

EFK stack이란 Elasticsearch, Fluentd, Kibana를 얹은 스택을 말합니다.
기존의 ELK stack과는 로그 파이프라인 역할을 하던 Logstash를 Fluentd로 대체했다는 차이점이 있습니다.
그럼 Fluentd를 사용한 EFK stack은 ELK stack과 어떤 점이 다른지, 각자 어떤 장단점이 있는지 살펴보겠습니다.
그리고 Kubernetes 환경에서 EFK stack을 구축해 컨테이너 로그를 중앙화하는 실습도 함께 보도록 하겠습니다.
1. Fluentd란?
우선 Fluentd가 어떤 툴인지 먼저 알아봐야 겠습니다. 가장 먼저 Fluentd를 만나볼 수 있는 곳은 CNCF 프로젝트인데요.
fluentd는 몇 안되는 CNCF의 graduated project 중 하나입니다. 그 만큼 프로젝트가 성숙하고 레퍼런스가 많다는 뜻이겠죠.

Fluentd는 다양한 소스에서 로그를 수집해 중앙화할 수 있는 오픈소스 데이터 콜렉터입니다. 즉 다양한 시스템에서 들어오는 여러 로그들을 fluentd 하나로 수집하고 파싱하고 포워딩할 수 있습니다.
이러한 특징으로 인해 시스템마다 각각의 로깅 툴을 사용하고 각기 다른 저장 장소에 로그가 흩어져 있던 기존의 로깅 아키텍처를 fluentd 하나로 통합할 수 있다는 장점이 있습니다.
특히 점점 복잡해지고 있는 MSA(MicroService Architecture) 환경에서 이러한 장점이 특히 빛을 발하게 됩니다. 임시적이고 유동적인 마이크로 서비스들의 로그를 한 곳에 수집하고 가공하기 위해서는 fluentd와 같은 로깅 툴이 반드시 필요합니다.
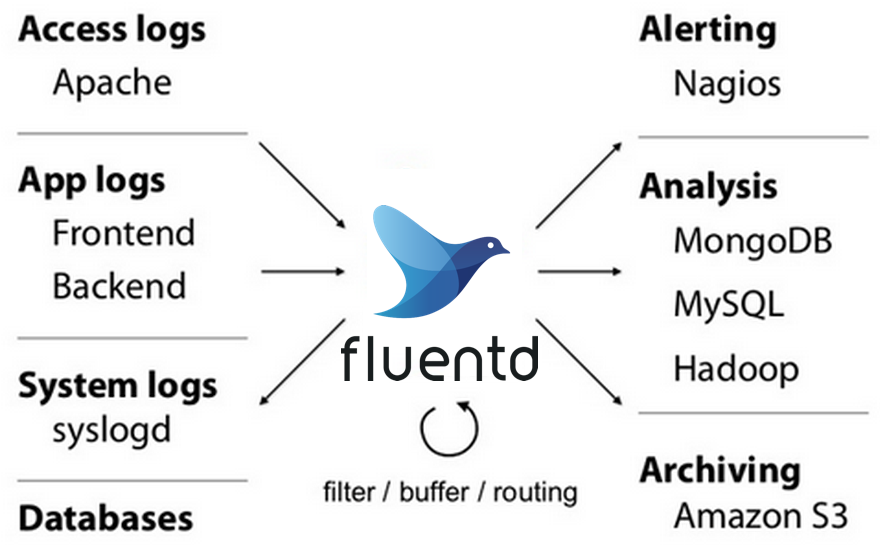
이렇게 fluentd가 다양한 시스템의 로그를 수집할 수 있는 것은 fluentd가 제공하는 다양한 플러그인 덕분입니다.
플러그인이 aws, hadoop, syslog 등등 다양한 시스템의 로그를 파싱하도록 도와주기 때문에 현재 125개가 넘는 플러그인을 제공하는 지금은 대부분의 로그들을 다룰 수 있게 되었습니다. (지원하는 플러그인 목록은 여기 참고)
fluentd는 이렇게 다기종의 시스템에서 받은 로그들을 파싱한 뒤 필요한 정보만 필터링하거나, 다른 목적지로 라우팅하거나, 원하는 정보로 가공할 수 있습니다.
오늘 구현해볼 fluentd에서는 위 기능들을 모두 이용한 통합 로깅 시스템을 구축해보겠습니다.
2. Logstash vs Fluentd
EFK 스택은 기존의 Logstash를 Fluentd로 대체해 사용하는 스택입니다. 그럼 ELK 스택과 EFK 스택을 사용했을때 어떤 점이 달라질까요? 두 스택의 다른 구성 요소인 Logstash와 Fluentd를 비교하면서 알아보겠습니다.
2-1. 성능

Logstash와 Fluentd는 둘 다 엔터프라이즈급 로그 파이프라인 구성에 사용되는 로그 분석용 파서 역할을 할 수 있습니다. 수집한 로그를 필터링,라우팅할 수 있으며, 다양한 플러그인을 사용할 수 있다는 공통점이 있습니다.
하지만 Logstash는 자체 로그 수집 기능이 없으며 Filebeat, Metricbeat같은 에이전트에서 수집한 로그를 받거나 다른 시스템과 통합하는 과정을 통해 수집된 로그를 받을 수 밖에 없습니다. 반면에 Fluentd는 자체 데몬을 통해 다양한 소스의 로그를 수집할 수 있습니다.
Logstash는 Elastic 사에서 개발한 툴이므로 Elasticsearch, Kibana 등의 다른 Elastic 툴과의 통합이 용이합니다. 하지만 Fluentd는 CNCF 재단에 속한 프로젝트로서 클라우드 네이티브 시스템, 마이크로 서비스, Prometheus와 같은 다른 CNCF 프로젝트와 함께 사용하기 용이하다는 점이 다릅니다. Elastic 사의 시스템과도 통합을 지원합니다.
Logstash는 jruby를 이용해 만들어져 JVM 위에서 돌아가지만 fluentd는 대부분 ruby로 만들어졌으며 몇몇 퍼포먼스가 중요한 부분은 C로 구성되어 있습니다. 때문에 Fluentd보다는 Logstash가 약간 더 무거운 프로세스를 실행하게 됩니다.
위 차이점 덕분에 보통 Logstash는 모놀리식한 시스템의 로깅 파이프라인으로 주로 사용하고, Fluentd는 마이크로 서비스 아키텍처를 사용한 시스템에서 주로 사용하기 용이합니다.
2-2.UI
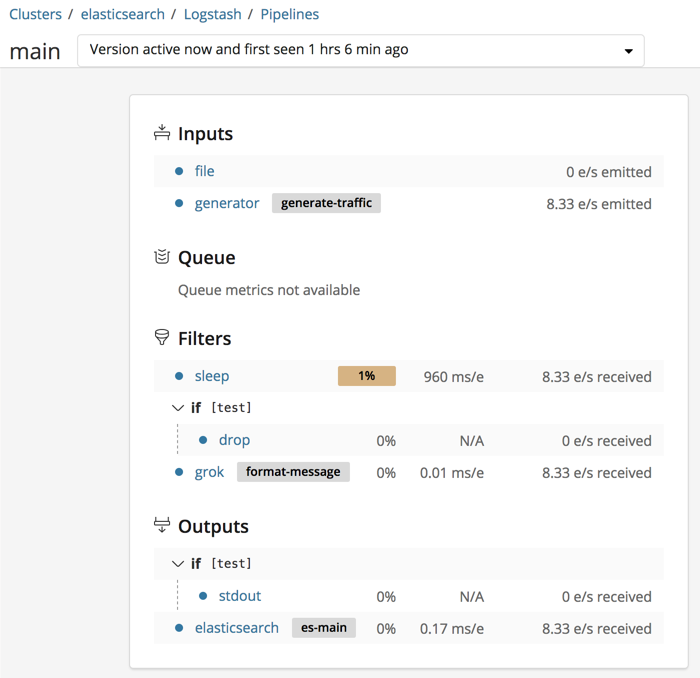
Logstash의 ui는 현재 Elastic 사의 대쉬보드 툴인 Kibana와 완전히 통합되어 있습니다. 덕분에 다른 웹 인터페이스를 따로 연동할 필요 없이 기존에 사용하던 Kibana를 연동하면 Logstash UI를 바로 이용할 수 있습니다. UI에서는 Logstash를 모니터링하거나 로그 파이프라인을 생성할 수 있습니다.
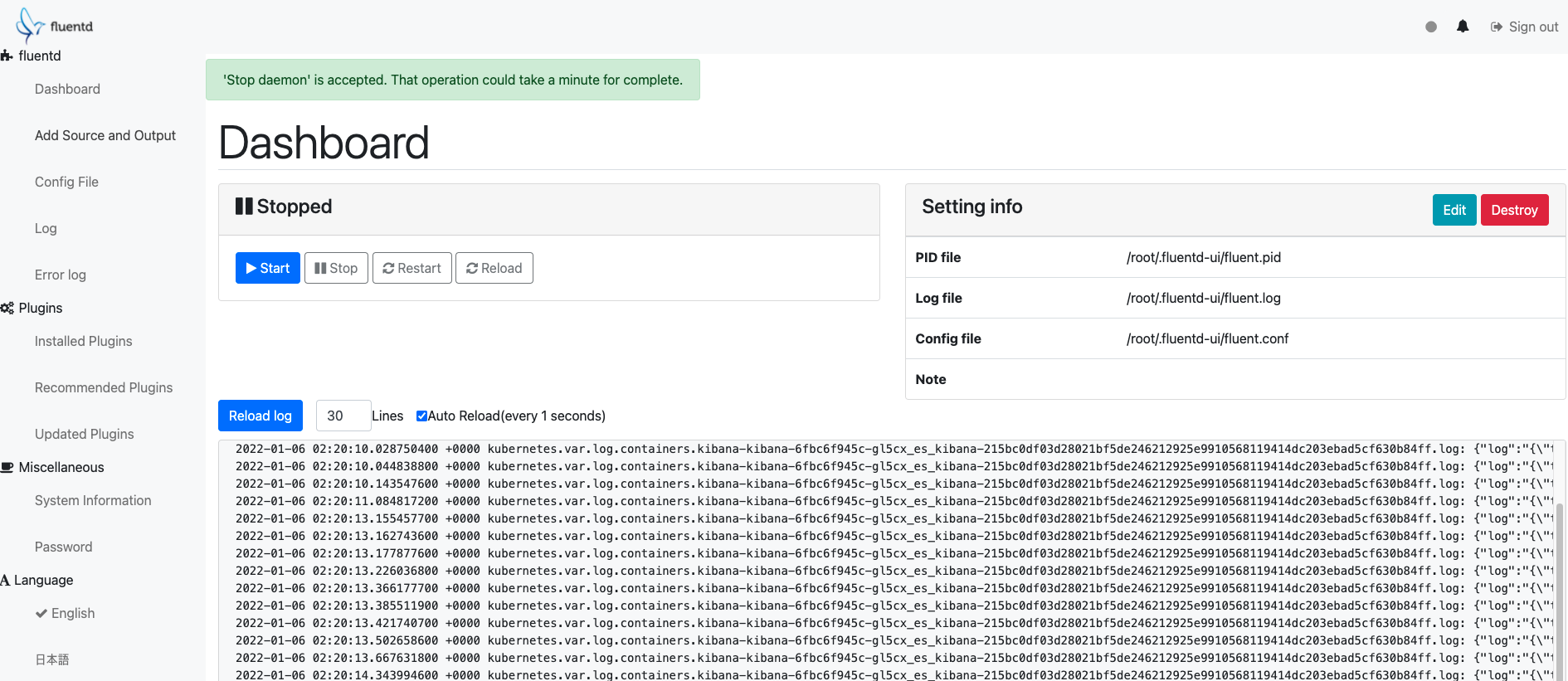
fluentd의 ui는 기존의 fluentd 프로세스를 웹 인터페이스로 보여주는 것이 아닌 fluentd-ui 데몬을 따로 실행하는 구조로 되어 있습니다. 때문에 사용하던 fluentd에 대한 대쉬보드를 보기 보다는 대쉬보드용 fluentd를 하나 더 돌린다는 생각으로 사용해야 합니다.
UI는 간단하고 필요한 기능만 들어가 있습니다. UI상에서 로그 파이프라인을 구성할 수 있으며 플러그인 설치와 관리, 로그 대쉬보드 정도가 주로 사용하는 기능입니다.
2-3. 로그 파이프라인 구성
Logstash는 If문을 사용한 플러그인 타입의 로그 분석 구조를 사용합니다. 예를 들면 다음과 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
if [type] == "end" {
elasticsearch {
hosts => ["es-server"]
query => "type:start AND operation:%{[opid]}"
fields => { "@timestamp" => "started" }
}
date {
match => ["[started]", "ISO8601"]
target => "[started]"
}
ruby {
code => 'event.set("duration_hrs", (event.get("@timestamp") - event.get("started")) / 3600) rescue nil'
}
}
|
cs |
이러한 구조는 If문을 사용할 수 있기 때문에 정교한 분석이 가능하다는 장점이 있지만 사용하는 플러그인이 많아질수록 구성이 복잡해진다는 단점이 있습니다.
fluentd는 매칭 형식의 플러그인 타입 로그 분석 구조를 가지고 있습니다. 예를 들면 다음과 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<source>
@type tail
tag system.logs
# ...
</source>
<filter app.**>
@type record_transformer
<record>
hostname "#{Socket.gethostname}"
</record>
</filter>
<match {app.**,system.logs}>
@type file
# ...
</match>
|
cs |
매우 간단한 구조이기 때문에 사용이 용이하고 다수의 플러그인을 사용하면서도 복잡하지 않다는 장점이 있지만 If문 분기를 이용한 상세한 분석은 불가능하다는 단점이 존재합니다.
2-4. EFK vs ELK

Logstash와 Fluentd 모두 스택을 구성하는 Elasticsearch 및 Kibana와 완벽한 연동을 지원하고 있습니다.
하지만 아무래도 같은 Elastic 사의 제품인 Logstash가 Kibana에서 Logstash 통합을 지원한다는 점, Elasticsearch와 같은 보안 및 기능을 공유한다는 점 덕분에 더 많은 편의성을 가지고 있습니다.
반면에 Fluentd는 Elasticsearch 플러그인을 지원한다는 점 제외하고는 더 추가적인 기능은 존재하지 않습니다.
떄문에 전체적인 스택 면에서는 ELK 스택이 더 사용하기 용이하겠으나 MSA 아키텍쳐, 클라우드 네이티브 시스템에서 fluentd가 가지는 장점이 이를 상쇄할 수 있다고 봅니다.
또한 Logstash와 Fluentd 둘 다 사용하는 하이브리드 형태의 스택도 가능하기 때문에 각자의 상황에 맞는 스택을 설치해 사용하는 것이 맞다고 생각합니다.
3. EFK 스택 구축
Fluentd를 사용하기 유리한 환경 중 하나인 Kubernetes에서 EFK 스택을 구축해보겠습니다.
3-1. Minikube 구성
Kubernets 환경은 로컬에서 클러스터를 구성할 수 있는 MInikube로 구현하겠습니다. Minikube는 테스트 용도로 간단히 Kubernetes를 구현할 수 있는 로컬 쿠버네티스 환경입니다.
Minikube를 설치하기 전에 자신의 로컬 환경이 아래 Requirements를 충족하는지 확인합니다.
- 2 CPUs or more
- 2GB of free memory
- 20GB of free disk space
- Internet connection
- Container or virtual machine manager, such as: Docker, Hyperkit, Hyper-V, KVM, Parallels, Podman, VirtualBox, or VMware Fusion/Workstation
추가적으로 Kubernetes 제어 도구인 kubectl도 이번 구성에 필요합니다.
Minikube는 아래 페이지에서 설치할 수 있습니다. 자신의 로컬 환경에 맞는 인스톨러를 설치합니다. 본 포스팅은 Mac OS, Docker 가상화 환경을 이용하여 구현했습니다.
https://minikube.sigs.k8s.io/docs/start/
minikube start
minikube is local Kubernetes
minikube.sigs.k8s.io
Minikube를 설치했다면 아래 명령어를 이용해 Minikube를 시작합니다. 기본 cpu 및 memory으로는 부족하기 때문에 플래그로 더 많은 리소스를 사용하도록 구성합니다. 리소스 구성은 현재 환경에 맞춰서 변경이 가능하지만, 최소 4 CPU, 6 gb memory로 구성하는 것을 권장합니다.
|
1
|
minikube start --memory 8192 --cpus 6 --driver docker
|
cs |
이후 minikube status 명령어나, kubectl get nodes 명령어를 통해 minikube 구성이 정상적으로 된 것을 확인할 수 있습니다.
3-2. 데모 마이크로서비스 애플리케이션 설치
로깅 시스템을 검증하기 위해서는 로그를 생성할 애플리케이션이 있어야겠죠. 이번 포스팅에서는 Google이 작성한 데모 마이크로서비스 애플리케이션을 로깅 대상으로 사용해보겠습니다.
Google의 마이크로서비스 어플리케이션 데모에 대한 자세한 내용은 아래 링크에 첨부합니다.
https://github.com/GoogleCloudPlatform/microservices-demo
GitHub - GoogleCloudPlatform/microservices-demo: Sample cloud-native application with 10 microservices showcasing Kubernetes, Is
Sample cloud-native application with 10 microservices showcasing Kubernetes, Istio, gRPC and OpenCensus. - GitHub - GoogleCloudPlatform/microservices-demo: Sample cloud-native application with 10 m...
github.com
어플리케이션은 10개가 넘는 작은 마이크로서비스로 이루어져 있기 때문에 MSA 환경의 로깅 시스템을 검증하는데 탁월합니다. 이 어플리케이션을 이전에 구성한 Minikube 환경에 배포해보겠습니다.
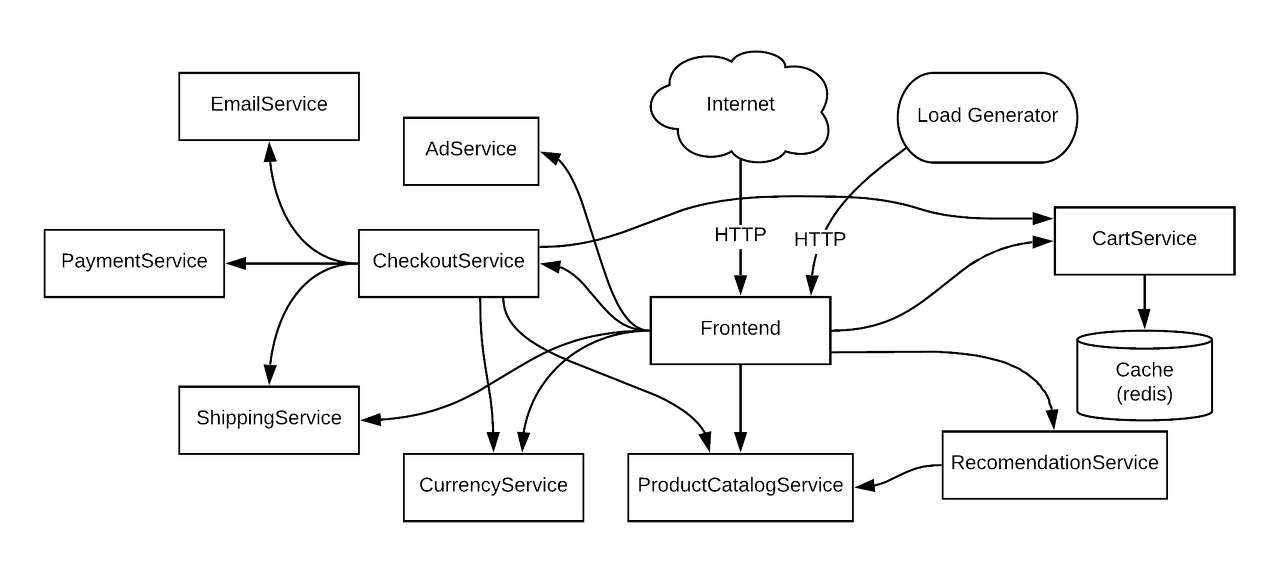
우선 아래 명령어로 깃헙 레포지토리를 가져옵니다.
|
1
|
git clone https://github.com/GoogleCloudPlatform/microservices-demo.git
cd microservice-demo |
cs |
다음 아래 명령어로 폴더에 존재하는 매니페스트들을 클러스터에 적용합니다.
|
1
|
kubectl apply -f ./release/kubernetes-manifests.yaml
|
cs |
kubectl get pods 명령어로 클러스터에 배포가 잘 이루어졌는지 확인합니다.
이제 웹 서비스에 접속하기 위해 kubectl get svc 로 서비스 생성 리스트를 보면 LoadBalancer 리소스인 frontend-external의 EXTERNAL-IP가 항상 pending으로 되어 있는 것을 볼 수 있습니다.
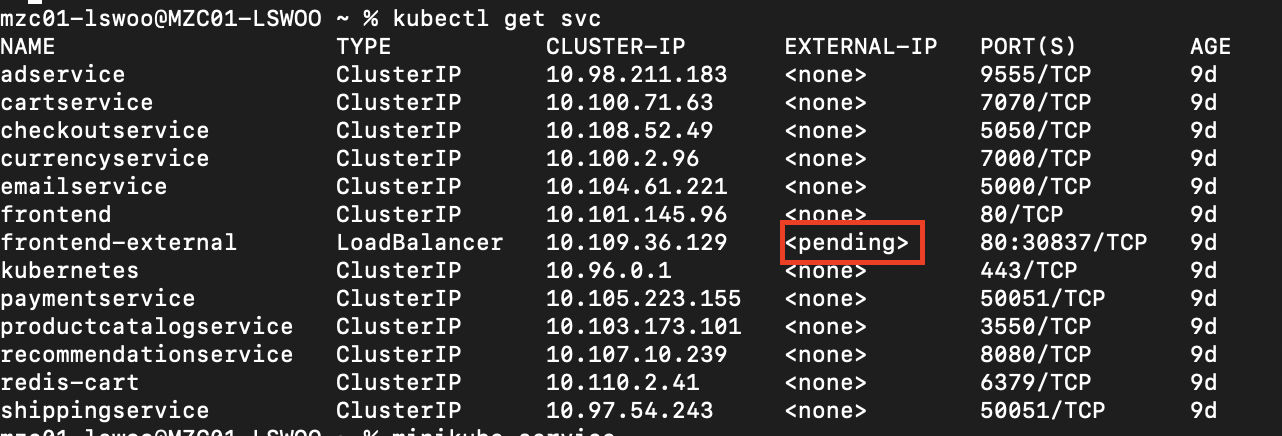
GKE나 EKS같은 클라우드 프로바이더가 제공하는 플랫폼에서 LoadBalancer 리소스를 생성하면 프로바이더는 각자의 로드밸런서 서비스를 사용해 External IP를 부여할 수 있지만, Minikube는 로컬 플랫폼이기 때문에 External IP가 부여되지 않습니다.
때문에 Minikube에서 서비스를 노출하려면 다른 방법을 사용해야 합니다. minikube service list 명령어로 서비스의 목록을 확인합니다.
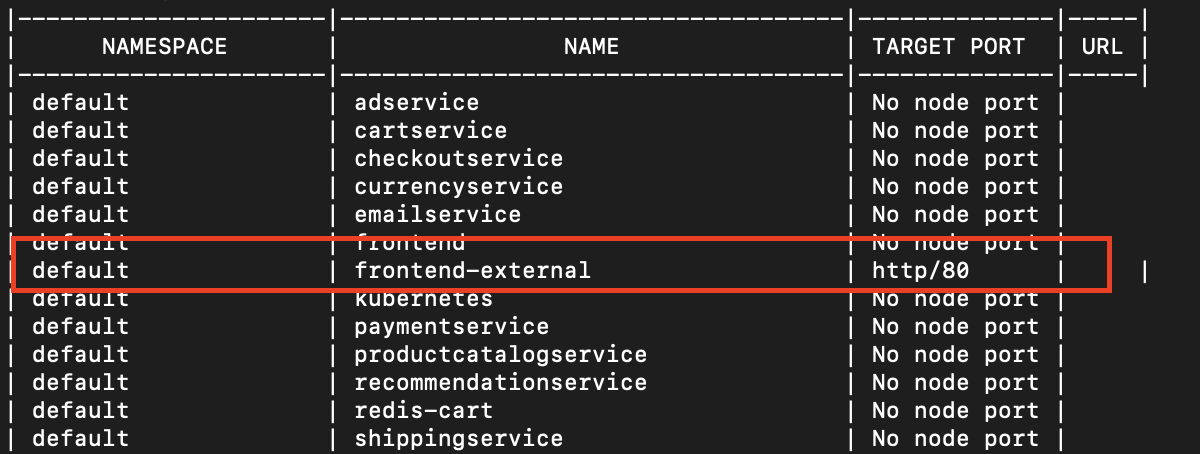
출력되는 서비스 중 LoadBalancer 리소스인 frontend-external이 80번 포트를 타겟 포트로 잡고 있는 것을 볼 수 있습니다. 이제 아래 명령어로 minikube에서 LoadBalancer를 노출합니다.
|
1
|
minikube service frontend-external
|
cs |
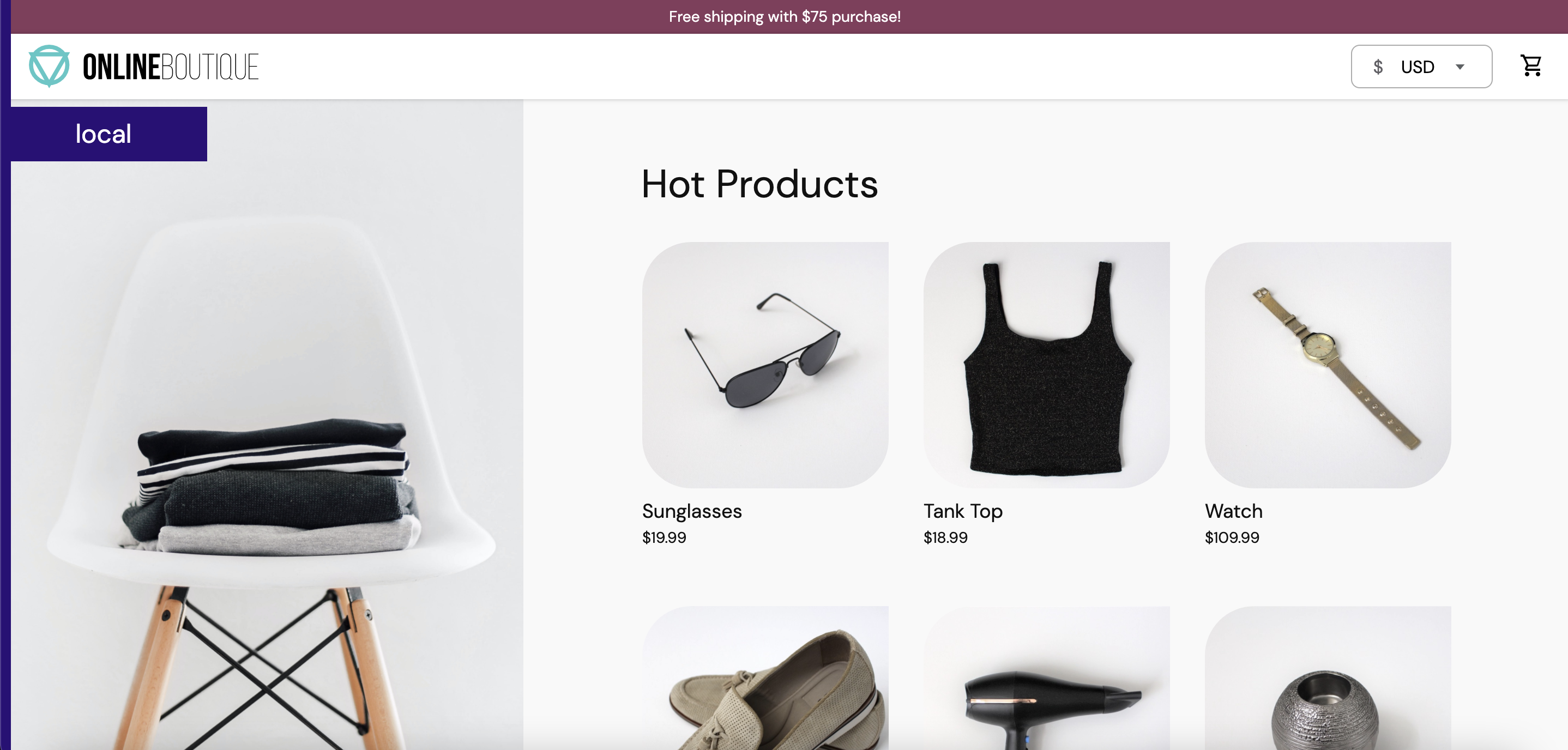
이후 아래 페이지가 뜨면 성공적으로 애플리케이션을 배포한 것입니다.
3-3. Elasticsearch 및 Kibana 설치
이제 EFK 스택에서 로그 중앙 저장소와 대쉬보드의 역할을 맡은 Elasticsearch 및 Kibana를 설치합니다.
설치에는 helm3 패키지 매니저를 사용해 진행합니다. 아래 명령어를 이용해 Elastic의 helm 레포지토리를 추가합니다.
|
1
|
helm repo add elastic https://helm.elastic.co
helm repo update |
cs |
이후 아래 EFK 스택을 위한 네임스페이스를 생성한 뒤 그 네임스페이스에 Elasticsearch와 Kibana를 설치합니다.
|
1
2
3
|
kubectl create ns es
helm install elasticsearch elastic/elasticsearch -n es
helm install kibana elastic/kibana -n es
|
cs |
적용된 리소스들을 살펴보면 Elasticsearch는 3개의 pod를 관리하는 Statefulset, 그리고 이에 연결된 일반적인 ClusterIP 서비스 하나와 헤들리스 서비스 하나를 생성하는 것을 알 수 있습니다.
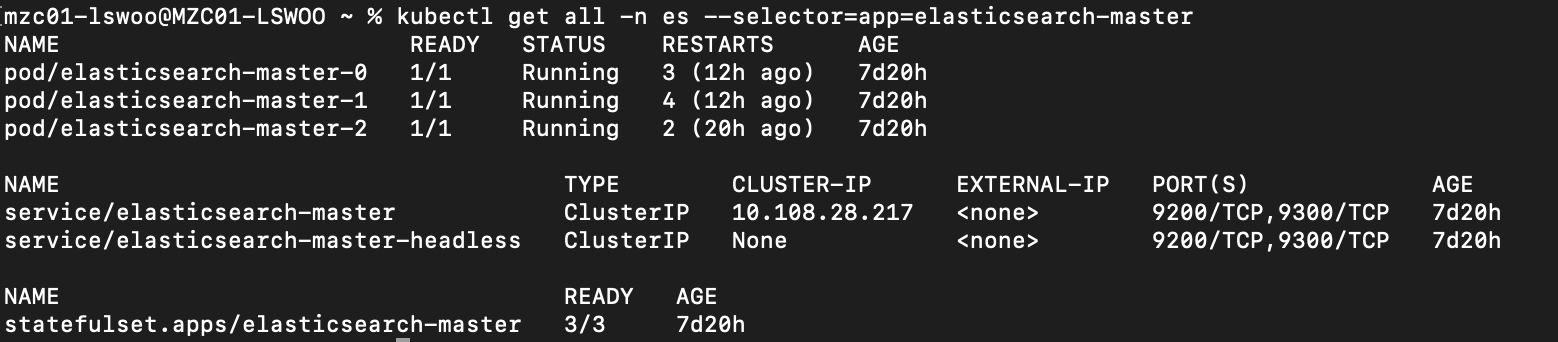
Elasticsearch는 로그를 저장해야 하는 상태 저장 애플리케이션이기 때문에 각자의 고유한 상태를 유지하는 Statefulset으로 생성하는 것이 기본값으로 되어 있습니다. 덕분에 각각의 마스터 역할을 하는 Pod마다 고유한 상태를 보유할 수 있습니다.
헤들리스 서비스를 생성해 Statefulset의 pod마다 고유한 주소로 접근할 수 있게 했으며 일반적인 서비스도 생성해 Statefulset의 Pod로의 접근을 kubeproxy에 일임할 수도 있게 구성했습니다.
추가적으로 Kibana는 웹 인터페이스의 대쉬보드이기 때문에 외부에서 접근할 수 있도록 서비스를 생성해야 합니다. 아래 매니페스트로 Kibana에 접근할 수 있는 LoadBalancer 서비스를 생성합니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
apiVersion: v1
kind: Service
metadata:
name: kibana-external
labels: app: kibana spec:
selector:
app: kibana
ports:
- port: 5601
targetPort: 5601
type: LoadBalancer
|
cs |
이제 Kibana의 구성 요소들을 살펴보면 1개의 pod를 가진 replicaset을 관리하는 deployment 하나와 ClusterIP 서비스, 그리고 방금 생성한 Loadbalancer 서비스로 구성되어 있습니다.
설치가 정상적으로 된 것을 확인하기 위해 Kibana 대쉬보드로 접근해보겠습니다. Kibana를 노출하는 LoadBalancer도 마찬가지로 minikube에서 따로 포트를 할당해줘야 외부에서 접근할 수 있습니다.
|
1
|
minikube service kibana-external -n es
|
cs |
아래와 같이 Kibana 웹 인터페이스가 보이면 잘 구성된 것입니다.

3-4. Fluentd 설치
이번 포스팅의 주인공인 Fluentd를 설치해보겠습니다.
Fluentd도 공식적으로 지원하는 Helm 차트가 존재하므로 helm을 이용해 설치합니다. 아래 명령어로 레포지토리를 추가하고 fluend를 설치합니다.
|
1
2
3
|
helm repo add fluent https://fluent.github.io/helm-charts
helm repo update
helm install fluentd fluent/fluentd -n es
|
cs |
설치가 완료되었으면 구성을 살펴봅시다. Fluentd 차트는 fluentd를 관리하는 daemonset과 이를 노출하는 ClusterIP 서비스로 이루어져 있습니다.

Kuberntes 환경에서 Fluentd가 로그를 수집하는 방법은 각 컨테이너들이 stdout,stderr로 표출되어 로깅 드라이버를 이용해 각 노드로 보내고 있는 로그들을 받아서 수집하는 것입니다. 때문에 fluentd를 기본적으로는 daemonset으로 배포하도록 되어 있습니다.
fluentd를 Daemonset으로 배포한 이유는 Fluentd가 각 노드로 모이는 로그를 수집할 수 있으려면 노드마다 에이전트를 개별적으로 배포해야 할 필요성이 있기 때문입니다. 이는 Kubernets의 로깅 아키텍처 중 노드 로깅 에이전트를 사용한 로깅을 구현한 것으로, fluentd가 노드 단의 로그를 수집해 백엔드인 Elasticsearch로 푸시하는 에이전트 역할을 합니다.
자세한 관련 내용은 Kubernetes 공식 문서의 "클러스터 레벨 로깅 아키텍쳐"에 명시되어 있습니다.
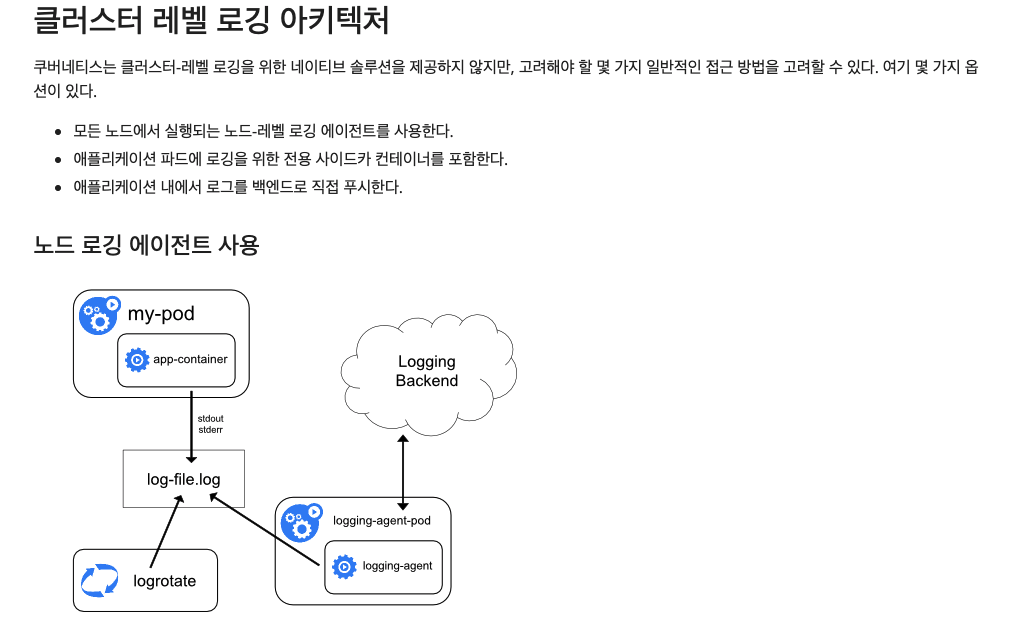
이처럼 fluentd는 여러 곳으로 흩어져 있는 컨테이너의 로그들을 하나의 공통 백엔드로 보내줄 수 있기 때문에 Kubernetes와 같은 임시적, 유동적인 마이크로서비스 환경에 적합한 로깅 도구라고 불리는 것입니다.
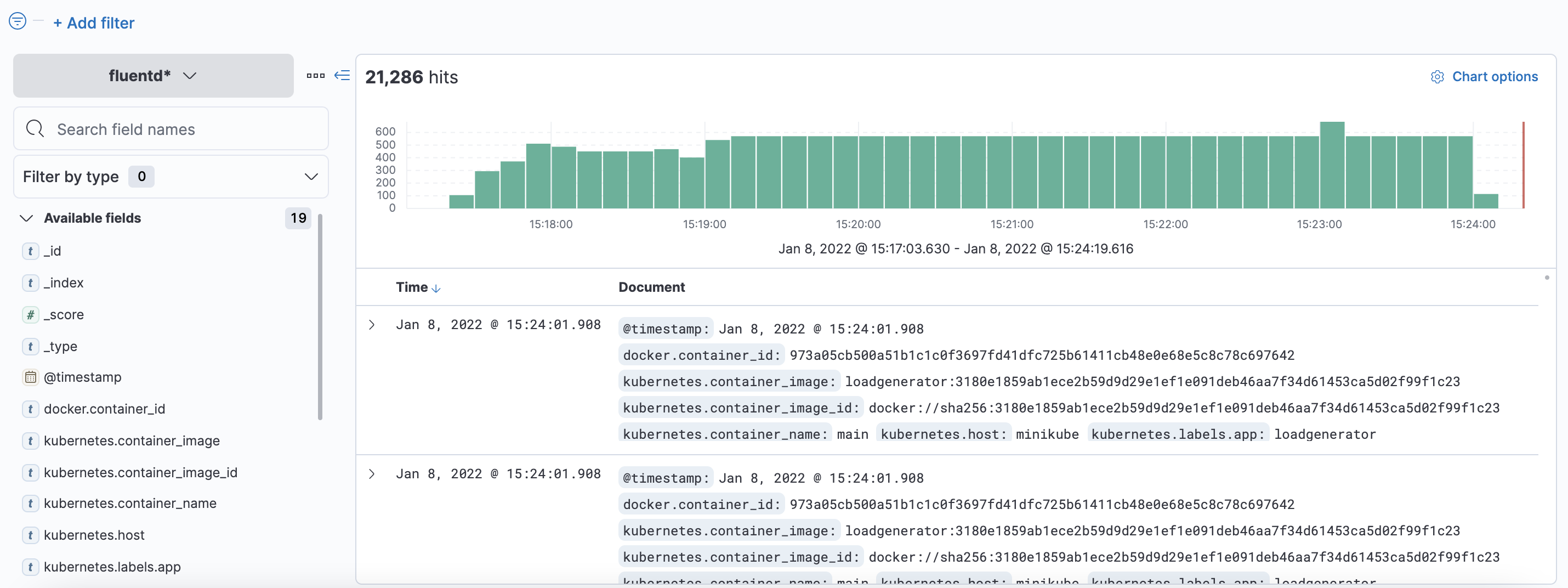
helm을 이용해 설치한 fluentd는 기본적으로 host path에 존재하는 로그를 수집해 elasticsearch로 보내기 때문에 별다른 설정 없이도 elasticsearch에 로그가 쌓이는 것을 볼 수 있습니다.
4. Fluentd 사용법
이제 데모 마이크로서비스들의 로그를 수집해 중앙화할 수 있는 EFK 스택을 성공적으로 구축했습니다. 하지만 시스템을 구축하는 것과 실제 사용하는 것은 또 다르겠죠. 이번 장에서는 구축한 EFK 스택 중, 가장 중요한 역할을 하는 Fluentd의 사용 방법에 대해서 알아보겠습니다.
먼저 fluentd의 로그 파이프라인 구성 방법부터 알아보겠습니다.
fluentd는 컨피그 파일을 이용해 로그 파이프라인을 정의합니다. 컨피그 파일의 위치는 설치 방법마다 다릅니다.
- - rpm,deb,dmg 등 패키지 이용해 설치시 컨피그 파일 위치
/etc/td-agent/td-agent.conf - - ruby gem을 이용한 설치시 컨피그 파일 위치
/etc/fluent/fluent.conf
본 포스팅에서 사용한 helm 설치는 ruby gem을 이용한 설치에 해당되기 때문에 fluentd 컨테이너의 /etc/fluentd/fluentd.conf로 접근하면 컨피그 파일을 볼 수 있습니다.

fluentd는 이 컨피그 파일을 참조해 로그를 어디서 수집하고, 어떻게 가공하고, 어디로 보낼지 결정합니다. 현재 fluentd는 아래 첨부한 6가지 행위로 컨피그 파일을 구성할 수 있습니다.

예를 들어 내가 Kubernetes 로그 파일을 읽어서 특정 내용이 담긴 로그만 Elasticsearch로 보내고 싶다면, <source>로 Kubernetes 로그 파일을 지정, <filter>로 특정 로그를 지정, <label>로 로그에 라벨링, <match>로 Elasticsearch를 지정하는 식입니다.
예시로 helm fluentd 차트는 컨피그 파일이 어떻게 구성되어 있는지 보겠습니다.
fluentd.conf
|
1
2
3
4
5
6
7
|
# do not collect fluentd logs to avoid infinite loops.
<label @FLUENT_LOG>
<match **>
@type null
@id ignore_fluent_logs
</match>
</label>
@include config.d/*.conf @include fluentd-prometheus-conf.d/*root@fluentd-wl95n:/etc/fluent# |
cs |
<label @FLUENT_LOG> .. </label>는 fluentd가 수집했던 로그에 특정 @id와 @type을 붙여 이미 fluentd가 수집한 로그를 다시 수집해 처리하는 무한 루프에 빠지지 않게 하는 지시입니다.
그 외에 @include 지시를 이용해 다른 디렉토리의 컨피그 파일도 로그 파이프라인 구성에 사용하고 있습니다. config.d 디렉토리에 존재하는 다른 컨피그 파일 중 중요한 부분만 보겠습니다.
<source> 지시를 이용해 /var/log/containers./*.log 파일을 읽게 하는 컨피그입니다. fluentd daemonset은 이미 호스트 노드의 로그 파일들을 해당 디렉토리에 마운트한 상태이기 때문에 <source>로 읽는 로그 파일들은 해당 노드에 존재하는 모든 컨테이너 로그입니다. @type은 로그를 처리할때 사용할 플러그인을 지정하는 속성으로, "tail" 플러그인은 지속적으로 파일을 읽어 스트리밍할 수 있는 플러그인입니다.
|
1
2
3
4
5
6
7
8
9
10
|
01_sources.conf: |-
## logs from podman
<source>
@type tail
@id in_tail_container_logs
@label @KUBERNETES
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
read_from_head true
... |
cs |
결과적으로 fluentd는 해당 컨피그로 인해서 노드에 존재하는 컨테이너들의 로그 파일을 지속적으로 읽게 됩니다.
다음은 로그를 내보낼 곳을 지정하는 <match> 지시입니다. @type을 elasticsearch로 지정해 수집한 로그들을 elasticsearch로 보내도록 하고 있습니다. 그 외에 elasticsearch로 접근하는데 필요한 호스트 주소와 포트 등이 지정되어 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
04_outputs.conf: |-
<label @OUTPUT>
<match **>
@type elasticsearch
host "elasticsearch-master"
port 9200
path ""
user elastic
password changeme
</match>
</label>
|
cs |
기본적으로 "elasticsearch-master"라는 IPcluster 서비스를 이용해 접근하도록 되어 있지만, 헤들리스 서비스가 생서되어 있기 때문에 "elasticsearch-master-0.elasticsearch-master-headless.default.svc.cluster.local" 같이 특정 elasticsearch 파드를 지정할 수도 있습니다.
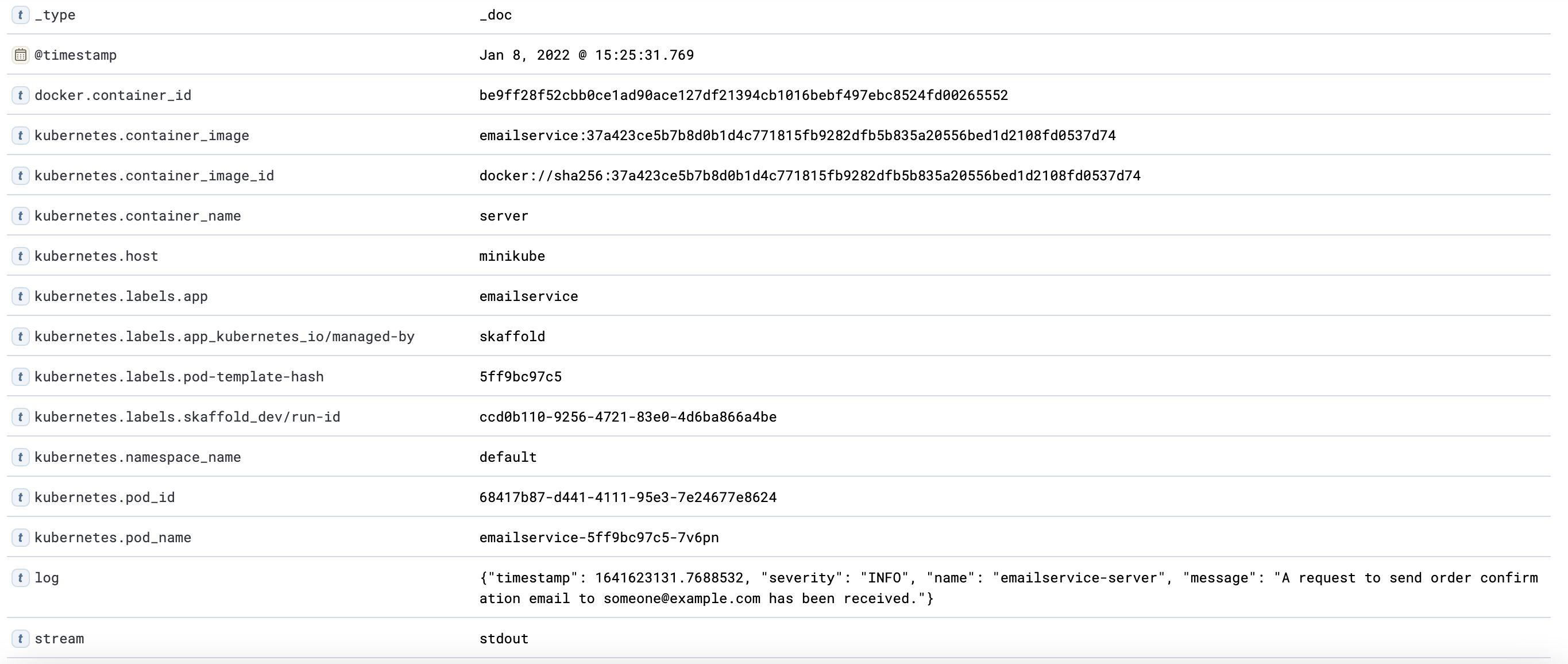
최종적으로 아래와 같이 로그가 elasticsearch에 쌓이게 됩니다.
5. fluentd-ui
지금까지 fluentd의 간단한 사용 방법에 대해서 알아봤습니다. 하지만 글만 보는 것으로는 감이 잘 잡히지 않습니다. 다행히도 fluentd는 그래피컬한 웹 인터페이스인 fluentd-ui를 제공하고 있는데요. 이 ui를 이용하면서 fluentd에 대한 감을 잡는 것도 좋아 보입니다. 이번 장에서는 fluentd-ui 구성 방법과 사용법에 대해서 설명합니다.
현재 fluentd 컨테이너는 fluentd-ui 설치에 필요한 패키지가 없기 때문에 기존에 설치된 fluentd 컨테이너의 구성을 변경하겠습니다.
|
1
|
kubectl edit daemonset fluentd -n es
|
cs |
아래와 같이 fluentd 컨테이너에 "command" 속성을 추가해 필요한 패키지를 설치하고 fluentd-ui를 구성 및 시작하도록 커맨드를 지정합니다. 마지막의 entrypoint.sh는 마지막에 실행해야 기존의 fluentd 데몬이 돌아가므로 꼭 넣어줍니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
...
Containers: fluentd:
Image: fluent/fluentd-kubernetes-daemonset:v1.12.4-debian-elasticsearch7-1.0
Port: 24231/TCP
Host Port: 0/TCP
Command:
/bin/sh
-c
apt-get update
apt-get install -y build-essential libssl-dev libxml2-dev libxslt1-dev ruby-dev
gem install fluentd-ui
fluentd-ui setup
fluentd-ui start --daemonize
exec /fluentd/entrypoint.sh
... |
cs |
문제는 이렇게 컨테이너 시작시 많은 패키지를 설치하게 되면 파드의 시작시간이 느려집니다. 실제 환경에서는 위 패키지들을 포함한 상태로 새 이미지를 빌드하는게 맞겠지만, 테스트 환경이므로 이대로 진행합니다.
파드 시작 시간이 느려져 liveness 및 readiness prove에 응답을 못해 파드가 자꾸 리스타트하게 되므로 liveness 와 readiness prove의 period시간값도 늘려주도록 합니다. 기존 20초이던 period를 50초까지 늘려줘야 패키지 설치 중 리스타트를 방지할 수 있습니다.
|
1
2
3
4
|
...
Liveness: http-get http://:metrics/metrics delay=0s timeout=1s period=50s #success=1 #failure=4
Readiness: http-get http://:metrics/metrics delay=0s timeout=1s period=50s #success=1 #failure=4
...
|
cs |
마지막으로 elasticsearch로만 로그를 라우팅하던 기존의 컨피그를 수정해 fluentd-ui 에이전트로도 로그를 보내도록 하겠습니다. fluentd helm은 configmap 리소스를 이용해 컨피그 파일을 구성하고 있습니다. 컨피그맵 중 fluentd-config를 수정합니다.
|
1
|
kubectl edit cm fluentd-config -n es
|
cs |
컨피그 맵의 컨텐츠 중, 04_outputs.conf에 해당하는 부분을 아래와 같이 변경합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<label @OUTPUT>
<match **>
@type copy
<store>
@type forward
<secondary>
path /var/log/fluent/forward-failed
type file
</secondary>
<server>
host 127.0.0.1
port 24224
</server>
</store>
<store>
@type elasticsearch
host "elasticsearch-master"
include_timestamp true
</store>
</match>
</label>
|
cs |
@type으로 "copy"를 지정해 copy 플러그인으로 여러 대상에게 로그를 보낼 수 있도록 했습니다. 이를 통해 로그의 분기가 가능합니다. "foward" 타입 플러그인으로 지정한 호스트에 로그를 24224포트로 보내도록 지정합니다. 목적지는 fluentd-ui가 실행하는 fluentd 데몬입니다. 마지막으로 원래 라우팅 목적지였던 elasticsearch를 지정함으로써 fluentd 데몬과 elasticsearch 두 목적지로 로그가 분기되도록 구성합니다.
마지막으로 fluentd-ui 웹 인터페이스로 접근할 수 있도록 파드를 외부로 노출합니다.
|
1
|
kubectl port-forward FLUENTD_POD_NAME 9292 -n es
|
cs |
브라우져에서 localhost:9292로 접근 시 아래 화면을 볼 수 있습니다. admin:changeme로 로그인합니다.
Setup -> Create 순으로 진행하면 아래와 같은 웹 인터페이스를 볼 수 있습니다. 이 fluentd-ui에서는 크게 컨피그 파일 구성, 플러그인 관리, 로그 대쉬보드를 이용할 수 있습니다.

fluentd-ui 의 대쉬보드로 현재 처리하고 있는 로그들을 확인하기 위해 로그 파이프라인을 구성해보겠습니다. 좌측의 "Add Source and Output"으로 접근합니다.
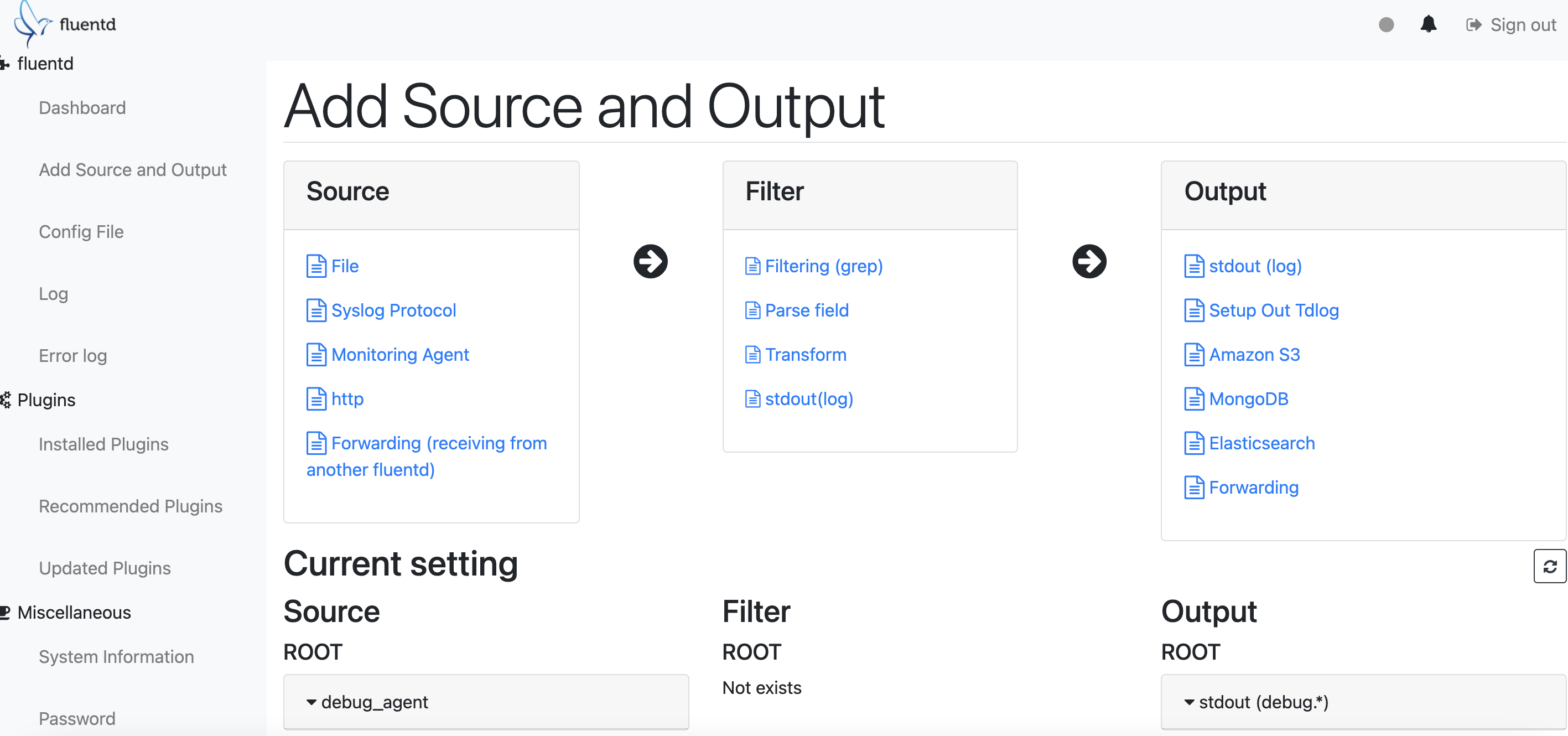
여기서 이전에 일일이 타이핑해서 구성하던 컨피그파일을 그래픽 인터페이스로 쉽게 구성할 수 있습니다. 컨피그 파일 구성이 익숙치 않은 분들은 여기서 구성하는 방법을 익히는 것도 좋아 보입니다. Source에 Forwarding, Filter에 stdout(log)를 추가해 컨피그 파일을 아래와 같이 구성합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<source>
# http://docs.fluentd.org/articles/in_forward
@type forward
port 24224
</source>
<source>
# http://docs.fluentd.org/articles/in_http
@type http
port 9880
</source>
<source>
@type monitor_agent
port 24220
</source>
<source>
@type debug_agent
port 24230
</source>
<match debug.*>
# http://docs.fluentd.org/articles/out_stdout
@type stdout
</match>
<filter>
@type stdout
</filter>
|
cs |
이후 파드를 재가동하면 아래와 같이 대쉬보드에 로그가 출력되는 것을 확인할 수 있습니다.
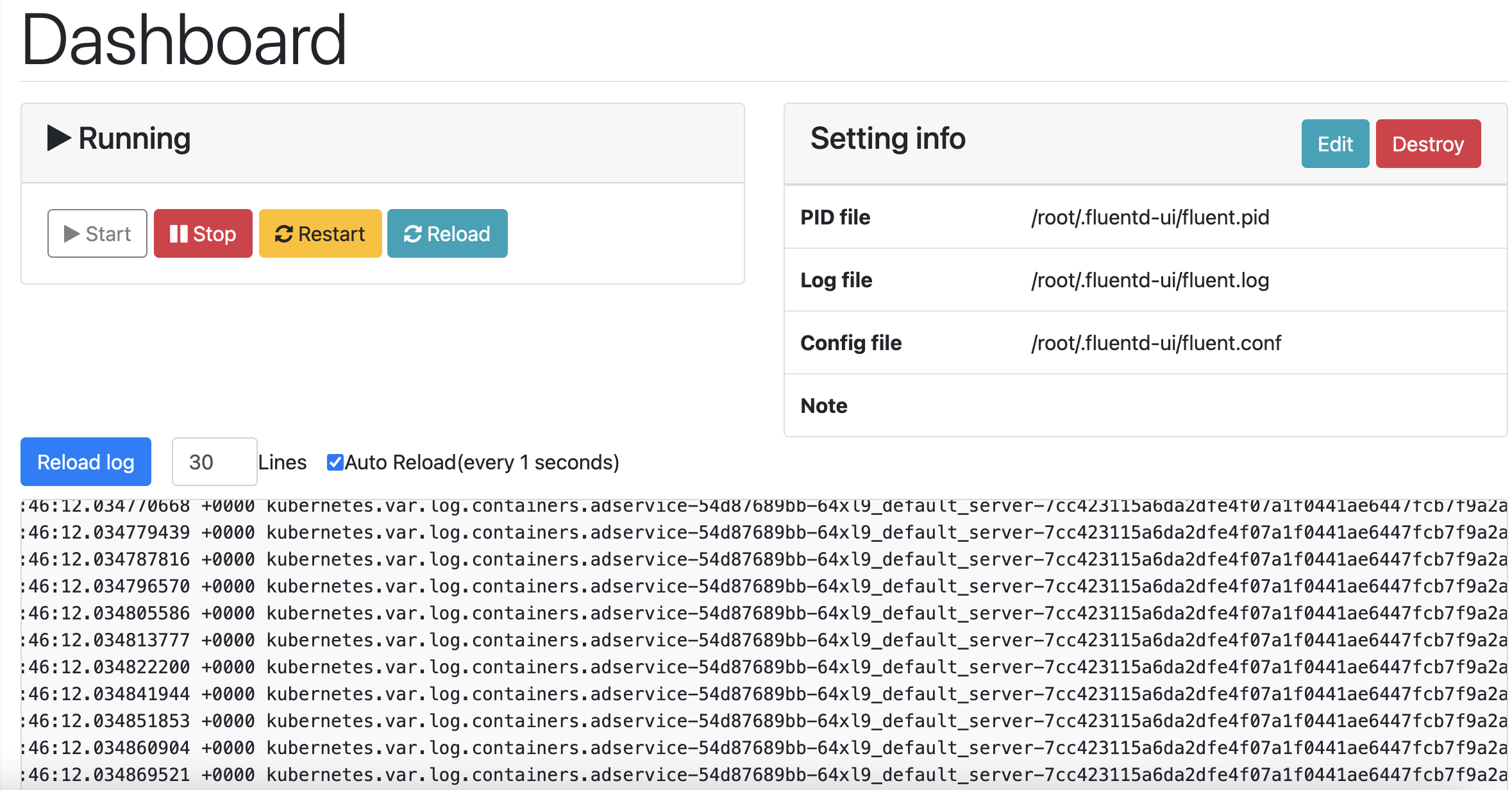
5. 마치며
이렇게 이번 포스팅에서 EFK 스택에 대해서 알아보고 구성해봤습니다.
EFK 스택은 마이크로 서비스 및 클라우드 내이티브 환경 최적화 로깅 툴인 Fluentd를 활용해 Kubernetes 환경의 로그를 효과적으로 수집하고 중앙화할 수 있었습니다.
fluentd는 logstash에 비해서 JVM이 필요하지 않아 매우 가볍고, 로그 수집 및 가공, 라우팅을 하나의 에이전트로 수행할 수 있었으며, 로그 파이프라인 구성이 비교적 쉽다는 장점이 있었습니다.
이번 포스팅을 읽는 분들도 fluentd를 이용한 EFK 스택 구성에 도움을 얻을 수 있기를 바랍니다.
'Observability' 카테고리의 다른 글
| Prometheus Operator를 사용해 Kubernetes 환경에서 Prometheus 구성하기 (8) | 2022.03.31 |
|---|---|
| 트레이싱 관측 도구 Grafana Tempo로 트레이스를 관측해보자 (0) | 2022.01.27 |
| 클라우드 리소스 Observability 확보 도구 Steampipe 사용기 + GCP IAM report 제작기 (0) | 2021.12.27 |
| Elasticsearch의 ELK Stack을 GKE Cluster에 구성해 GCP 관측 가능성 확보하기 (6) | 2021.12.12 |
| GKE Prometheus, Loki, Grafana로 Monitoring dashboard 구성하기(3) (0) | 2021.08.20 |