

멀티 클라우드 환경이 점점 대세가 되어가면서 자연스럽게 다양한 클라우드 플랫폼의 로그 및 메트릭을 중앙화하려는 시도들이 많아지고 있습니다.
각 클라우드 벤더마다 사용하는 로깅, 혹은 모니터링 환경(AWS의 Cloudwatch, GCP의 Operations)이 다르기 때문에 각기 다른 환경을 통일해야만 통합된 관측 가능성을 확보할 수 있기 때문입니다.
이런 각기 다른 관측 가능성 환경을 통합하는 도구로 주로 사용되는 것이 Elastic 사의 Elasticsearch입니다.
Elasticsearch는 주로 데이터 처리 파이프라인인 Logstash와 데이터 시각화를 이용한 대쉬보드 도구인 Kibana와 같이 사용되어 이 세 가지 도구를 ELK Stack이라고도 부릅니다.
ELK Stack은 OSS이고 컨테이너, VM 등 다양한 환경을 지원하기 때문에 유연할 뿐더러, 장기간 다수의 레퍼런스를 쌓아온 도구인만큼 안정성도 보장되어 있다는 장점이 있습니다.
이번 포스팅에서는 이 ELK Stack을 사용해 GCP 부문의 관측 가능성 지표들을 수집하고 대쉬보드로 확인할 수 있는 환경을 GKE Cluster환경에서 구축해보겠습니다.
1. GKE Cluster환경 구축
1-1. GKE Cluster 생성
우선 ELK Stack을 설치할 GKE cluster를 생성하겠습니다.
GKE cluster는 기존 GKE 생성 페이지에서 "GKE Standard"를 선택하는 것으로 생성할 수 있습니다.
GKE Standard의 CONFIGURE 버튼을 누르면 GKE Standard 모드의 클러스터를 생성할 수 있습니다.
아래의 GKE Autopilot는 쉽고 간편하게 사용하는 GKE Cluster이기 때문에 생성 과정도 복잡함 없이 진행할 수 있다는 특징이 있습니다.
이같은 간편함은 반대로 말하면 사용자 편의에 맞게 커스터마이징하거나 구성을 변경할 수 있는 여지가 적다는 뜻이기도 하기 때문에 Standard 모드와 Autopilot 모드 간의 장단을 잘 파악해 사용해야 합니다.
Cluster basics 페이지에서 클러스터의 이름과 리젼을 지정합니다.
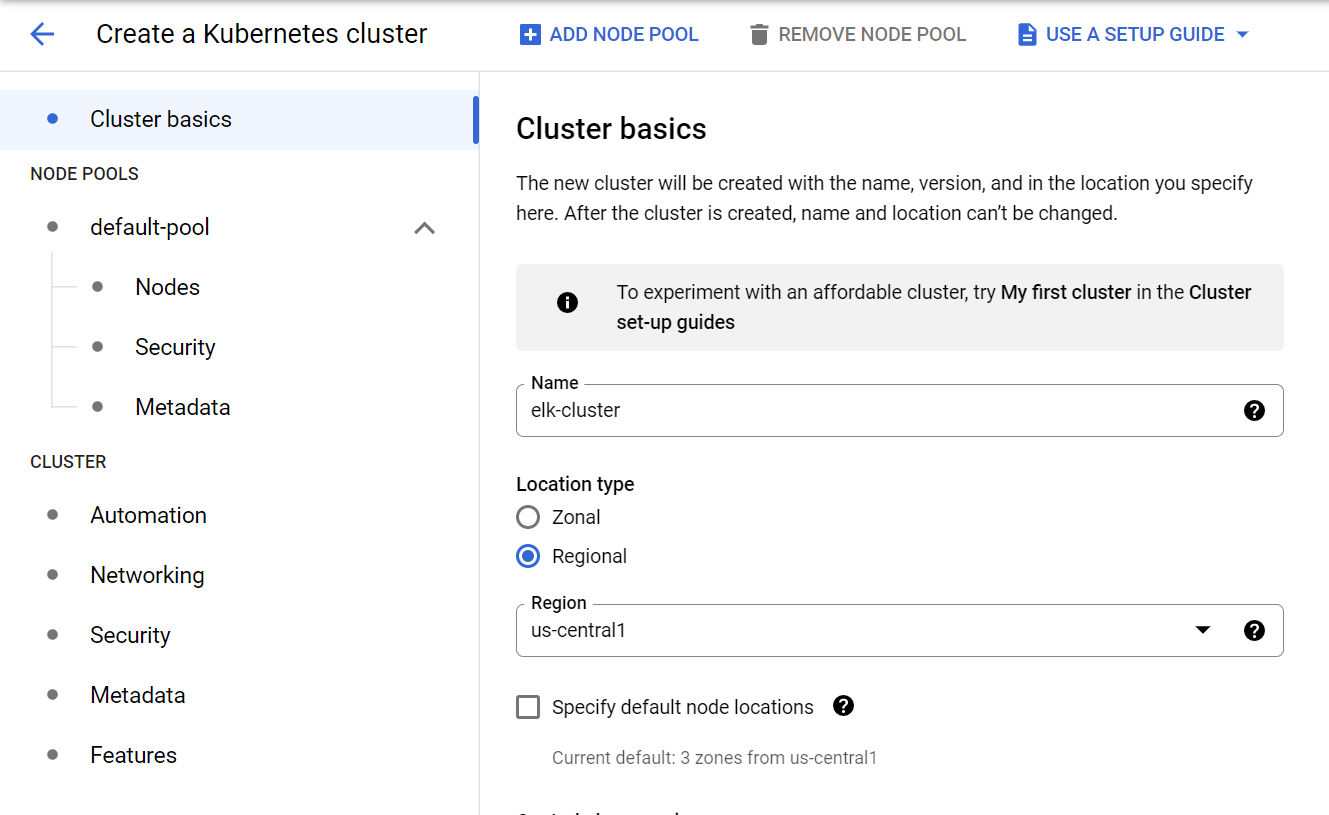
Node pools 페이지에선 노드의 인스턴스 타입을 n2-standard-4로 변경합니다. 기본값인 e2-medium 머신은 ELK 스택의 리소스 요구조건을 충족하지 못하기 때문에 더 넉넉한 CPU와 Memory를 가진 머신 타입으로 변경해야 합니다.
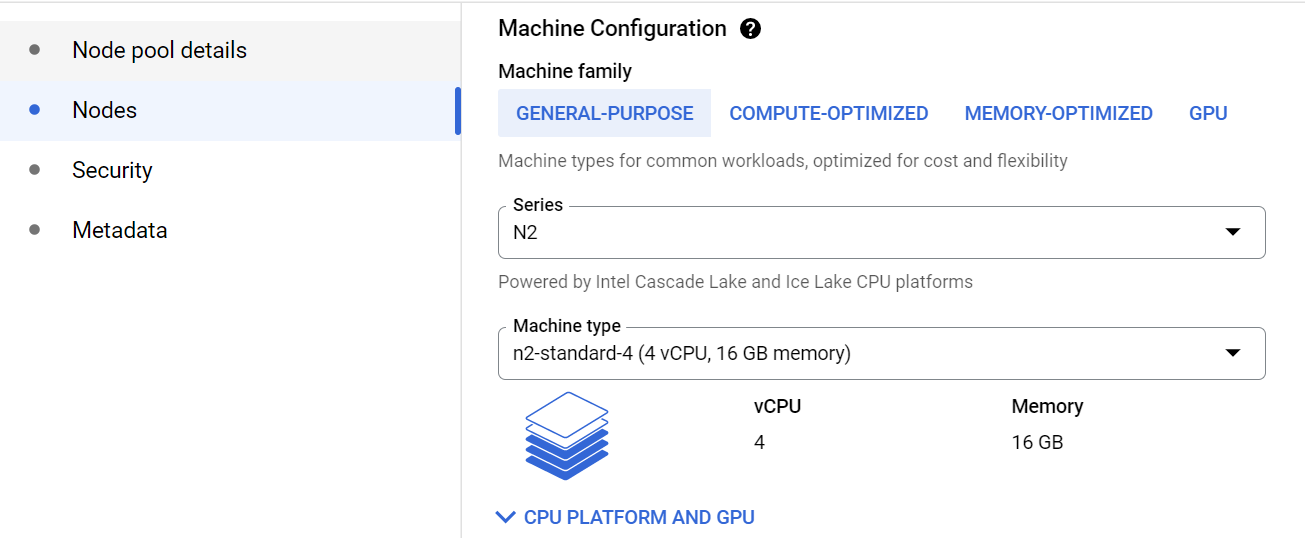
마지막으로 Security 탭에서 Access scope를 "Allow full access to all Cloud APIs"로 변경합니다. 프로덕션 환경에서는 권장되지 않는 옵션이지만 테스트 구성이므로 본 포스팅에서는 이 설정으로 생성합니다.
위 사항들을 변경했다면 CREATE 버튼을 눌러 클러스터를 생성합니다.
1-2. GKE Cluster 구성 및 Helm 설치
이렇게 GKE Cluster 구성은 쉽게 끝났습니다. 이제 클러스터를 이용하기 위한 사전 작업을 해보겠습니다.
우선 kubectl 명령어로 클러스터를 조작하기 위해 Kubernetes Cluster의 Credential을 얻는 작업을 해야 합니다.
생성한 GKE 클러스터를 이용할 수 있는 환경에서 아래 명령어를 실행합니다. Cloud Shell 환경이 가장 이상적입니다.
|
1
|
gcloud container clusters get-credentials CLUSTER_NAME --region REGION
|
cs |

이후 kubectl get pods -n kube-system 명령어를 실행해 인증 작업이 정상적으로 실행되었는지 확인합니다.
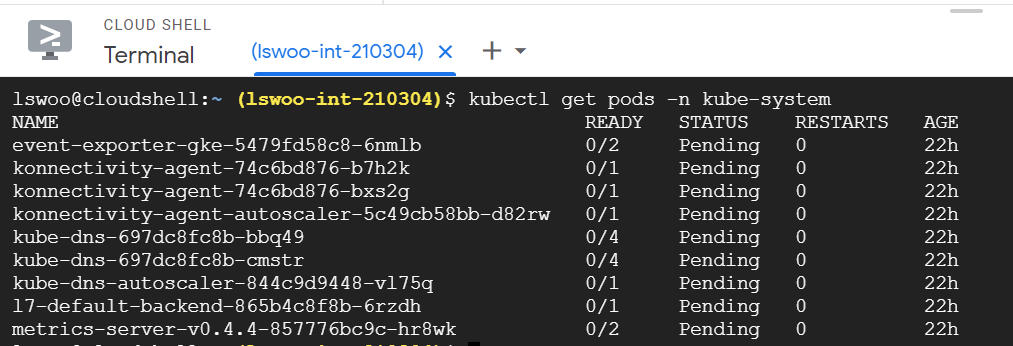
kubectl create ns es 명령어로 ELK Stack을 설치하기 위한 네임스페이스 "es"를 생성합니다.
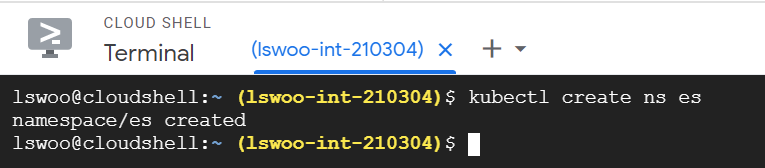
이제 클러스터에 Helm을 설치해 ELK Stack을 구축하기 위한 준비를 해보겠습니다.

Helm은 Kubernets의 패키지 매니징 툴로 Kubernetes에 특정 환경을 구성하기 위해 수 많은 리소스 매니페스트들을 적용할 필요 없이 이를 패키지화해서 사용할 수 있게끔 해주는 편리한 도구입니다.
마치 리눅스의 apt나 yum과 같은 패키지 매니저를 Kubernets 버전으로 사용한다고 생각하면 쉽습니다. 이제 Helm을 이용해서 편리하게 ELK Stack 패키지를 설치할 예정입니다.
Helm 설치는 Helm 공식 도큐먼트에 명시되어 있습니다. 환경에 따라서 설치 방법이 다르기 때문에 문서를 참고해 설치하도록 합시다.
Cloud Shell은 Debian linux이기 때문에 아래 명령어를 입력해 Helm을 설치합니다.
|
1
2
3
4
5
|
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
sudo apt-get install apt-transport-https --yes
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
|
cs |
Helm을 설치했다면 helm version 명령어를 실행해 정상적으로 설치되었는지 확인합니다.

ELK Stack을 Helm으로 설치하기 위해서는 elastic의 helm 레포지토리를 추가해아 합니다. 아래 명령어로 elastic helm repository를 추가합니다.
|
1
|
helm repo add elastic https://helm.elastic.co
|
cs |
h

2. ELK Stack 구축
2-1. ELK Stack 설치
이제 설치한 Helm을 이용해서 ELK Stack의 구성요소인 Elasticsearch, Logstach, Kibana를 설치하겠습니다.
아래 Helm 명령어를 실행해 Elasticsearch를 GKE Cluster에 설치합니다.
|
1
|
helm install elasticsearch elastic/elasticsearch -n es
|
cs |
이후 pod가 잘 생성되었는지 확인합니다.
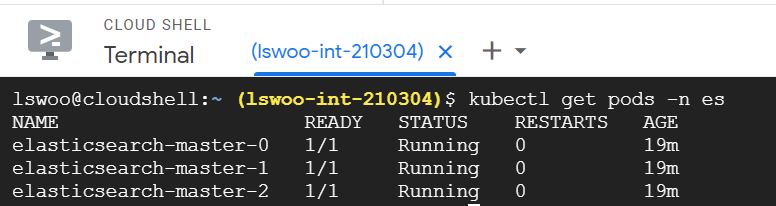
생성된 Elasticsearch 파드들을 유심히 살펴보면 Statefulset 오브젝트에 의해 제어되는 것을 생성된 것을 알 수 있습니다.
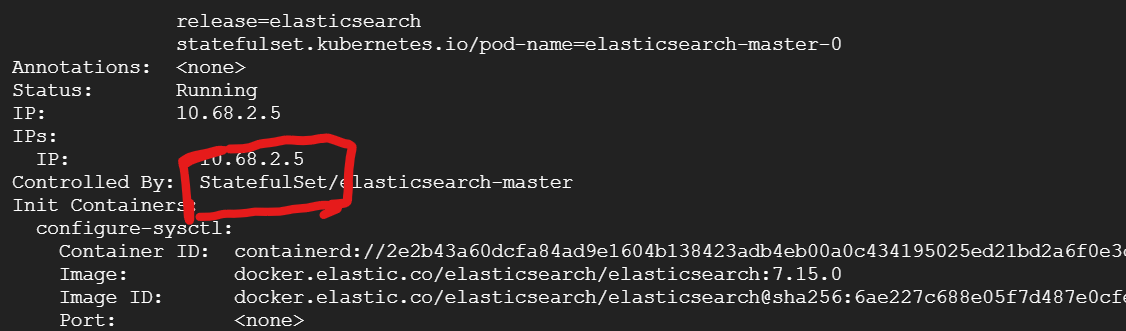
왜 Statefulset 오브젝트로 Elasticsearch 파드를 올렸을까요?
statefulset 오브젝트는 deployment 오브젝트와 비교했을때 몇가지 다른 점이 있습니다.
첫째는 statefulset은 deployment와 달리 각 파드가 독자성을 가지고 생성된다는 것이고,
두번째는 독자성을 띄기 위해 Statefulset은 헤드리스 서비스를 사용하고 볼륨을 특정 파드에 고정한다는 특징을 가진다는 것입니다.
이런 특징 때문에 Statefulset은 상태를 저장하는 스테이트풀(Stateful) 어플리케이션에 적합하고 deployment는 상태를 비저장하는 스테이틀리스(Stateless) 어플리케이션에 적합하게 된 것입니다.
Elasticsearch 어플리케이션은 관측 가능성 지표나 각종 상태를 저장해야 하는 스테이트풀(Stateful) 어플리케이션이기 때문에 Statefulset 오브젝트로 생성하는 것입니다.
다음으로 ELK Stack에서 데이터 파이프라인 역할을 맡는 Logstash를 설치합니다.
Helm install을 실행해 Logstash를 설치하면 되지만, 기본값으로 설정되어 있는 helm 설치 구성을 변경해야 합니다. 기본 설정값에는 Logstash가 로그 및 메트릭을 받을 input 값이 제대로 설정되어 있지 않기 때문입니다.
아래 명령어로 Logstash 설치에 사용되는 values.yaml 파일을 가져옵니다.
|
1
|
curl -O https://raw.githubusercontent.com/elastic/helm-charts/main/logstash/values.yaml
|
cs |
이 values.yaml 파일에서 logstashPipeline 어트리뷰트를 다음과 같이 변경해줍니다.
- Logstash는 로그를 담당하는 filebeat와 메트릭을 담당하는 metricbeat 2개에서 관측 가능성 지표를 각각 5045, 5048 포트로 받을 예정입니다.
- 필터 부분은 현재 host네임을 처리하는데 있어 이슈가 있기 때문에 workaround로 넣었습니다.(21-12-14 현재 해당 부분을 안넣으면 Logstash에서 에러를 뿜습니다.)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
logstashPipeline:
logstash.conf: |
input {
exec { command => "uptime" interval => 30 }
beats {
port => 5045
ssl => false
}
beats {
port => 5048
ssl => false
}
}
filter { mutate {
rename => ["host", "hostname"]
convert => {"hostname" => "string"}
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch-master:9200"]
}
}
|
cs |
이렇게 Logstash는 Input과 Filter, Output 3가지 요소를 기반으로 데이터 처리 파이프라인을 구성할 수 있습니다.
이제 아래 명령어를 실행해서 Helm으로 Logstash를 설치합니다.
|
1
|
helm install logstash elastic/logstash -n es -f values.yaml
|
cs |
logstash 설치가 정상적으로 되었는지 확인합니다.
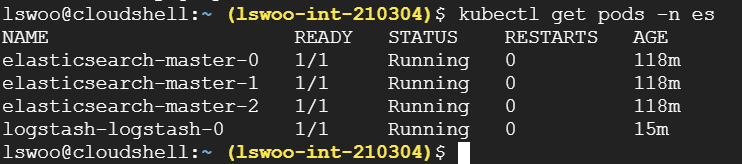
확인해보면 logstash 또한 statefulset으로 생성된 것을 확인할 수 있습니다.
위처럼 pod 이름이 랜덤값이 아닌 0..1... 등의 incremental한 숫자 suffix가 붙으면 statefulset 오브젝트인 것을 쉽게 확인할 수 있습니다.
추가적으로 Logstash가 beat라는 경량화된 에이전트에서 로그를 가져올 수 있도록 아래 매니페스트로 새 서비스를 생성합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
apiVersion: v1
kind: Service
metadata:
name: logstash-beat
spec:
selector:
app: logstash-logstash
ports:
- name: filebeat
port: 5048
protocol: TCP
targetPort: 5048
- name: metricbeat
port: 5045
protocol: TCP
targetPort: 5045
|
cs |
다음으로는 아래 명령어로 데이터 시각화를 위한 대쉬보드 툴인 Kibana를 설치합니다.
|
1
|
helm install kibana elastic/kibana -n es
|
cs |
kibana를 설치하면 파드가 deployment에 의해 제어되고 있는 것을 알 수 있습니다.
kibana는 데이터를 시각화해줄뿐인 어플리케이션이므로 상태를 저장할 필요가 없는 Stateless 어플리케이션입니다.
때문에 Elasticsearch나 Logstash와 달리 kibana는 deployment로 생성합니다.

kibana 대쉬보드를 보기 위해 아래 명령어로 port-forwarding 해줌으로써 kibana 파드를 localhost로 노출합니다
.
|
1
|
kubectl port-forward deployment/kibana-kibana 5601 -n es &
|
cs |
이후 브라우져에서 localhost:5601로 들어가면 kibana 대쉬보드 페이지를 볼 수 있습니다.
만약 Cloud shell에서 작업하고 있었다면 "Web preview" 버튼을 클릭해 기존 8080으로 되어 있는 포트를 "Change port"로 5601로 바꿔준 뒤 Preview on port 5601을 클릭합니다.
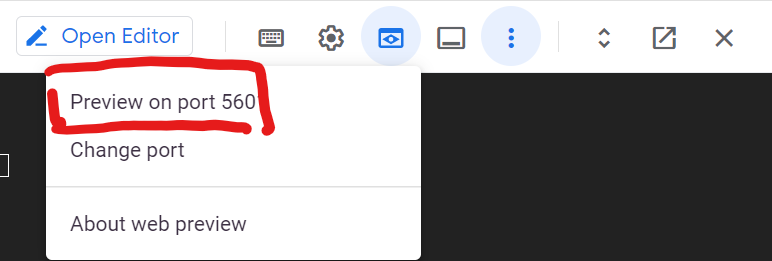
이후 나오는 브라우저 탭에서 Kibana 페이지를 확인할 수 있습니다.
2-2. Beat 설치
지금까지 ELK Stack을 구성하는 Elasticsearch, Logstach, Kibana를 모두 설치했습니다.
이 구성요소만 설치해도 기본적인 로그 수집, 변형, 저장 및 대쉬보드 표출의 기능을 다 할 수는 있지만,
Elastic에서 제공하는 경량화된 수집 에이전트인 Beat도 추가적으로 사용해서 지표를 수집해보겠습니다.
Beat는 보통 원격지에 설치해 Logstash나 Elasticsearch 서버로 로그나 메트릭을 지속적으로 보내주도록 구성하지만, 이번 포스팅에서 수집할 로그와 메트릭들은 특정 원격지에 beat를 설치할 필요가 없으므로 기존 GKE Cluster에 설치합니다.
우선 로그를 수집할 수 있는 Beat인 Filebeat를 설치합니다.
Filbeat도 Logstash와 마찬가지로 새로운 value.yaml 파일을 사용하여 설치해야 하므로 아래 명령어로 value.yaml 파일을 가져옵니다.
|
1
|
curl -O https://raw.githubusercontent.com/elastic/helm-charts/main/filebeat/values.yaml
|
cs |
그리고 value.yaml 파일 중 filebeatConfig 어트리뷰트를 아래와 같이 변경합니다.
- 이 Helm chart는 daemonset와 deployment 둘 중 하나를 선택해서 생성할 수 있습니다. 이번 포스팅은 daemonset.enabled: false로 설정해 filebeat를 Deployment로 구성합니다.
- 기존에는 없던 module.gcp.yml 파일을 새로 생성하고 filbeat.config 파일 변경으로 gcp 모듈을 사용하도록 합니다.
- var.topic과 var.subscription_name 값은 미리 생성할 Pub/sub 토픽과 서브스크립션 이름으로 지정합니다.
- 기존 output.elasticsearch 어트리뷰트를 output.logstash로 변경해서 Filebeat가 Elasticsearch가 아닌 Logstash를 바라보도록 합니다. hosts 란의 주소는 Logstash에서 생성한 Service와 port를 넣습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
daemonset:
# Annotations to apply to the daemonset
annotations: {}
# additionals labels
labels: {}
affinity: {}
# Include the daemonset
enabled: false
...
filebeatConfig:
module.gcp.yml: |
- module: gcp
vpcflow:
enabled: false
firewall:
enabled: false
audit:
enabled: true
var.project_id: PROJECT_ID
var.topic: TOPIC_NAME
var.subscription_name: SUB_NAME
filebeat.yml: |
filebeat.config:
modules:
enabled: true
path: ${path.config}/module.*.yml
reload.enabled: true
filebeat.inputs:
- type: log
paths:
- /usr/share/filebeat/logs/filebeat
output.logstash:
host: "${NODE_NAME}"
hosts: "logstash-beat:5048"
# username: "${ELASTICSEARCH_USERNAME}"
# password: "${ELASTICSEARCH_PASSWORD}"
|
cs |
3. GCP -> ELK 연동
3-1. GCP Audit log 내보내기
ELK Stack 및 Beat 설치로 Elastic-system을 구축했다면 이제 GCP의 각종 지표들을 Elastic-system으로 내보내 GCP 관측 가능성을 확보해보겠습니다.
첫 번째로 내보낼 지표는 감사를 위한 Audit log입니다. Audit log를 Elastic-system로 내보냄으로써 감사를 위한 각종 로그들을 중앙화할 수 있습니다.
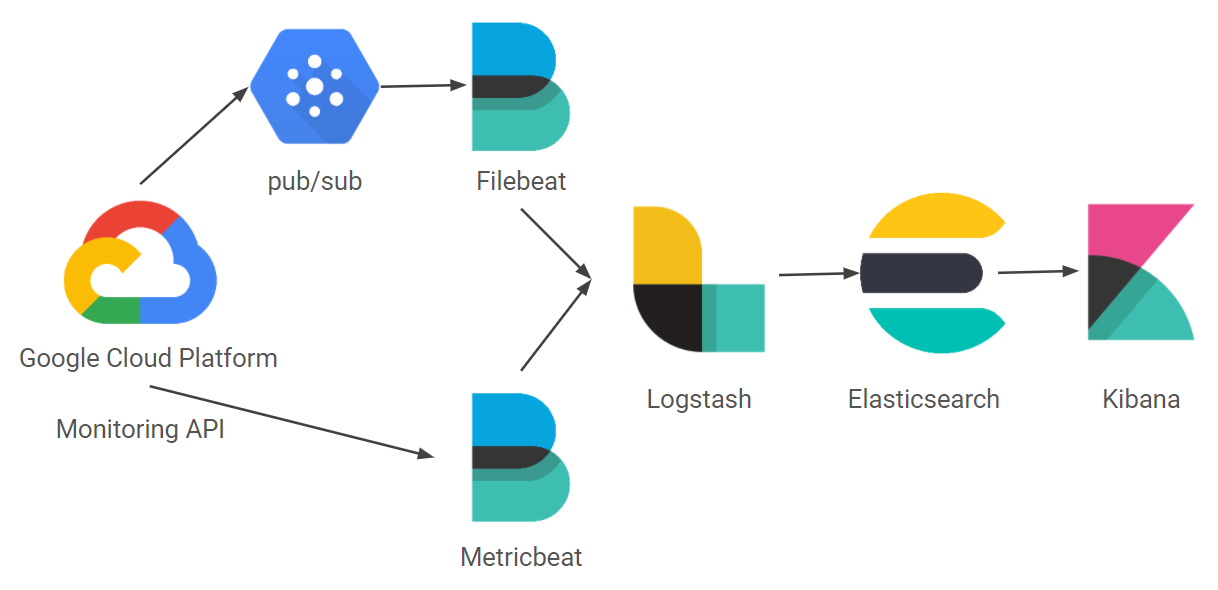
GCP Audit log는 Beat 중 로그를 수집하기 위한 용도인 Filebeat로 받을 수 있습니다. 로그는 내보내는 주체는 GCP Operations의 Logging bucket입니다. FIlebeat와 Logging bucket 사이에는 Pub/sub 메세징 서비스가 개입해서 더 견고하게 메세지를 보낼 수 있도록 합니다.
이 과정을 진행했을 시 구성도는 다음과 같습니다.

위 구성을 구축하기 위해 우선 메세징 서비스인 Pub/sub을 생성하도록 합니다. 이름은 FIlebeat 구성 중 지정했던 pub/sub 이름으로 지정합니다.

이후 아래 명령어를 실행해 로그를 Pub/sub으로 라우팅하는 로그 싱크를 생성합니다.
|
1
2
3
|
gcloud logging sinks create gcp_audit-es-sink \
pubsub.googleapis.com/projects/PROJECT-ID/topics/TOPIC_NAME \
--log-filter='logName="projects/PROJECT-ID/logs/cloudaudit.googleapis.com%2Factivity" OR "projects/PROJECT-ID/logs/cloudaudit.googleapis.com%2Fdata_access" OR "projects/PROJECT-ID/logs/cloudaudit.googleapis.com%2Fsystem_event"'
|
cs |
명령어가 정상적으로 실행되었다면 아래와 같은 메세지가 출력됩니다.
Please remember to grant `serviceAccount:p389871272152-849520@gcp-sa-logging.iam.gserviceaccount.com` the Pub/Sub Publisher role on the topic. More information about sinks can be found at https://cloud.google.com/logging/docs/export/configure_export
메세지 중 "serviceAccount:" 로 시작하는 서비스 어카운트에 방금 생성한 Pub/sub topic의 Pub/sub Publisher 권한을 부여합니다.
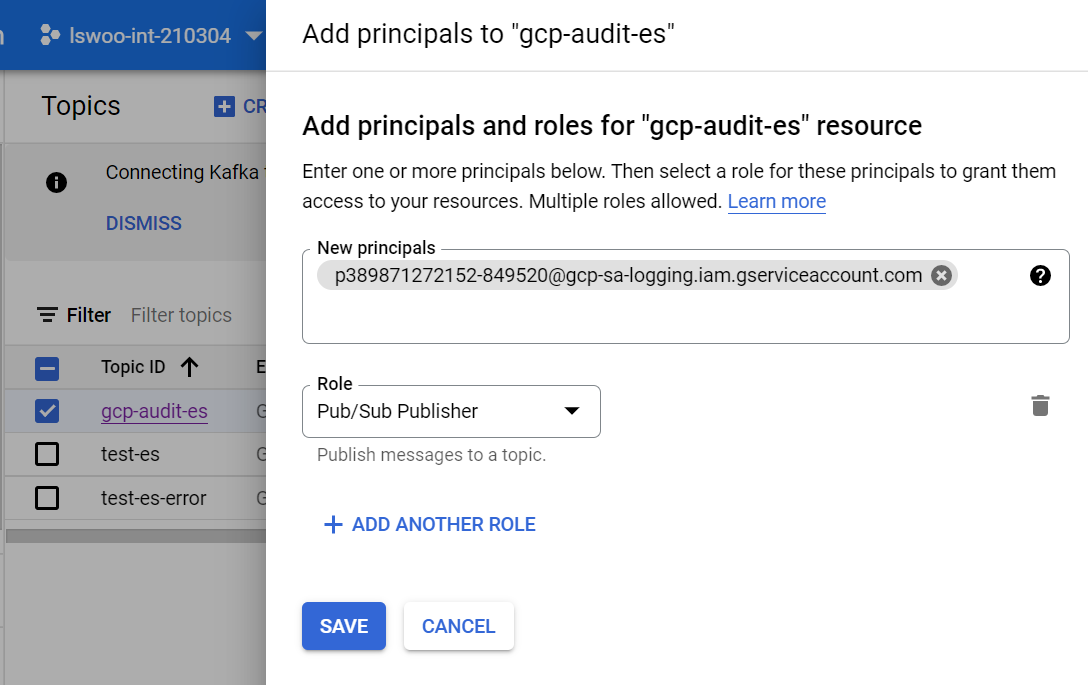
권한을 정상적으로 부여했다면 기존에 구성되어 있었던 Filebeat와 Logstash 컨피그에 의해 GCP Audit log가 Elasticsearch로 쌓이게 됩니다.
이제 GCP Audit 로그들을 Kibana 대쉬보드에서 확인할 수 있습니다.
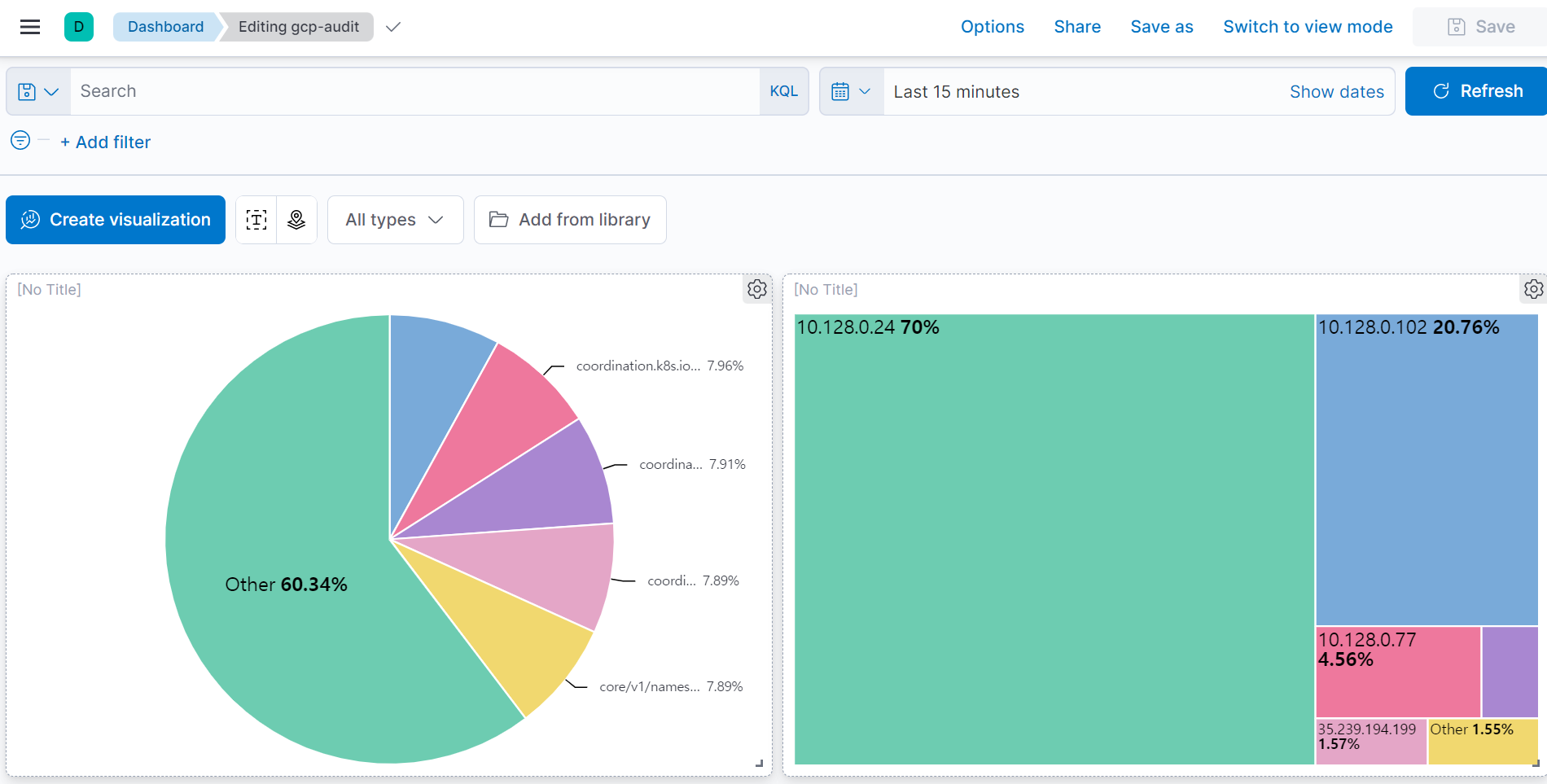
3-2. GCP Monitoring metric 내보내기
Filebeat를 이용해서 로그를 수집할 수 있었다면 Metric beat를 이용해서는 시간에 따른 숫자값인 메트릭을 수집할 수 있습니다.
GCP의 Operations monitoring에서 생성하는 각종 메트릭들을 이 Metricbeat로 바로 받을 수 있기 때문에 GCP의 메트릭 관측 가능성을 확보하는데 도움받을 수 있습니다.
그렇기에 추가적으로 Metric beat도 설치해서 각종 메트릭에 대한 관측 가능성도 확보해보겠습니다.
이 과정을 진행하면 아래 구성도가 완성됩니다.
Metricbeat도 기본 value.yaml 값이 아닌 새로운 값으로 치환해서 생성해야 합니다. 아래 명령어로 Metricbeat의 value.yaml 파일을 가져옵니다.
|
1
|
curl -O https://raw.githubusercontent.com/elastic/helm-charts/main/metricbeat/values.yaml
|
cs |
이후 가져온 value.yaml 파일 중 명시된 부분만 아래와 같이 변경합니다.
- Metricbeat도 daemonset와 deployment 중 하나를 선택해서 사용합니다. deployment를 사용할 것이므로 "daemonset.enabled: false" 로 변경합니다.
- deployment 하위 어트리뷰트인 metricbeatConfig 어트리뷰트는 gcp 모듈을 사용하게끔 변경하고 메트릭을 보낼 상대를 기존 elasticsearch에서 logstash로 변경합니다.
- setup.kibana 어트리뷰트를 추가해야 정상적으로 메트릭이 들어옴에 주의합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
daemonset:
# Annotations to apply to the daemonset
annotations: {}
# additionals labels
labels: {}
affinity: {}
# Include the daemonset
enabled: false
...
deployment:
...
metricbeatConfig:
metricbeat.yml: |
metricbeat.modules:
- module: gcp
enabled: true
metricsets:
- metrics
project_id: "PROJECT_ID"
exclude_labels: false
period: 60s
metrics:
- aligner: ALIGN_NONE
service: compute
metric_types:
- "instance/cpu/reserved_cores"
- "instance/cpu/usage_time"
- "instance/cpu/utilization"
- "instance/uptime"
output.logstash:
host: "${NODE_NAME}"
hosts: "logstash-beat:5045"
setup.kibana: host: "kibana-kibana:5601" |
cs |
이후 아래 명령어를 사용하여 Metricbeat를 설치합니다.
|
1
|
helm install metricbeat elastic/metricbeat -n es -f value.yaml
|
cs |
설치가 완료되었다면 이제 메트릭 또한 Kibana 대쉬보드에서 확인할 수 있습니다.
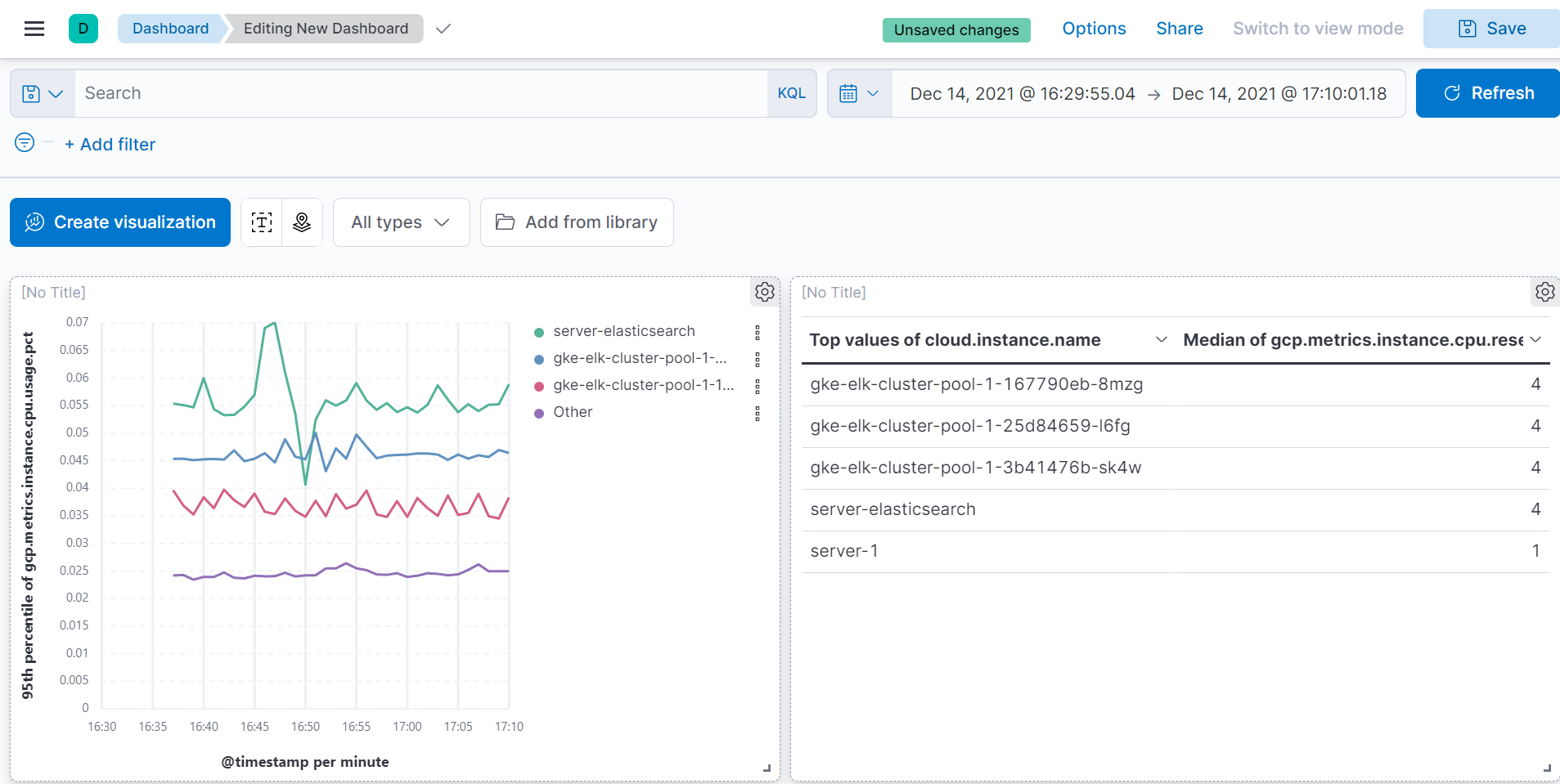
3. 마무리
지금까지 GCP의 Audit log와 각종 Metric들을 Elastic-system에 중앙화하는 작업을 해봤습니다.
다만 Elastic-system 자체로 굉장히 많은 기능을 지원하고 있기 때문에 본격적으로 사용하시려면 이번 포스팅에서보다 더 많은 요소들을 참고해야 합니다. 또한 Elastic-system을 프로덕션 환경에서 사용하기 위한 구성은 Elastic 공식 도큐먼트를 참고하셔야 합니다.(SSL, 암호화, 인증, 라이센스 등..)
어디까지나 본 포스팅의 목적은 GKE 환경 위에 ELK Stack을 구축하는 것에 집중했으므로 이를 참고해주시면 감사하겠습니다.
포스팅을 보신 분들이 GKE 환경에서 Elastic-system을 구축하는데 도움이 되었으면 합니다.
'Observability' 카테고리의 다른 글
| Elasticsearch에 fluentd를 얹은 EFK stack 구축하기(with kubernetes) (9) | 2022.01.08 |
|---|---|
| 클라우드 리소스 Observability 확보 도구 Steampipe 사용기 + GCP IAM report 제작기 (0) | 2021.12.27 |
| GKE Prometheus, Loki, Grafana로 Monitoring dashboard 구성하기(3) (0) | 2021.08.20 |
| GKE Prometheus, Loki, Grafana로 Monitoring dashboard 구성하기(2) (0) | 2021.08.12 |
| GKE Prometheus, Loki, Grafana로 Monitoring dashboard 구성하기(1) (2) | 2021.08.10 |