

Kubernetes의 장점 중 하나는 리소스의 유연하고 자동화된 Scaling이 가능하다는 것 입니다.
복잡한 MSA 아키텍쳐에서 리소스를 자동으로 Scaling해주는 기능이 있기 때문에 우리는 리소스 관리 및 사용 측면에서 Cluster를 매우 편리하게 사용할 수 있습니다
Kubernetes에서는 리소스를 Scaling할 수 있는 방법 중에서도 자동화된 방법, 즉 Autoscaling 기능을 제공하고 있는데요, Pod 단위에서는 HPA(Horizontal Pod Autoscaling), VPA(Vertical Pod Autocaling), Cluster 단위에서는 CA(Cluster Autoscaling)의 3가지 기능이 있습니다.
하지만 Google의 관리형 Kuberentes 서비스인 Google Kuberentes Engine, 즉 GKE에서는 위의 3가지 Autoscaling에 Advanced한 기능을 추가했으며 게다가 더 다양한 방법의 Autoscaling 기능까지 제공하고 있습니다.
이번 포스팅에서는 GKE에서 제공하는 Autoscaling 기능에는 무엇이 있는지, 어떻게 사용할 수 있는지 알아보도록 하겠습니다.
1. GKE의 5가지 Autoscaling 전략
현재 GKE는 총 5가지의 Autoscaling 기능을 제공하고 있습니다. 각 기능을 확장 단위 별로 살펴보겠습니다.
1-1. Pod 단위 - HPA(Horizontal Pod Autoscaling)

HPA는 CPU나 Memory와 같은 리소스 사용량 임계점에 다다를 시 Pod의 개수를 증가,혹은 감소시켜 수평적으로 리소스를 확장해주는 Autoscaling 기능입니다.
기본적으로 GKE뿐만 아니라 Kubernetes에서도 사용할 수 있는 Autoscaling 기능이지만, GKE에서 사용하는 HPA는 Pub/Sub 메세지, Google Monitoring 메트릭, Load balancer 트래픽과 같은 더 다양한 수치를 기준으로 임계점을 설정할 수 있다는 장점이 있습니다.
1-2. Pod 단위 - VPA(Vertical Pod Autoscaling)

VPA는 CPU나 Memory와 같은 리소스 사용량을 바탕으로 추천(recommend)해주거나 리소스 request를 자동으로 설정해 수직적으로 리소스를 확장해주는 Autoscaling 기능입니다.
기본 Kubernetes에는 add-on으로 제공되는 기능이며 GKE에서도 Automation feature 중 하나로 제공되어 사용할 수 있는 기능입니다.
GKE의 VPA는 기존 Kubernetes VPA에 비해 VPA를 관장하는 Deployment가 Managed Contolplane에서 관리된다는 점, CA(Cluster Autoscaler)와 연계되어 더 유기적인 Scaling이 가능하다는 점, VPA를 활성화하기 전의 과거 데이터까지 사용해 더 상세한 request 리소스를 추천해준다는 장점이 있습니다.
1-3. Pod 단위 - MPA(Multidimentional Pod Autoscaling)
MPA는 GKE에만 존재하는 특수한 Autoscaling 기능입니다. 이름이 뜻하는 것처럼 MPA는 수평적으로 확장하는 HPA와 수직적으로 확장하는 VPA의 전략을 혼합한 전략을 사용합니다.
MPA는 CPU를 기반으로는 수평적 확장을, Memory를 기반으로는 수직적 확장을 수행합니다. 이러한 전략은 HPA와 VPA를 동시에 사용할 수 없었던 한계를 넘게 해줍니다.
1-4. Cluster 단위 - CA(Cluster Autoscaling)
CA는 pod 단위로 확장했던 지금까지의 Autoscaling 기능과 달리 Cluster 단위로 확장하는 기능의 Autoscaling 전략입니다.
CA 기능을 사용하면 리소스 부족에 따른 Scheduling 실패 이벤트가 일어났을 시 노드를 자동으로 확장하며, 모든 Pod를 다른 Node로 옮겨도 될 만큼 충분할 만큼 리소스를 덜 사용하고 있을 시 노드를 자동으로 축소합니다.
특히 GKE는 1.22 버전 이후로는 CA에 Scale-to-zero 기능을 지원하기 때문에 사용하지 않는 유휴 클러스터는 노드 개수를 0개로 축소해 비용을 최대로 절감할 수 있는 효과를 볼 수 있습니다.
1-5. Node Pool 단위 - NPA (Node Auto Provisioing)

NPA는 Cluster 단위로 확장해 Node를 확장,축소했던 CA에서 더 나아가 Node들의 집합인 Node Pool 단위로 AutoScaling하는 전략입니다.
기존 CA의 전략은 Scaling하는 Node가 동일한 스펙이기 때문에 그 Node의 Capacity를 넘어서는 Pod가 Scheduling되면 아무리 Node의 개수를 확장한다고 해도 리소스가 부족한 상황에 처할 수 밖에 없다는 단점이 있었습니다.
NPA는 이러한 단점을 극복하기 위해 기존 Cluster가 감당할 수 없는 Resouce request의 pod Scheduling 요청이 있을 시 수직적으로 확장된 Node pool을 새로 생성하는 방법을 사용합니다.
이는 GKE에만 사용할 수 있는 Autoscaling 전략으로 CPU,Memory의 min,max 및 머신의 OS 등 새로 추가될 Node pool의 스펙을 자유롭게 지정할 수 있기 때문에 Node pool의 관리성 및 자율성 면에서 효과적인 기능입니다.
2. HPA(Horizontal Pod Autoscaling) of GKE
2-1. HPA 기본
GKE의 HPA는 별다른 설정 없이 기본적으로 사용할 수 있는 Autoscaling 기능입니다.
기본적으로 HPA는 CPU 혹은 Memory 리소스 사용량을 기준으로 Pod를 수평 확장합니다.
예시를 위해 nginx 컨테이너 기반의 Deployment를 생성합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
|
cs |
nginx pod에 접속하기 위한 Service를 생성하기 위해 아래와 같이 kubectl expose 명령어를 입력합니다.
|
1
2
3
4
5
|
kubectl expose deployment php-apache 8080
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.124.0.1 <none> 443/TCP 91d
php-apache ClusterIP 10.124.12.243 <none> 80/TCP 4s
|
cs |
이후 아래 매니페스트를 사용해서 nginx Deployment를 수평 확장하기 위한 HPA 오브젝트를 생성합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
|
cs |
주의할 점은 위와 같이 Autoscaling에 필요한 조건을 Utilization percentage으로 설정할 경우 Target이 될 Deplyoment는 꼭 Resources.requests를 지정해야 한다는 점입니다.
Utilization Percentage는 현재 Resource 사용량 / 지정한 Resource request 식으로 계산되기 때문입니다.
이제 Autoscaling의 테스트를 위한 부하 생성기를 배포해보겠습니다. 부하 생성기는 Kubernetes 기반으로 Distributed Load Testing Tool인 Locust를 사용하겠습니다.
https://github.com/mosesliao/kubernetes-locust
GitHub - mosesliao/kubernetes-locust: A demo how to use locust on EKS
A demo how to use locust on EKS. Contribute to mosesliao/kubernetes-locust development by creating an account on GitHub.
github.com
아래 명령어로 Locust 매니페스트가 존재하는 레포지토리를 clone하고 locust 네임스페이스를 생성한 뒤, 관련 매니페스트를 모두 배포합니다.
|
1
2
3
4
|
git clone https://github.com/mosesliao/kubernetes-locust.git
cd kubernetes-locust
kubectl create ns locust
kubectl apply -f ./ -n locust
|
cs |
배포를 성공적으로 실행하면 아래와 같이 locust-worker 및 locust-master Deployment가 생성됩니다.
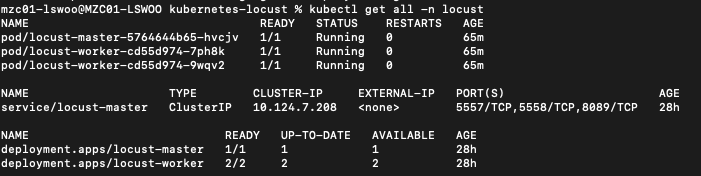
배포한 매니페스트 중 "script-cm"이라는 Configmap 오브젝트가 있는데, 파이썬 스크립트로 이루어진 locustfile.py 데이터 파일을 담고 있는 것을 볼 수 있습니다.
Locust는 "script-cm" 내의 파이썬 스크립트를 이용해서 테스트 시나리오를 구성하게 됩니다.
하지만 이번 포스팅에서 테스트할 웹 애플리케이션은 경로를 "/"만 가지는 단순한 앱이기 때문에, "/" 경로로만 트래픽을 보내도록 스크립트를 수정하겠습니다.
"script-cm" Configmap을 아래와 같이 수정합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
apiVersion: v1
data:
locustfile.py: |
import time
from locust import HttpUser, task
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")
kind: ConfigMap
metadata:
name: scripts-cm
namespace: locust
|
cs |
kubectl port-forward 명령어를 사용해 locust 웹 UI로 접속해보겠습니다.
|
1
2
3
4
|
kubectl port-forward -n locust svc/locust-master 8089:8089
Forwarding from 127.0.0.1:8089 -> 8089
Forwarding from [::1]:8089 -> 8089
|
cs |
웹 브라우저에서 localhost:8089로 접속했을 때 아래와 같은 페이지가 보이면 정상입니다.
Number of users와 Spawn rate를 통해서 테스트할 부하 정도를, Host 값을 통해서 부하를 주입할 목적지를 지정할 수 있습니다.

이제 HPA를 적용한 nginx Deployment에 부하를 주입하기 위해 적정값을 넣어보겠습니다. 아래와 같이 값을 넣고 Start swarming 버튼을 클릭합니다.
Numbers of users : 10000
Spawn rate : 10000
Host : http://php-apache.default.svc.cluster.local/
Locust가 Host 값 앞의 http://를 붙이지 않으면 "No scheme supplied"를 뱉습니다.
php-apache.default.svc.cluster.local은 SERVICE_NAME.NAMESPACE_NAME.svc.cluster.local 형식으로 이루어진 주소이며 다른 네임스페이스의 Service에 접근할때 사용해야 하는 주소값입니다.

부하 테스트를 시작하면 Locust가 해당 호스트에 부하를 주입하기 시작하며 통계 및 결과를 웹 UI에서 확인할 수 있습니다.
테스트가 실행되지 않고 Stopped에서 멈추면 locust-worker pod의 스펙을 올리는 것을 고려해야 합니다.
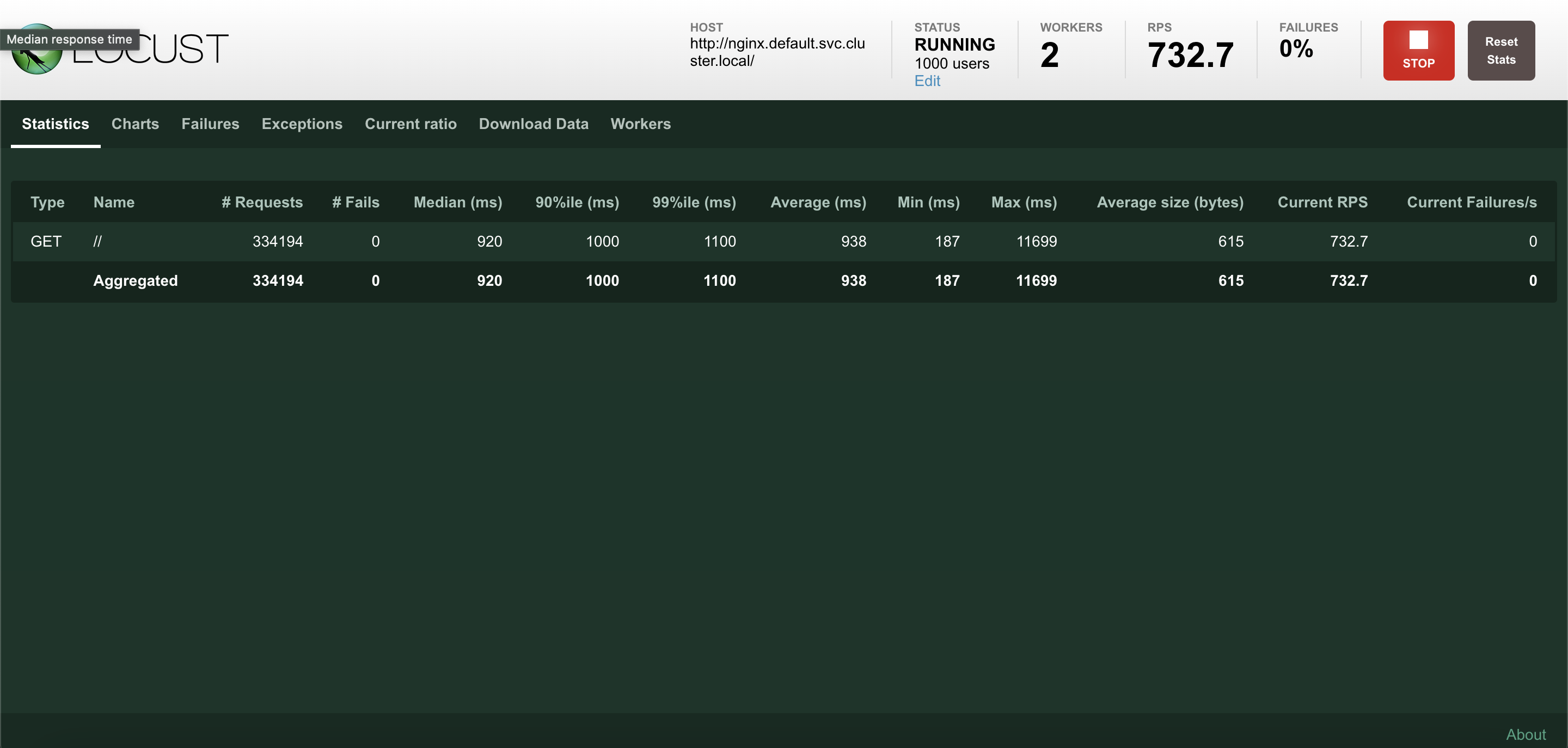
부하를 주입하고 kubectl get hpa 명령어를 입력하면 Scaling의 Target이 되는 수치와 현재 수치를 볼 수 있습니다.
현재 상황은 Target은 CPU Utilization이 50%인데 비해 실제 사용률이 243%이므로 확장이 Trigger되어야 합니다.

실제로 kubectl get pod 명령어로 pod 목록을 확인해보면 1개였던 pod가 최대 개수로 지정했던 10개까지 늘어나 있는 것을 확인할 수 있습니다.

이렇게 HPA는 CPU, 혹은 Memory와 같은 메트릭을 기준으로 Pod를 수평 확장할 수 있으며, 이 것이 가장 기본적인 HPA의 사용법입니다.
2-2. Cloud Monitoring External 메트릭을 기반으로 HPA 사용하기
GCP는 Cloud Monitoring이라는 메트릭 기반 Observability 서비스가 존재합니다.
그리고 이를 이용해서 GKE에서 Cloud Monitoring의 메트릭을 기반으로 HPA를 설정할 수 있습니다.
이로써 Pod를 CPU나 Memory가 아닌, Load Balancer의 Request count나, Pub/sub의 메세지 큐같은 더 세부적인 메트릭을 기반으로 확장할 수 있어 더욱 정교한 Autoscaling 전략을 사용할 수 있습니다.
이 전략을 사용하기 위해서는 우선 GKE에서 Cloud Monitoring의 메트릭을 받아올 수 있어야 합니다. 이를 위해 먼저 Stackdriver adapter를 Cluster에 배포해야 합니다.
GitHub - GoogleCloudPlatform/k8s-stackdriver
Contribute to GoogleCloudPlatform/k8s-stackdriver development by creating an account on GitHub.
github.com
Stackdriver adapter는 Kubernetes API에 Cloud monitoring을 백엔드로 하는 External metric API와 Custom metric API를 추가해줍니다.
다음 명령어로 Cluster에 Stackdriver adapter를 배포합니다.
|
1
2
|
wget https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml
kubectl apply -f ./adapter_new_resource_model.yaml
|
cs |
배포가 완료되면 다음과 같이 custom-metrics 네임스페이스에 Deployment와 Service가 생성되어 있는 것을 확인할 수 있습니다.
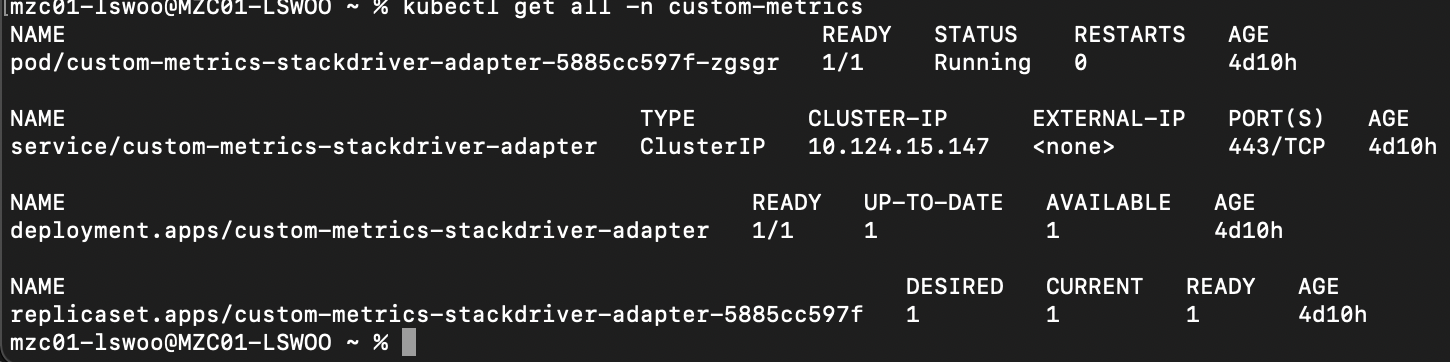
추가적으로 external.metrics... 와 custom.metrics.. 이름의 kubernetes API가 추가된 것도 확인할 수 있습니다.
이 API는 Cloud monitoring을 대상으로 메트릭을 Scraping해와 HPA 오브젝트의 Scaling을 Trigger하는데 사용됩니다.
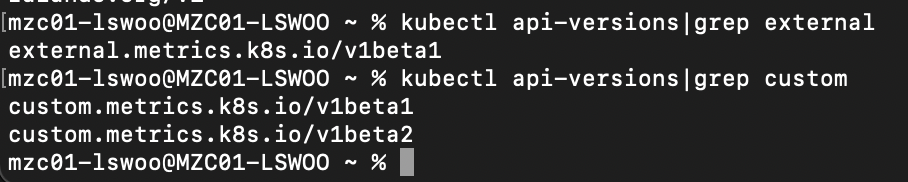
external.metric과 custom.metrics의 차이는 다음과 같습니다.
- external.metric : 기존에 존재하는 GCP 제공 Cloud monitoirng 메트릭을 Scraping합니다.
- custom.metric : 유저가 직접 Cloud monitoirng에 제공하는 Custom 메트릭을 Scraping합니다.
이번에는 GCP가 제공하는 기존의 메트릭인 external.metric API를 사용해서 HPA를 구성해보겠습니다. 정확히는 GCP의 TCP Load Balancer에 들어오는 Packet count 메트릭을 사용해 HPA를 생성해보겠습니다.
GCP의 TCP Load Balancer는 GKE에서 LoadBalancer 타입의 Service로 Pod를 노출할 시 생성됩니다. 따라서 기존의 Ipcluster 타입의 서비스를 지우고 LoadBalancer 타입의 Service로 Pod를 다시 노출시키겠습니다.
|
1
2
3
4
|
kubectl delete svc php-apache
service "php-apache" deleted
kubectl expose deployment php-apache --type LoadBalancer
service/php-apache exposed
|
cs |
아래와 같이 Kubernetes의 LoadBalancer 타입으로 Pod를 노출시킬 시,

GCP 콘솔에서 Google Cloud의 TCP Load Balancer 리소스가 생성되는 것을 확인할 수 있습니다.
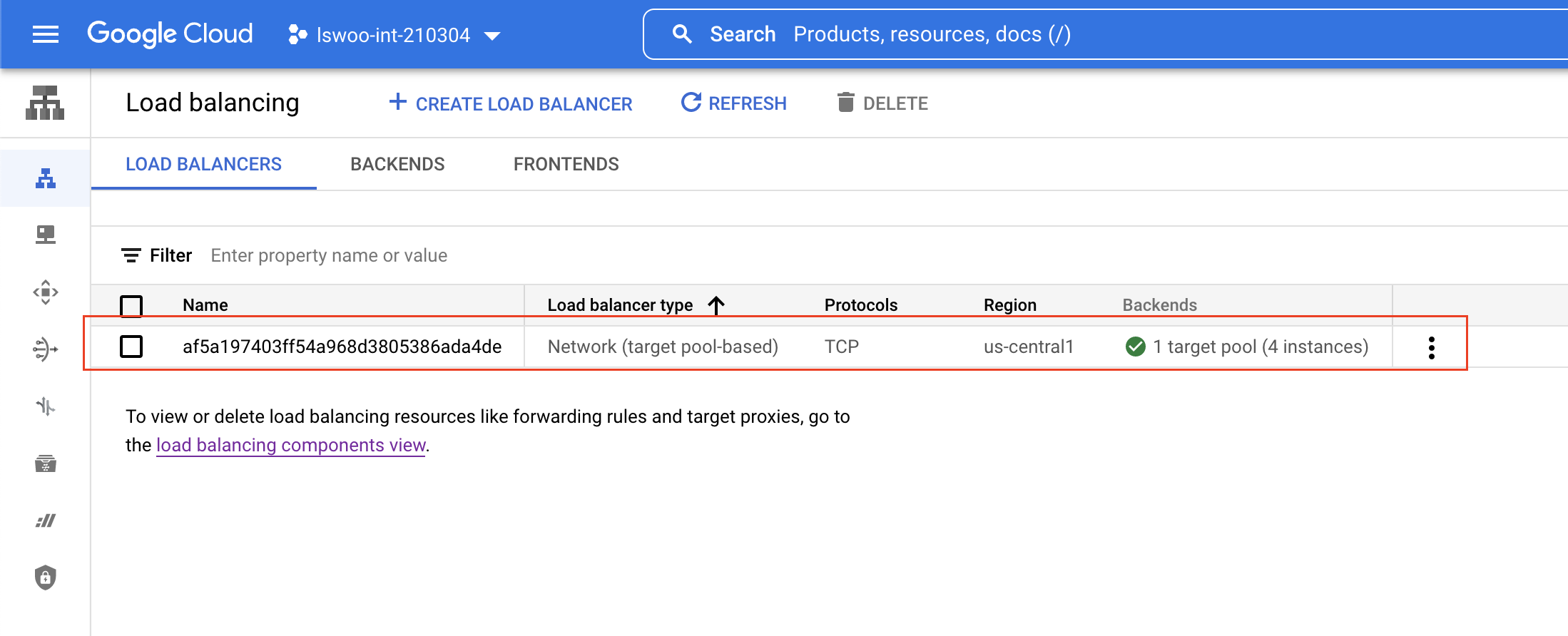
그리고 Cloud Monitoring에서 생성된 TCP Load Balancer과 관련된 메트릭들을 확인할 수 있으며, 여기서 확인할 수 있는 메트릭을 기반으로 External API를 사용해 HPA를 구성할 수 있습니다.
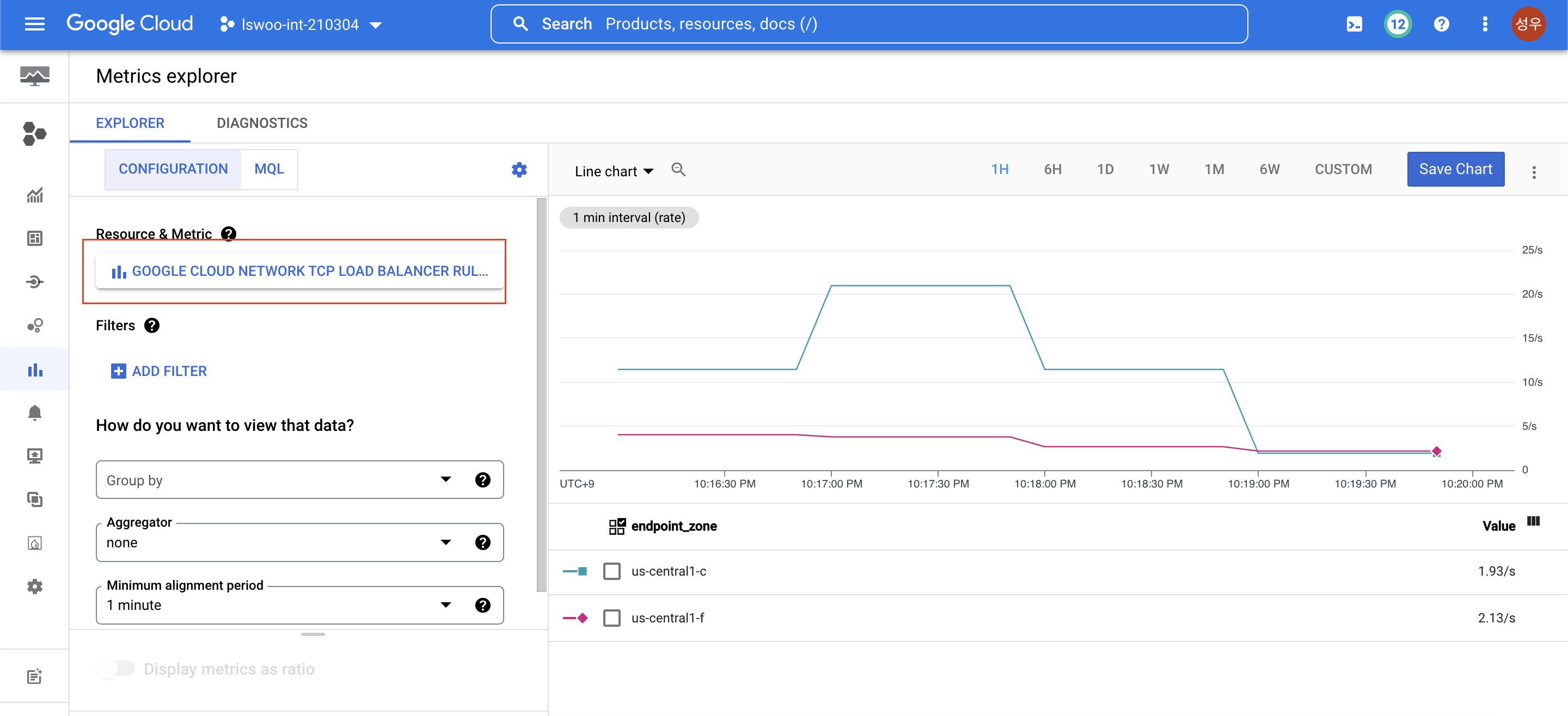
해당 메트릭을 사용하기 전에 메트릭의 정확한 이름을 알아보도록 하겠습니다.
Google Cloud Network TCP Load Balancer -> L3 -> Ingress packetes count 순으로 클릭하면 Metric 란에서 해당 메트릭의 정확한 이름이 아래와 같다는 것을 확인할 수 있습니다.
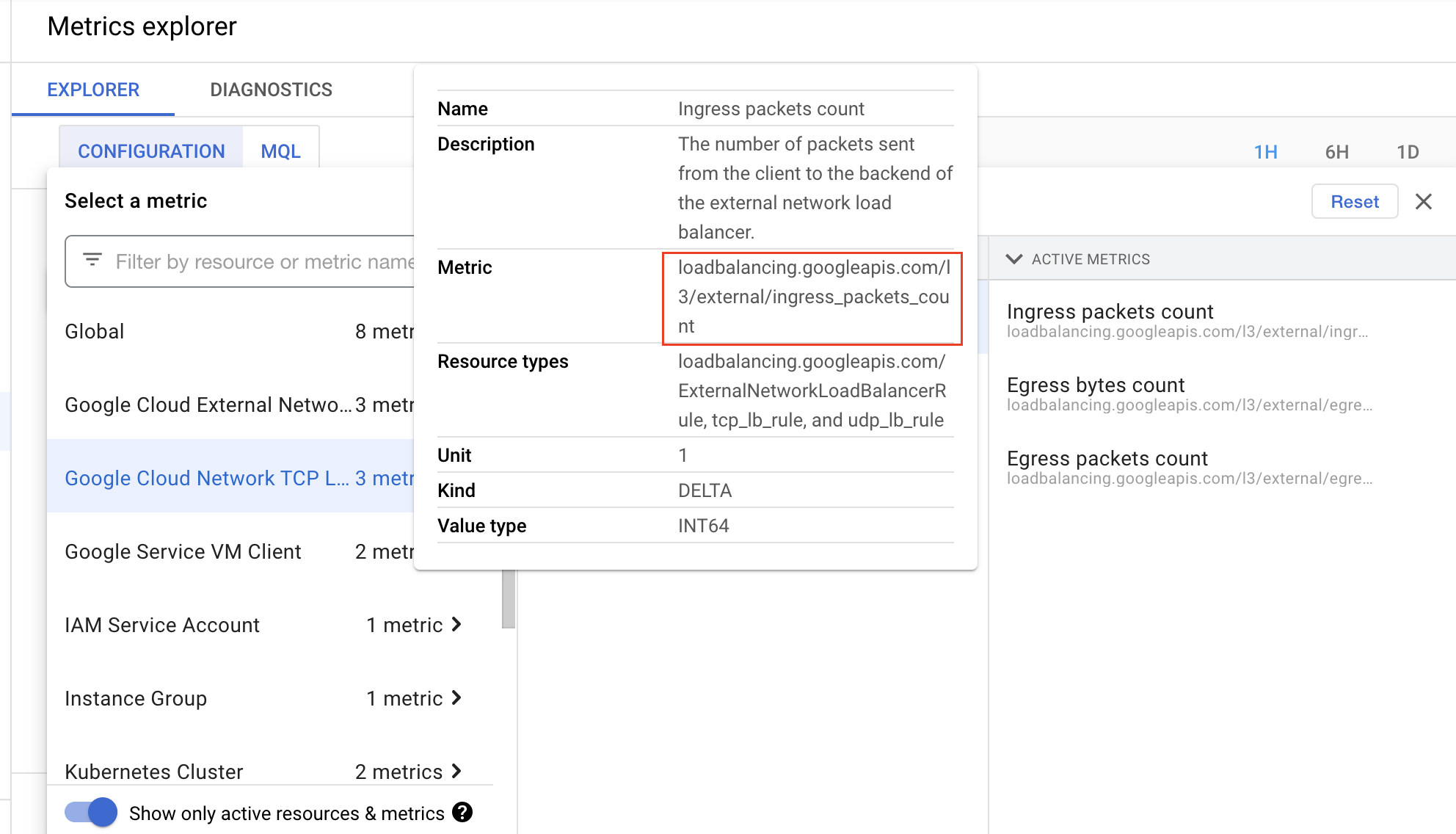
loadbalancing.googleapis.com/l3/external/ingress_packets_count
여기서 모든 "/" 구분자를 "|"로 바꿔보겠습니다.
loadbalancing.googleapis.com|l3|external|ingress_packets_count
이제 위 단계를 통해 얻은 이름을 아래 명령어와 같이 넣어서 실행해 보겠습니다.
|
1
|
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/loadbalancing.googleapis.com|l3|external|ingress_packets_count"|jq
|
cs |
정상적으로 실행되면 아래와 같이 external.metrics API를 통해 얻은 해당 메트릭의 상세한 결과값을 얻을 수 있습니다. 값이 나오지 않는다면 Load Balancer의 외부 IP주소로 몇 번 접속해 접속 메트릭을 생성해주면 됩니다.
이렇게 external 메트릭으로 HPA를 구성하기 전에 미리 해당 메트릭의 상세값을 확인해볼 수 있습니다.

이제 본격적으로 Cloud monitoring의 external metric을 사용해서 HPA를 구성해보겠습니다. 아래 매니페스트를 배포합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
app: nginx
name: nginx-hpa-external
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: External
external:
metric:
name: "loadbalancing.googleapis.com|l3|external|ingress_packets_count"
selector:
matchLabels:
resource.labels.backend_name: "af5a197403ff54a968d3805386ada4de"
target:
type: AverageValue
value: "300m"
|
cs |
위 매니페스트가 기존 hpa와 다른 점은 "spec.metrics.type" 속성에 "External" 값이 추가되었다는 점입니다. 이 값으로 metrics.external API를 사용해 Cloud monitoring에서 외부 메트릭을 Scraping할 수 있습니다.
"metrics.external.metric.name" 속성에는 위에서 미리 확인했던 메트릭 이름 값을 넣습니다.
"metrics.external.metric.selector" 속성에는 메트릭을 Scraping할 GCP 리소스, 즉 TCP Load Balancer를 지정합니다. 지정할 수 있는 Label 및 값은 위의 메트릭 상세값에서 확인할 수 있습니다.
"metrics.external.target.value" 속성은 Scaling을 Trigger할 임계값을 넣습니다. Cloud monitoring 콘솔에서 볼 수 있는 값으로느 정확한 값을 알기 힘드니 메트릭 상세값에서 확인하도록 합시다.

HPA 매니페스트를 배포한 뒤, Locust로 HPA의 임계점에 다다를때까지 웹 애플리케이션에 부하를 주입합니다. 이때 Host는 노출한 Load Balancer의 외부 IP로 지정합니다.

잠시 후 Load Balancer에 임계값 이상의 Packet이 유입되면 Pod가 수평 확장되는 것을 확인할 수 있습니다.
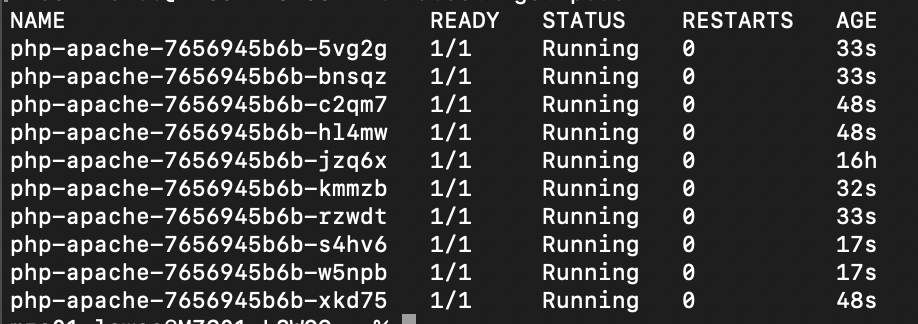
이렇게 GKE의 External API를 사용해서 Cloud monitoring의 메트릭을 기반으로 확장하는 HPA 오브젝트를 사용할 수 있었습니다.
이번 포스팅에서는 LoadBalancer 서비스로 노출한 TCP Load Balancer 메트릭을 기반으로 한 Packet 기반의 확장 전략을 사용했지만, Pub/sub의 메세지 큐, HTTP Load Balancer의 Request count 등 다양한 메트릭을 기반으로 한 확장 전략으로 응용할 여지가 무궁무진합니다.
2-3. Cloud Monitoring Custom 메트릭을 기반으로 HPA 사용하기
위에서는 external.metrics API를 사용해 기존 Cloud monitoring에 존재하는 메트릭을 기반으로 HPA를 구성했지만, 직접 제공하는 Custom metrics을 기반으로 HPA를 구성할 수도 있습니다.
Custom metrics을 Cloud monitoring으로 제공하고, Kubernetes는 그 메트릭을 custom.metrics API를 사용해 Scraping해와 HPA에 사용하는 순서입니다.
직접 구현해보기 위해 Custom metric을 Cloud montioring으로 보내는 이미지의 Deployment를 배포하겠습니다. 기존의 Deployment를 삭제하고 아래 매니페스트를 배포합니다.
배포하는 Deployment의 이미지는 "custom-metric"이라는 이름의 Custom metrics을 40의 값으로 계속 방출합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: custom-metric-sd
name: custom-metric-sd
namespace: default
spec:
replicas: 1
selector:
matchLabels:
run: custom-metric-sd
template:
metadata:
labels:
run: custom-metric-sd
spec:
containers:
- command: ["./sd-dummy-exporter"]
args:
- --use-new-resource-model=true
- --use-old-resource-model=false
- --metric-name=custom-metric
- --metric-value=40
- --pod-name=$(POD_NAME)
- --namespace=$(NAMESPACE)
image: us-docker.pkg.dev/google-samples/containers/gke/sd-dummy-exporter:v0.3.0
name: sd-dummy-exporter
resources:
requests:
cpu: 100m
env:
# save Kubernetes metadata as environment variables for use in metrics
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
|
cs |
배포한 이후 Cloud monitoring 콘솔의 Metrics explorer에서 Kubernetes pod -> Custom -> Custom metric 순으로 메트릭을 지정하면 아래와 같이 Custom Metric을 볼 수 있습니다.
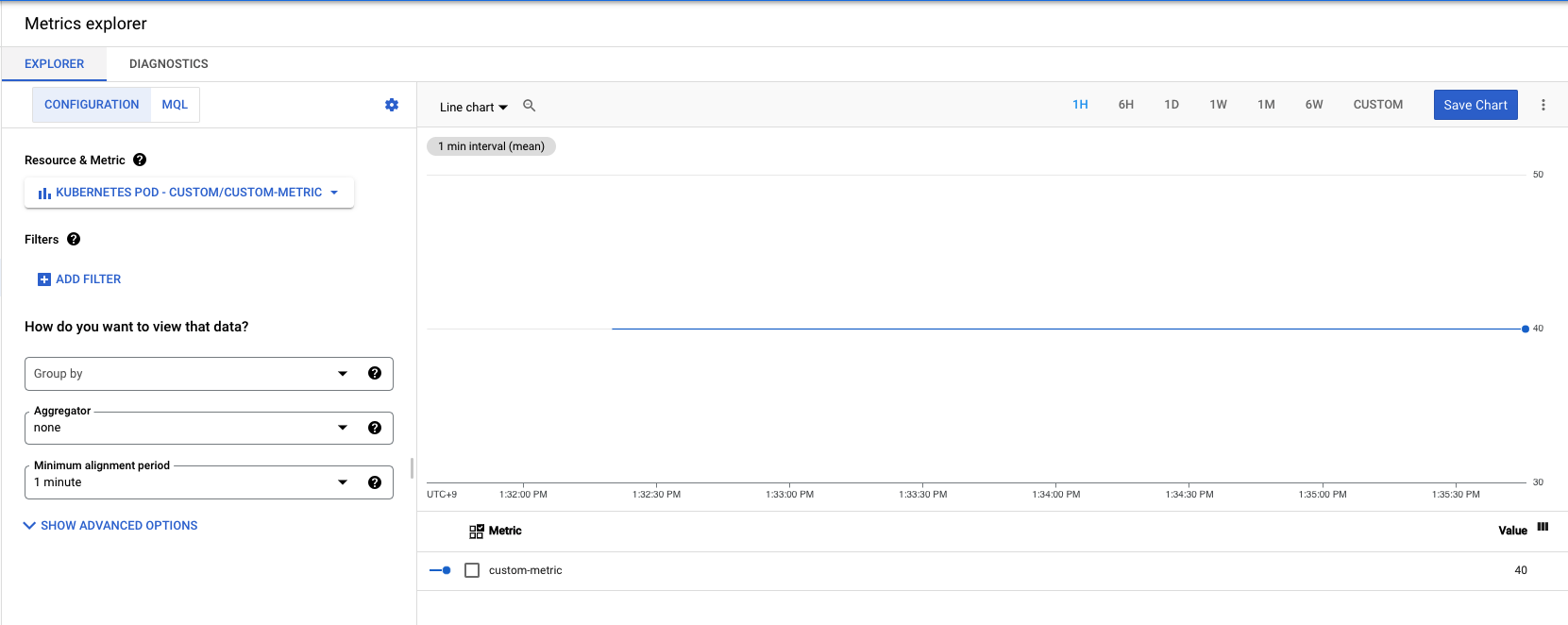
위 메트릭을 이용하는 HPA 매니페스트를 적용합니다.
매니페스트는 "custom-metric" 메트릭의 평균값이 20이면 Scaling을 Trigger합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: custom-metric-sd
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: custom-metric-sd
minReplicas: 1
maxReplicas: 5
metrics:
- type: Pods
pods:
metric:
name: custom-metric
target:
type: AverageValue
averageValue: 20
|
cs |
배포가 정상적으로 완료되었다면 아래와 같이 현재 값 40에 목표 값 20으로 Scaling이 Trigger되는 것을 확인할 수 있습니다.

Pod 개수도 최대 확장 개수인 5개까지 늘어난 것을 확인할 수 있습니다.
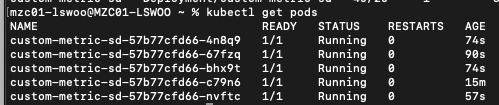
이렇게 custom.metrics API를 사용하여 Cloud monitoring에 직접 Custom metrics을 제공하여 이를 HPA의 구성에 사용할 수도 있습니다.
이를 사용하면 기존 메트릭에는 존재하지 않는 맞춤 메트릭을 기반으로 Scaling 전략을 사용할 수 있어 Pod Autoscaling의 자유도가 훨씬 높아집니다.
3. VPA(Vertical Pod Autoscaling) of GKE
3-1. VPA 기본
VPA는 Kubernetes에 기본적으로 제공되는 기능은 아닙니다. Vertical pod autoscaler를 설치해야만 사용할 수 있는 기능인데요.
Pod의 리소스 사용량을 분석한 뒤, 이를 수직적으로 확장(= 리소스 request를 늘려)하는 방식으로 동작하는 Autoscaling 전략입니다.
GKE에서는 따로 설치할 필요 없이 Automation 탭의 Vertical Pod Autoscaling 옵션을 Enabled하는 것으로 기능을 사용할 수 있습니다.
VPA를 사용하기 위해서는 아래 매니페스트를 배포합니다.
|
1
2
3
4
5
6
7
8
9
10
11
|
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: php-apache
updatePolicy:
updateMode: "Auto"
|
cs |
VPA는 관리하는 Deployment pod가 가져야 할 적정 리소스를 추천(recommendation)해주며 새 pod가 생성될때마다 추천하는 리소스를 요청하도록 제어하는 역할을 합니다.
그리고 사용량이 낮아지거나 높아질 경우, 그 임계점에 닿을 시 다시 적정 리소스를 계산해 추천하는 방식으로 pod를 수직 자동 확장하는 전략을 사용합니다.
아래의 Target이 추천 리소스 값을, Lower Bound와 Upper Bound가 각각 하향 임계점과 상향 임계점을 의미합니다.
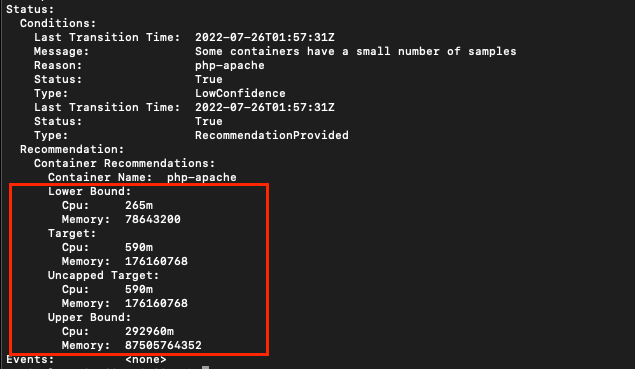
VPA가 관리하는 Deployment의 Pod를 살펴보면 기존의 리소스 Limit 및 Requests 값을 VPA가 추천한 값으로 덮어씌운 것을 확인할 수 있습니다.

VPA의 관리 대상인 Pod는 아래와 같이 annotation에 다음과 같은 키:밸류 값들이 붙게 됩니다.

VPA의 수직 확장 기능을 확인하기 위해 Locust로 Deployment에 부하를 주입해보겠습니다.
부하를 주입하고 몇 분 뒤 VPA를 확인하면 아래와 같이 리소스 추천 값이 상승한 것을 확인할 수 있습니다. 이와 같이 Pod가 상향 임계점에 도달하거나 OOM 에러가 발생했거나 하는 등의 VPA Scale up을 Trigger하는 이벤트가 발생하면 VPA는 추천 값을 다시 갱신합니다.

Deployment를 다시 rollout하면 pod가 갱신된 리소스 값으로 수직 확장되어 있습니다.

지금까지 본 것처럼 VPA는 Pod의 리소스를 추천해주는 전략을 사용해 자동으로 수직 확장을 해주는 오브젝트입니다.
그렇다면 GKE에서 사용하는 VPA는 기존 Kubernetes와는 어떤 점이 다른지 살펴보도록 하겠습니다.
3-2. GKE의 VPA
특히 GKE의 VPA는 기존 Kubernetes의 VPA에 비해 가지고 있는 장점들이 몇 가지 있습니다. Google Cloud 공식 문서에서 발췌했습니다.
- 추천 대상을 결정할 때 최대 노드 크기 및 리소스 할당량을 고려합니다.
- 클러스터 용량을 조정하도록 클러스터 자동 확장 처리에 알립니다.
- 이전 데이터를 사용하여 수직형 포드 자동 확장을 사용 설정하기 전에 수집된 측정항목을 제공합니다.
- 워커 노드에 배포하는 대신 수직형 pod 자동 확장 처리 pod를 제어 영역 프로세스로 실행합니다.
GKE의 VPA가 가진 장점들을 직접 확인해보도록 하겠습니다.
GKE의 VPA는 VPA를 사용하기 전에 이미 측정한 항목을 기준으로 리소스를 설정할 수 있습니다. 이러한 장점 덕분에 GKE의 VPA는 적정 리소스로 최적화하기를 기다릴필요 없이 바로 최적화된 리소스를 추천해준다는 이점이 있습니다.
이를 확인하기 위해 VPA를 배포하기 전에 웹 Deployment에 부하를 주입하겠습니다.
충분히 부하가 주입된 후, 해당 Deployment를 관리하는 VPA를 배포합니다.

이후 VPA를 살펴보면, VPA가 배포되기 이전의 데이터를 사용하여 리소스 값을 설정한 것을 볼 수 있습니다. 이렇게 GKE의 VPA는 기존 Kubernetes의 VPA와 달리 VPA를 배포하기 전의 데이터를 사용하여 적정 리소스로 Pod를 수직 확장할 수 있습니다.

다음으로 GKE의 VPA는 Vertical Pod Autoscaler 오브젝트를 워커 노드에 배포해야 하는 기존 Kubernetes와 달리 Google이 관리하는 Control plane에 존재하기 때문에 관리할 필요가 없습니다.
이를 확인해보기 위해 kube-system 네임스페이스의 pod 목록을 출력해보겠습니다.

현재 GKE 노드에는 Vertical pod Autoscaler를 위한 Pod가 배포되어 있지 않다는 것을 알 수 있습니다.
이로 인해 GKE는 사용자가 접근할 수 없는 Google managed Control plane에 Pod가 배포되어 있어 안전하고 관리할 필요 없는 VPA 사용 환경이라는 이점을 가지고 있습니다.
4. MPA(Multidimentional Pod Autoscaling) of GKE
4-1. GKE의 MPA
MPA는 GKE에서만 존재하는 새로운 개념의 Autoscaling 전략입니다. 기존의 HPA와 VPA가 각각 CPU와 Memory를 기준으로 수평적, 수직적인 확장만을 제공했다면 MPA는 이 두 확장을 동시에 제공함으로써 더 다차원적인 확장을 할 수 있도록 도와줍니다.
더 자세히 말하자면 MPA는 CPU를 기준으로는 수평적 확장을, Memory를 기준으로는 수직적 확장 전략을 사용합니다.
MPA를 사용하기 위해서는 우선 GKE의 Vertical Pod Autoscaling 기능을 활성화해야 하며, 1.19.4-gke.1700 버전 이후의 Cluster를 사용해야 합니다.
MPA를 사용하기 위해 아래와 같은 매니페스트를 배포합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
apiVersion: autoscaling.gke.io/v1beta1
kind: MultidimPodAutoscaler
metadata:
name: php-apache-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
goals:
metrics:
- type: Resource
resource:
# Define the target CPU utilization request here
name: cpu
target:
type: Utilization
averageUtilization: 60
constraints:
global:
minReplicas: 1
maxReplicas: 5
containerControlledResources: [ memory ]
container:
- name: '*'
# Define boundaries for the memory request here
requests:
minAllowed:
memory: 1Gi
maxAllowed:
memory: 2Gi
policy:
updateMode: Auto
|
cs |
MPA를 성공적으로 배포했다면 kubectl describe 명령어를 통해 해당 MPA의 자세한 설정을 볼 수 있습니다.
현재 배포한 MPA는 최소 1개에서 최대 5개의 Replica까지 확장하도록 되어 있으며, CPU 평균 사용률이 60%가 넘을시 수평적 확장을, Memory는 1Gi로 수직적 확장을 하도록 되어 있음을 알 수 있습니다.

MPA의 확장성을 확인하기 위해 Locust로 부하를 주입해보겠습니다.

부하가 주입된 후 CPU 사용률이 올라가자 수평적 확장이 일어나 Pod 개수가 늘어나는 것을 확인할 수 있었습니다.
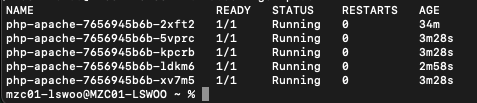
그와 동시에 새로 생성된 Pod들은 수직적 확장이 일어나 MPA에서 설정된 1Gi의 Memory로 설정된 것 또한 확인할 수 있었습니다.

기존의 Kubenetes의 Autoscaling 전략은 HPA와 VPA를 동시에 사용하는 것을 권장하지 않았습니다. 두 Scaling 전략이 서로의 Triggering을 방해하기 때문입니다. (아래 링크 참고)
https://stackoverflow.com/questions/64204970/can-vpa-and-hpaauto-scaling-in-kubernetes-used-together
can VPA and HPA(Auto Scaling) in kubernetes used together?
**can the following be done : ** VPA relies on a number of different measurements and is different from the HPA. We can therefore use VPA without interference in relation to the HPA. For a truly
stackoverflow.com
하지만 MPA를 사용하면 수평적 확장과 동시에 수직적 확장을 사용할 수 있어 어느 한 쪽의 확장 전략에만 얽메이지 않는 다차원적인 Scaling을 구사할 수 있어 훨씬 편리한 Autoscaling을 사용할 수 있다는 이점이 있습니다.
4. CA(Cluster Autoscaling) of GKE
4-1. GKE의 CA
지금까지의 Scaling이 Pod 단위에만 국한되어 있는 전략이었다면, Cluster Autoscaling은 그보다 더 높은 Cluster 단위에서 일어나는 Scaling 전략을 관장하는 기능입니다.
즉 CA는 Cluster 내부 Node들의 개수를 자동으로 늘리거나 줄임으로써 Cluster 자체의 Autoscaling을 구사한다고 볼 수 있는데요.
특히 Cloud 환경에서 Node의 추가란 곧 VM 인스턴스 리소스의 추가이므로 Cluster 단위의 Scaling은 pod단위보다도 Cost면에서 큰 영향을 끼치는 기능입니다.
따라서 CA를 구성하고 잘 사용하는 것이 GKE 클러스터의 운영 비용을 절감하는 데에도 큰 도움을 줄 수 있다는 것이겠죠.
이 CA 기능은 GKE 클러스터의 Node pool에서 Enable cluster autoscaler 옵션을 enable하는 것으로 활성화할 수 있습니다.
추가적으로 현재 Node pool에서 노드의 개수는 2개이며, 0개에서 5개까지의 노드를 가질 수 있다는 것을 확인할 수 있습니다.

CA를 활성화한뒤, 노드가 자동 확장되는 것을 확인하기 위해 현재 구성한 MPA의 max pod를 10개로 수정하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
apiVersion: autoscaling.gke.io/v1beta1
kind: MultidimPodAutoscaler
metadata:
name: php-apache-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
goals:
metrics:
- type: Resource
resource:
# Define the target CPU utilization request here
name: cpu
target:
type: Utilization
averageUtilization: 60
constraints:
global:
minReplicas: 1
maxReplicas: 10
containerControlledResources: [ memory ]
container:
- name: '*'
# Define boundaries for the memory request here
requests:
minAllowed:
memory: 1Gi
maxAllowed:
memory: 2Gi
policy:
updateMode: Auto
|
cs |
수정된 mpa를 다시 배포한 후, Locust로 동일한 Deployment에 부하를 주입합니다.
부하가 주입되면, pod가 10개까지 늘어나고 있는 것을 확인할 수 있습니다. 몇몇 pod는 pending 상태에 있는데, 이는 현재 pod를 할당할 Node가 없기 때문입니다.
CA는 Pending 상태에 빠진 Pod를 감지하면 Node를 확장하는 프로세스를 실행합니다.
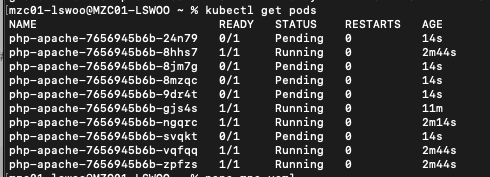
잠시후 kubectl get nodes 명령어를 통해 현재 노드의 개수를 확인해보면, 원래 2개였던 노드가 최대치인 5개까지 늘어나 있는 것을 확인할 수 있습니다.

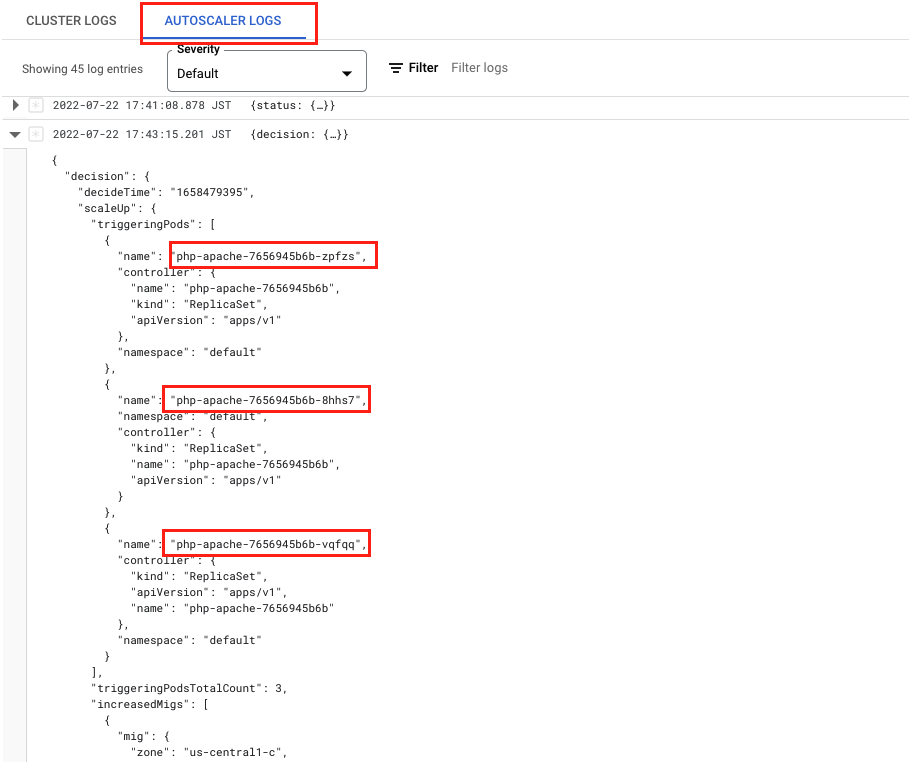
이러한 Scaling 기록은 GKE 웹 콘솔의 Autoscaler log에서 확인할 수 있습니다.
이 로그로 언제 어떤 pod가 CA를 Trigger해서 노드 카운트가 몇 개로 늘어났는지 확인할 수 있습니다.
아래 로그의 경우 부하를 주입한 php-apache Deployment의 pod가 노드 부족으로 인해 배포되지 못한 것이 CA를 Trigger했음을 알 수 있습니다.
반대로 부하 주입을 멈춰서 Cluster의 Scale down이 잘 일어나는지도 확인해보겠습니다. Locust를 멈춰 배포된 pod를 1개로 만들었습니다.

CA는 CPU와 Memory 사용률이 50% 밑으로 내려가거나, 노드에 할당된 Pod가 없거나 하는 등의 조건을 만족하는 경우 Scale down 이벤트를 Trigger합니다.
몇 분 뒤 노드를 확인해보면, 자동으로 노드가 최소 유지 개수인 2개로 줄어든 것을 확인할 수 있습니다.

이러한 Scale down 이벤트 또한 Autoscaler 로그에서 볼 수 있습니다.
로그에선 이벤트가 Trigger된 시간과 Scale down되면서 evict된 pod의 목록, 제거된 node의 정보를 확인할 수 있습니다.

CA는 Scale down을 Trigger할때 다양한 조건을 고려합니다. 자세한 Scale down 동작 원리를 알고 싶다면 아래 링크를 참고하시길 바랍니다.
GitHub - kubernetes/autoscaler: Autoscaling components for Kubernetes
Autoscaling components for Kubernetes. Contribute to kubernetes/autoscaler development by creating an account on GitHub.
github.com
5. NAP(Node AutoProvisioning) of GKE
5-1. GKE의 NAP
Node AutoProvisioning(이하 NAP)은 GKE에서만 제공하는 독특한 방식의 Scaling 기능입니다.
NAP은 노드 단위로 Scaling한다는 점에서 CA와 같지만, 단순히 노드 뿐만이 아닌 노드의 집합인 노드 풀 단위로 Scaling한다는 점이 CA와는 차별되는 점입니다.
노드 풀 단위로 Scaling되기 때문에 NAP을 사용해서 추가되는 노드는 기존 노드들과 같은 스펙으로 추가되는 것이 아니라, 더 높은 스펙으로도 추가될 수 있어 유연한 노드 Scaling을 가능케 합니다.
그래서 기존 노드 스펙보다 더 높은 리소스를 요구하는 Pod가 Scheduling되었을 때에도 NAP은 기존과 같은 스펙의 노드를 추가해 Pending상태를 유발하는 것이 아니라, 더 높은 스펙의 노드를 Provisioning할 수 있어 기존 CA의 문제점을 해결한 Scaling전략이라고 할 수 있습니다.
예를 들기 위해 기존에 배포한 deployment의 리소스 요청량을 아래와 같이 변경했습니다.
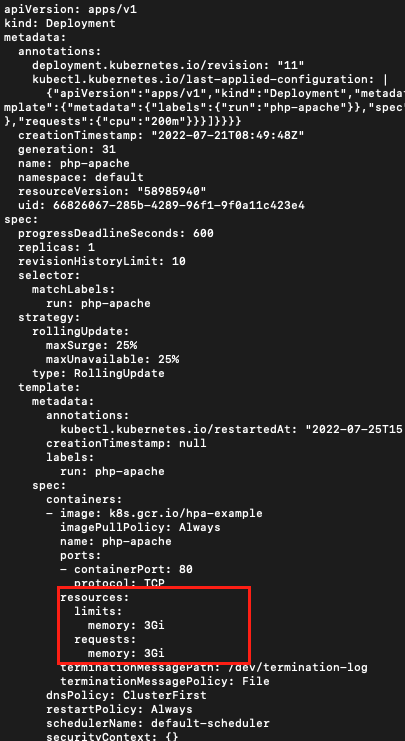
그리고 pod를 다시 배포하면 아래와 같은 event 메세지를 출력하며 pending 상태에 빠지는 것을 볼 수 있습니다.
현재 노드에는 pod의 리소스 요청량을 수용할 수 있는 노드가 없으며, 노드를 Scale-up 한다해도 이를 충족할 수 없으니 CA의 Scaling도 Trigger되지 않고 있는 것입니다.
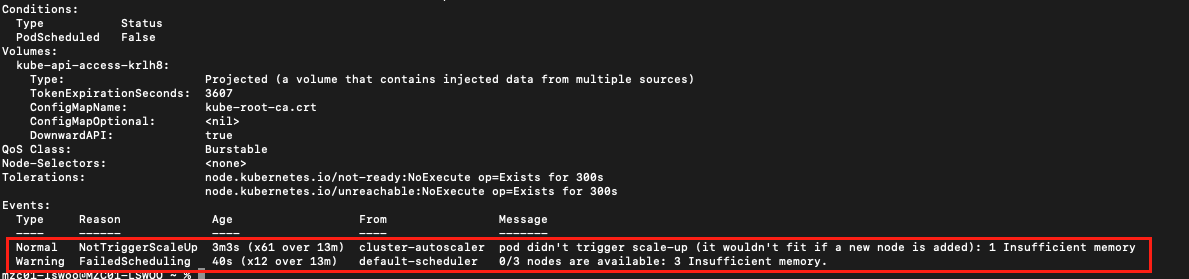
이같이 pod가 노드의 스펙보다 더 높은 리소스를 요청하면 CA가 활성화되어 있더라도 Scaling 전략이 무효화될 수 있다는 것을 확인했습니다.
하지만 GKE의 NAP은 새로운 노드 풀을 생성해 더 높은 스펙의 노드를 Provisioning하는 것으로 이러한 문제를 해결할 수 있습니다.
NAP은 GKE의 Automation 탭에서 활성화할 수 있습니다. 활성화하기 위해 옆의 연필 버튼을 누르면 자세한 설정을 할 수 있습니다.

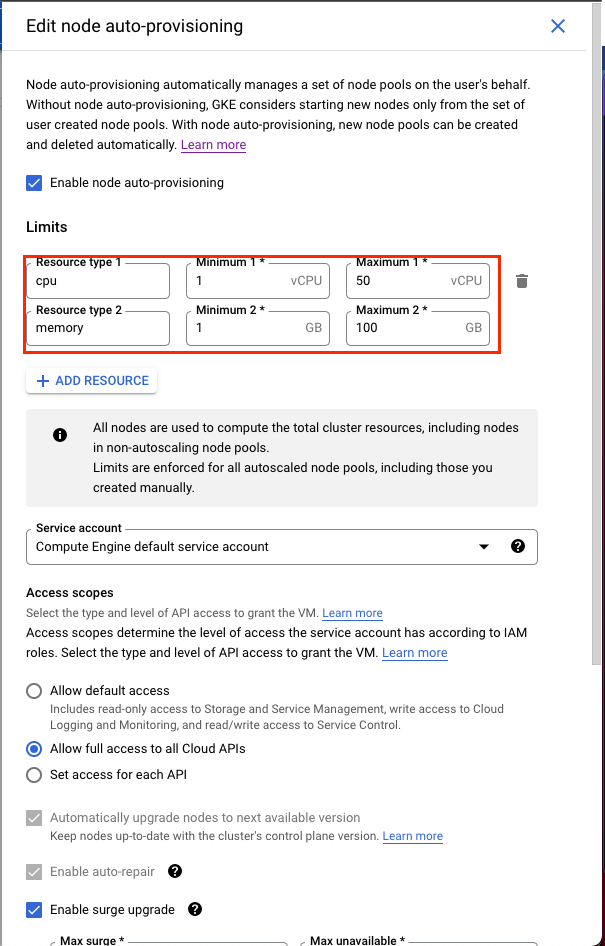
NAP을 활성화하면 Provisioning할 수 있는 노드의 스펙 min, max 및 Service account, 권한 등 인스턴스와 관련한 다양한 설정을 할 수 있습니다.
maximum cpu를 50, memory를 100으로 설정하고 설정을 저장하겠습니다. 여기서 지정하는 Resource Limits는 auto-provisioning된 노드 풀의 리소스 한계 뿐만이 아닌, 클러스터 전체의 한계를 지정하는 것임을 주의해야 합니다.
NAP 기능을 활성화하면 기존과 다른 이름의 노드가 하나 늘어나 있는 것을 확인할 수 있습니다.

콘솔에서 확인해보면, 기존과는 다른 노드 풀이 하나 추가되어 있는 것을 볼 수 있으며 이 노드 풀의 노드는 NAP Scaling을 Trigger한 pod의 리소스를 충족할 수 있는 스펙으로 상향되어 생성된 것 또한 확인할 수 있습니다.

이렇게 기존보다 높은 스펙의 노드가 추가됨으로써 Pod가 성공적으로 Scheduling될 수 있었습니다.

NAP 기능에 대한 설정은 웹 콘솔에서 뿐만이 아닌 CLI 명령어로도 가능한데요. 특히 명령어에서 Config 파일을 제공하는 방식으로 웹 콘솔에서는 사용할 수 없었던 고급 구성을 사용할 수 있습니다.
아래 yaml 매니페스트를 생성합니다.
|
1
2
3
4
5
6
7
8
9
|
shieldedInstanceConfig:
enableSecureBoot: true
enableIntegrityMonitoring: true
management:
autoRepair: true
autoUpgrade: true
diskSizeGb: 10
diskType: pd-ssd
imageType: 'cos_containerd'
|
cs |
- shieldedInstanceConfig : 생성될 노드에 보안 부팅 및 무결성 모니터링 기능을 사용합니다. 해당 기능에 대한 자세한 내용은 아래 링크를 참고하세요.
https://cloud.google.com/kubernetes-engine/docs/how-to/shielded-gke-nodes?hl=ko#node_integrity - management : 생성될 노드의 autorepair 및 autoupgrade 기능을 사용합니다.
- diskSizeGb : 생성될 노드가 가질 디스크의 크기를 지정합니다.
- diskType : 생성될 노드가 가질 디스크의 타입을 지정합니다. pd-balanced(default), pd-standard, pd-ssd를 지정할 수 있습니다.
- imageType: 생성될 노드가 가질 이미지의 타입을 지정합니다. cos_containerd 혹은 ubuntu_containerd를 지정할 수 있습니다.
아래 명령어를 통해 yaml 파일을 적용할 수 있습니다.
|
1
2
3
4
|
gcloud container clusters update CLUSTER_NAME \
--enable-autoprovisioning \
--autoprovisioning-config-file FILE_NAME
|
cs |
성공적으로 적용시 아래와 같은 메세지를 볼 수 있습니다. 이제 yaml에 정의했던 기능을 활성화한 채로 NAP을 사용할 수 있습니다.

지금까지 본 것처럼, NAP은 노드가 아닌 노드 풀 단위로 Scaling함으로써 기존 CA가 가지는 한계를 극복할 수 있게 해주는 Scaling 기능입니다.
현재 NAP은 Provisioning하는 노드 풀에 cpu, memory 말고도 gpu와 같은 추가적인 리소스를 사용할 수도 있으며, Autoscaling profile을 이용해 노드의 downscale 전략을 바꿀 수도 있습니다.
GKE에서만 사용할 수 있는 NAP을 사용한다면 더 유연한 클러스터 Scaling 전략을 사용할 수 있을 것입니다.
+) Schedule based Scaling
Schedule based Scaling on GKE
Autoscaling으로 모든 리소스 문제가 해결되면 좋겠지만, 실제 문제는 그렇지 않은 경우가 많습니다.
간혹 급격한 리소스 요구의 증가는 어떤 Autoscaling 전략을 사용해도 요구사항을 충족하기 어려운 경우도 존재합니다.
대부분 이런 경우에는 예상할 수 있는 대량의 리소스 증가 이벤트가 있는 경우가 많은데요.
이러한 상황에는 Autoscaling에 의존하는 대신 Schedule-based Scaling 전략을 사용하는 것이 옳습니다.
Schedule-based Scaling은 리소스 사용량 대신 특정 시간, 혹은 시간대를 Trigger로 사용하는 Scaling 전략으로 리소스 확장이 필요한 시간대를 알고 있을 경우 효과적인 전략입니다.
GKE는 같은 GCP의 서비스인 Cloud Scheduler로 Schedule-based Scaling 전략을 사용할 수 있습니다.
Cloud Scheduler는 웹 콘솔 우측 상단의 내비게이션 바 메뉴에서 Application integration 탭을 클릭하면 사용할 수 있습니다.
Cloud Scheduler -> Create job 버튼을 클릭해 새로운 Job을 생성합니다.
Create a job 페이지에서 다음과 같이 작성합니다.
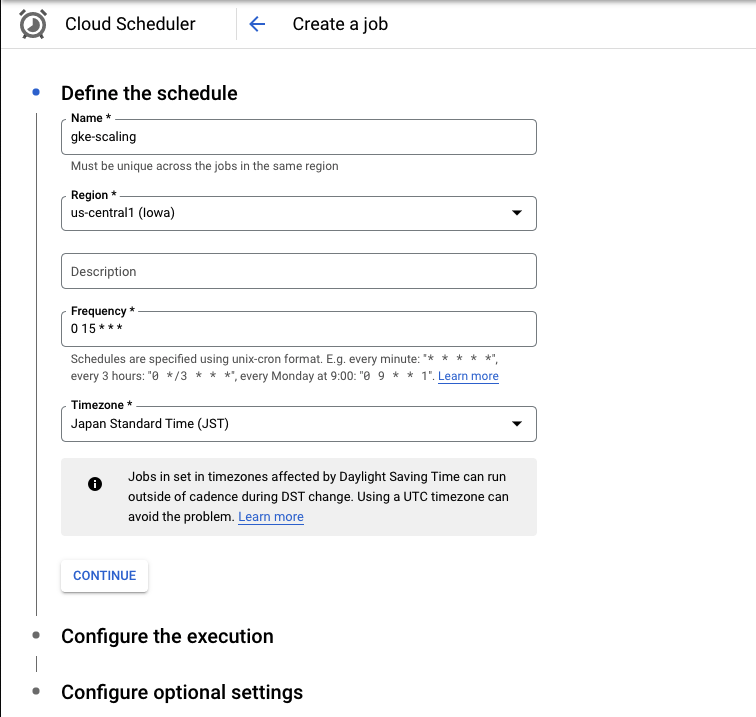
Name : Scheduler job의 이름을 지정합니다.
Region : Job을 실행할 Region을 지정합니다.
Frequency: Job을 실행할 Schedule을 unix-cron 포맷으로 지정합니다. 아래 링크의 cron 에디터를 활용할 수 있습니다.
https://crontab.cronhub.io/
Timezone: 시간대를 선택합니다. 한국 시간대를 사용하고자 한다면 JST를 선택합니다.
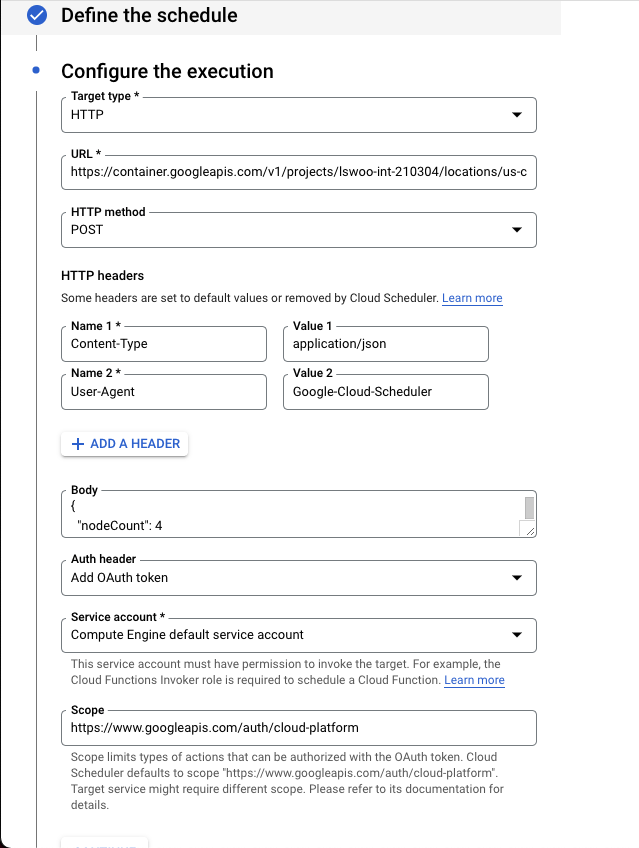
Target type : HTTP를 선택합니다.
URL : 아래 URL에 적절한 값을 치환해 넣습니다.
https://container.googleapis.com/v1/projects/PROJECT_NAME/locations/ZONE/clusters/CLUSTER_NAME/nodePools/POOL_NAME:setSize
HTTP method : POST를 선택합니다.
HTTP headers : Content-Type : application/json , User-Agent : Google-Cloud-Scheduler 값을 넣습니다.
body : 아래 nodeCount 값에 늘리고자 하는 노드 수 값을 넣습니다.
{
"nodeCount": 4
}
Auth header : Add OAuth token을 선택합니다.
Service account : GKE 클러스터의 노드 수를 설정할 수 있는 권한을 지닌 Service account를 선택합니다.
이후 Create 버튼을 클릭하면 아래와 같이 Job 리스트에 생성한 Job이 등록된 것을 확인할 수 있습니다.
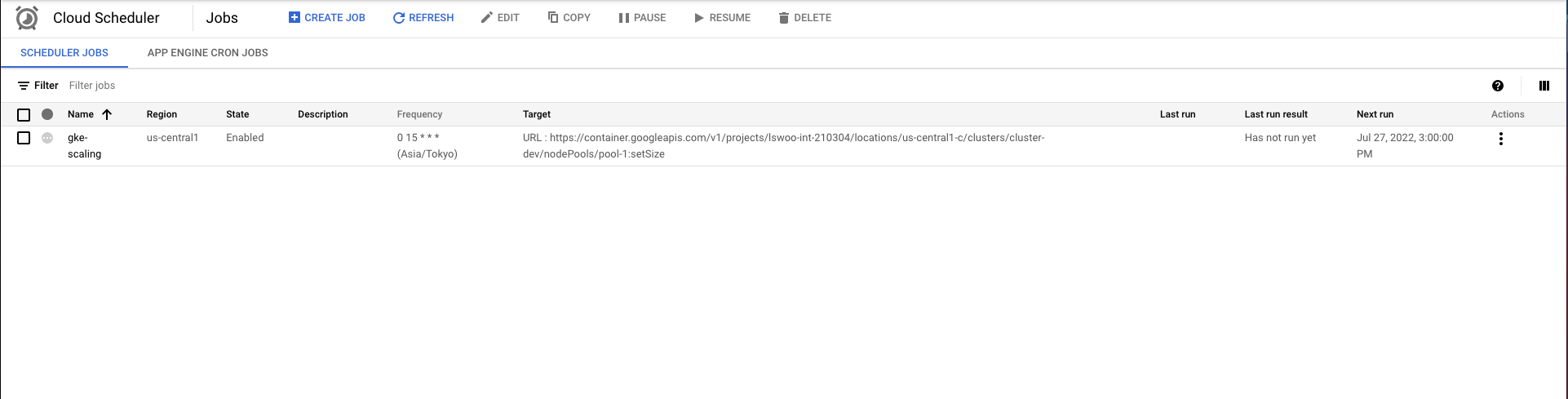
이제 Cloud Scheduler는 매일 15시에 GKE 클러스터의 노드 개수를 4개로 조정할 것입니다.
오른쪽 Action 버튼을 클릭한 뒤 Force a job run 버튼을 클릭하면 일정까지 기다리지 않아도 Job을 실행해볼 수 있습니다.

Force a job run 버튼을 클릭해 Job을 실행하자 지정한 node pool의 노드가 4개로 늘어난 것을 확인할 수 있었습니다.

이렇게 Schedule-based Scaling 전략을 사용함으로써 리소스 사용량에만 의존하는 것이 아니라, 일정 기반으로 미리 다가올 리소스 증에 대비할 수 있습니다.
7. 마무리
지금까지 GKE에서 사용할 수 있는 5가지 Scaling 전략을 알아봤습니다.
GKE에서는 Pod단위의 HPA, VPA, MPA, Cluster 단위의 CA, Node pool 단위의 NAP을 사용할 수 있었는데요.
기존에 존재하는 HPA, VPA, CA같은 Scaling 전략들에 GKE에서만 제공하는 기능이 추가되어 있는 것은 물론, GKE가 단독으로 제공하는 MPA, NAP같은 기능들이 있다는 것도 알 수 있었습니다.
추가적으로 리소스 사용량 기반의 Autoscaling 전략이 아닌, 일정 기반의 Schedule-based Scaling 전략을 사용하는 방법에 대해서도 알아봤습니다.
이 모든 Scaling 전략들을 단편적으로 사용하는 것이 아닌, 적절하게 혼합해서 사용하는 것이 GKE 클러스터를 더욱 유연하게 사용할 수 있는 방법이 될 것입니다.
이번 포스팅을 보는 분들이 GKE를 사용하시면서 Autoscaling에 대한 인사이트를 얻어가셨기를 바랍니다.