기능이다.
추가로 사이트의 '대란'글을 어떻게 긁어올지 크롤러의 세부사항을 결정해야 한다.
3. 구현
django는 Node.js와 유사한 점이 많지만, 다른 것은 Templete, View, Model의 3가지 요소로 작동한다는 것이다.
Templete은 렌더링되는 요소로 View에서 지정한 대로 문맥(Context)를 받아 웹의 보이는 부분을 그리게 된다.
View는 기능을 정하는 요소로 Templete에 문맥을 전달해주고 기능들이 어떻게 구현되는지 정한다.
마지막으로 Model은 DB에 저장될 스키마를 지정하는 요소이다.
우선 Templete에서 가장 기본이 되는 base 파일부터 만들어보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
!DOCTYPE html>
<HTML LANG="KO">
<HEAD>
<title>{% block title%} Daeran.net{% endblock %}</title>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
<script src="https://kit.fontawesome.com/5b3a7428a6.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js" integrity="sha384-wfSDF2E50Y2D1uUdj0O3uMBJnjuUD4Ih7YwaYd1iqfktj0Uod8GCExl3Og8ifwB6" crossorigin="anonymous"></script>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</HEAD>
<body>
{% block content %}{% endblock %}
{% block script %}{% endblock %} {% comment %} script는 </body>위가 가장 빠르다 {% endcomment %}
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.bundle.min.js">
{% load static %}
<LINK REL='STYLESHEET' HREF="{% static 'boardapp/assets/css/main.css' %}" />
</body>
</HTML>
|
cs |
앞으로 쓰일 jquery,bootstrap같은 외부 라이브러리를 가져오고 한글을 지원하기 위해 charset도 UTF-8로 지정한다.
CSS 파일도 가져온다. {% ~~ %}형식으로 되어 있는 부분은 django templete language를 사용하는 것으로,django에서제공하는 강력한 기능이다.
django templete language를 사용해서 문맥(context)를 html로 편리하게 적용할 수 있다.
추가적으로 사이트의 대문이 될 Main.html 파일을 임시로 만든다.
다음은 url.py 파일로 들어가서 대문의 경로를 지정해준다. Node.js에서의 Routing 과 같은 기능을 한다.
|
1
2
3
4
5
|
from django.urls import path
urlpatterns = [
path('', main_page, name='main'),
]
|
cs |
url 패턴 안에 path를 지정해주는 방식으로 편리하게 구현할 수 있다.
위의 경우에는 사이트의 첫 진입 시 (어느 디렉토리에도 진입하지 않을 시) main_page 함수를 실행하고 이 path의 이름은 'main'으로 정해놓은 모습이다. View로 넘어가서 main_page 함수를 구현하자.
|
1
2
|
def main_page(request):
return render(request,'main.html')
|
cs |
위는 view.py 내의 main_page 함수이다 .render 메소드에 request인자와 렌더링할 html파일 인자를 넣는다.
이렇게 Templete 과 View를 구현하고 url로 라우팅해주는 방식으로 대부분의 개발이 이루어진다.
다음은 Model을 구현해 db와의 연계를 해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Boards(models.Model) :
category = models.ForeignKey(BoardCategories, models.DO_NOTHING)
user = models.ForeignKey(User, models.DO_NOTHING)
title = models.CharField(max_length=300)
content = models.TextField()
registered_date = models.DateTimeField(default=timezone.now)
last_update_date = models.DateTimeField(default=timezone.now)
view_count = models.IntegerField(blank=True,default=0)
image = models.ImageField(upload_to="images/%Y/%m/%d", blank=True)
def __str__(self):
return '[%d] %.40s' % (self.id, self.title)
class Meta :
managed = False
db_table = 'boards'
|
cs |
Model.py에서 위와 같이 Boards Model을 구현한다. 카테고리와 글쓴이, 제목, 내용, 작성일, 마지막 수정일, 조회수,
이미지 속성이 존재한다. 카테고리는 BoardCategories 테이블과 연계하는 외래키로 설정했다.
models.DO_NOTHING은 개체가 삭제될 때 외래키로 연계된 값을 어떻게 할지 정하는 인자이다.
아무것도 안하기(DO_NOTHING), 삭제, 캐스캐이딩을 설정할 수 있다.
Mysql에도 동일한 스키마를 만들면 된다. (사실 순서 상 db상에서 스키마 구현이 먼저다.)
최종적으로 만들어진 DB의 ERD 구조이다. 게시판 모델인 Boards 와 카테고리 모델인 Boards_categories, 댓글 모델인 board_replies, 그리고 쓰일지 안쓰일지 모를 board_likes 모델을 만들어 '좋아요' 기능에 대응하도록 했다.
회원 관리 관련 Model은 대부분 django의 contirb에서 제공하는 User 모델을 차용했다.
이렇게 하면 set_password 메소드를 사용해 password 기능도 간편하게 구현할 수 있고,완성도 있는 모델을 쉽게 사용할 수 있다는 장점이 있다.
Abstactbaseuser를 상속받아 내가 원하는 대로 이름과 이메일, 전화번호 등의 요소도 추가한다.
이제 위의 방식과 같이 개발을 진행해보자.
4. 계속 구현
게시판 기능을 먼저 구현했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
<table class="table table-striped">
<thead>
<tr>
<th scope="col-3">카테고리</th>
<th scope="col-1">No.</th>
<th scope="col-4">제목</th>
<th scope="col-1">글쓴이</th>
<th scope="col-2">등록일</th>
<th scope="col-1">조회 수</th>
</tr>
</thead>
<tbody>
<tr>
{% for article in articles %}
{% if article.category.category_name == 'Ppompu' %}
<td scope="col-3"><span class="badge badge-success">{{ article.category.category_name }}</span></td>
{% elif article.category.category_name == 'Ruriweb' %}
<td scope="col-3"><span class="badge badge-info">{{ article.category.category_name }}</span></td>
{% elif article.category.category_name == "Clien" %}
<td scope="col-3"><span class="badge badge-warning">{{ article.category.category_name }}</span></td>
{% else %}
<td scope="col-3"><span class="badge badge-primary">{{ article.category.category_name }}</span></td>
{% endif %}
<td scope="col-1">{{article.id}}</td>
<th scope="col-4"><a href="{% url 'boardview' article.id %}">
{{ article.title }}
{% if article.reply_count > 0 %}
[{{ article.reply_count }}]
{% endif %}</th>
<td scope="col-1">{{ article.user.last_name }}</td>
<td scope="col-2">{{ article.registered_date |date:"Y-m-d H:i:s" }}</td>
<td scope="col-1">{{ article.view_count }}</td>
</tr>
{% endfor %}
</tbody>
</table>
|
cs |
위에서 설명했던 django templete language( {%~~%} ) 의 장점을 볼 수 있다.
{% for article in articles %} 처럼 for문도 사용할 수 있다.
db의 게시물 수만큼 {% endfor %}까지의 내용을 반복한다.
이렇게 view와 template에서 board 기능을 구현한 모습이다.
Pagination 기능을 통해 페이지 수를 나타내도록 했고, 게시물 검색 기능도 추가했다.
글쓰기 기능을 구현하던 중, textarea 안의 내용이 개행이 적용되지 않은 채로 게시물이 작성되는 경우가 있었다.
알아보니 개행이 적용되려면 '/n'을 넣어야 된다고 한다. 하지만 글을 쓰면서 일일이 /n을 타이핑할 수 없으니 방법을 찾아보기로 했다.
그러던 중 django의 templete language에 이 기능을 쉽게 구현해주는 방법이 있는 것을 발견했다.
{{ ~~ |linebreaks }} 를 통해서 django가 알아서 개행이 적용될 부분에 개행을 넣어주는 것이다.
|
1
2
3
4
5
6
7
|
<div class="row">
<div class="col-12 view-content">
<p class="content-box">{{ object.content|linebreaks }}</p> {% comment %} 개행을 적용하기 위해서 linebreaks를 쓴다 {% endcomment %}
{% if object.image %}<img src="{{ object.image.url }}" />
{% endif %}
</div>
</div>
|
cs |
위는 게시판 뷰 템플릿에서 linebreak 기능이 구현된 상태이다.
위는 회원가입을 구현한 상태이다.
ID,PASSWORD 등을 폼에 입력하게 하고, 중복확인은 Ajax로 동일 ID 여부를 확인하고 중복여부를 새로고침없이 띄우게 했다.
E-mail의 도메인 선택 창도 Ajax로 구현해 원하는 도메인을 새로고침 없이 선택 가능하게 했다.
폼을 작성하고 회원가입 버튼을 누르면 view에서 정보를 검증한 뒤(폼 작성 여부, 올바른 데이터 여부 등) 회원가입 축하 페이지로 리다이렉션 하게 했다.
5. 크롤러 만들기
웹 애플리케이션의 기본적인 기능은 구현했으니, 이제 대란 글을 긁어올 크롤러를 만들어 보자.
크롤러는 beautifulsoup4를 사용해 html을 파싱하고 selenium을 이용해 원하는 정보에 접근하도록 했다.
내가 쇼핑정보를 얻기 위해 자주 가는 뽐뿌, 루리웹, 클리앙의 글을 긁어오도록 하자.
크롤링하는 과정은 다음과 같다. 우선 selenium을 통해 원하는 사이트에 접근한다. 그 뒤 bs4를 사용해 html을 파싱한 뒤 선택자를 사용해 원하는 정보를 뽑아온다.
마지막으로 뽑아온 데이터를 DB에 Insert하고 commit한다.
위의 사진과 같이 개발자도구를 사용해 원하는 정보를 찾은 뒤 Copy selector를 누르면 그 정보로 향하는 경로를 쉽게 얻을 수 있다.
이 경로를 사용해 원하는 정보만 크롤링 해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
try:
titleSelector = soup.select(
'tr > td:nth-child(2) > a > font')
titles=[]
siteUrls=[]
a=0
b=0
href = soup.select(
'tr > td:nth-child(2) > a'
)
for titleSelector in titleSelector:
title = titleSelector.get_text()
titles.insert(b,title)
b=b+1
for href in href:
siteUrl= 'http://www.ppomppu.co.kr/zboard/' + href.get('href')
siteUrls.insert(a,siteUrl) #siteUrls에 접근할 수 있도록 번호 부착
a=a+1
|
cs |
위에서 'tr > td:nth-child(2) > a > font' 부분이 내가 원하는 게시물의 제목 경로이다. 한 페이지의 게시물을 전부 가져오려면 특정 게시물을 지정하는 숫자를 지워주면 된다.
이러한 방식으로 게시물 제목과 링크를 가져온다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
try:
for titles in reversed(titles): #titles를 그대로 읽게 되면 최신의 역순으로 저장되므로, reversed를 통해 반대로 읽는다.
titles= pymysql.escape_string(titles) #mysql은 작은따옴표(')를 insert하지 못하기 때문에 excape_string으로 escape해준다
print(a)
sql = "SELECT * FROM `boards` WHERE `title` = ('%s') " % titles
if (curs.execute(sql)==0):
sql = """insert into boards(category_id,user_id,title,content)
values (%s, %s, %s, %s)"""
curs.execute(sql, (10,8,titles,siteUrls[a]))
print(titles+'수집 완료')
a=a-1
print(a) # href는 titles와 반대 순으로 저장되어 있으므로, a 변수를 통해 반대로 읽어준다.
except Exception as e:
print(e)
print("오류로 인해 실행 중단")
conn.commit()
print("Clien 크롤링 완료")
|
cs |
긁어온 정보들은 위와 같이 db에 commit한다. python에서 sql은 "SELECT * FROM `boards` WHERE `title` = ('%s') "
와 같은 방식으로 작성한다.
크롤러를 작성하고 구현하는 데까지는 성공했는데, 로컬 환경에서 크롤러를 24시간 돌릴 수는 없는 노릇이다.
그래서 클라우드 환경에서 크롤러를 돌리는 방안을 탐색했다.
마침 AWS에서 Lambda라는 코드리스 컴퓨팅 기능을 제공해주는 것을 발견했다.
전체 애플리케이션이 AWS 위에서 돌아가니, 크롤러도 AWS 클라우드 위에서 돌리는 것이 맞다.
문제는, Lambda에 코드와 필요한 모듈을 업로드해야 하는데, Selenium 파일 자체를 업로드해서 lambda에서 구동하는 것이 여간 까다로운 것이 아니였다.
그래서 크롤러 코드를 selenium 없이 구동하는 방향으로 수정했다.
위는 Lambda에 최종 크롤러 코드를 업로드한 모습이다. 처음 접하는 서비스를 이용하려니 몇 번의 시행착오를
거치고서야 온전히 작동시킬 수 있었다. 그 외에 bs4와 pymysql 도 업로드해서 사용할 수 있게 했다.
또 다른 문제는 크롤러를 매 순간마다 돌릴 수는 없는 지라 크롤링이 구동될 시간을 정해야 하는데, n시간 마다 크롤러를 작동시킨다는 트리거를 어떻게 구현해야 할지 막막했다.
이 문제 또한 AWS가 풀어주었는데, AWS Cloudwatch Event의 EventBridge를 Lambda의 트리거로 설정해 n시간마다 함수를 실행할 수 있게 할 수 있었다.
(이 과정에서 Cron문법을 알게 되었는데, 정말 생소한 문법이라 신기했던 기억이 난다)
추가적으로 계속 데이터가 쌓이는 것을 방지하기 위해 3일이 지난 데이터는 삭제하는 Lambda 함수를 추가해 최종적으로 크롤러 구현을 마치게 되었다.
2부에서 계속...
'AWS' 카테고리의 다른 글
| S3 + Cloudfront를 이용해 www redirect를 구현한 Static Website 호스팅하기 (0) | 2023.08.22 |
|---|---|
| AWS EKS의 IP 주소 관리: 쿠버네티스 클러스터의 네트워킹 고려사항 (0) | 2023.08.01 |
| django + mysql + AWS 로 쇼핑 정보 가져오는 게시판 만들기 (Daeran.net) (2) (4) | 2020.04.21 |
| AWS Certified Solutions Architect-Associate(AWS SAA) 자격증 취득기 -2 (0) | 2020.02.05 |
| AWS Certified Solutions Architect-Associate(AWS SAA) 자격증 취득기 -1 (0) | 2020.02.04 |